### What is this PR for?
Change title of tutorial notes so all of them can be placed under one folder.
### What type of PR is it?
Documentation
### Screenshots (if appropriate)
Before
<img width="418" alt="screen shot 2016-11-17 at 4 01 45 pm" src="https://cloud.githubusercontent.com/assets/8503346/20394292/4d2a9060-acdf-11e6-92c6-8274134a799d.png">
After
<img width="366" alt="screen shot 2016-11-18 at 5 34 30 pm" src="https://cloud.githubusercontent.com/assets/8503346/20437718/4fc128bc-adb5-11e6-969f-0a23ac45f1e8.png">
### Questions:
* Does the licenses files need update? no
* Is there breaking changes for older versions? no
* Does this needs documentation? no
Author: Mina Lee <minalee@apache.org>
Closes#1652 from minahlee/tutorial_folder and squashes the following commits:
1039ae5 [Mina Lee] Change note names to be more specific
171d946 [Mina Lee] Move tutorial notes under folder
### What is this PR for?
This PR adds Mahout functionality for the Spark Interpreter.
### What type of PR is it?
Improvement
### Todos
- [x] Implement Mahout Interpreter in Spark
- [x] Add Unit Tests
- [x] Add Documentation
- [x] Add Example Notebook
### What is the Jira issue?
https://issues.apache.org/jira/browse/ZEPPELIN-116
### How should this be tested?
Open a Spark Notebook with Mahout enabled and run a few simple commands using the R-Like DSL and Spark Distributed Context (Mahout Specific)
### Screenshots (if appropriate)
### Questions:
- Does the licenses files need update?
No
- Is there breaking changes for older versions?
No
- Does this needs documentation?
Yes
Author: rawkintrevo <trevor.d.grant@gmail.com>
Closes#928 from rawkintrevo/mahout-terp and squashes the following commits:
ed6eff0 [rawkintrevo] [ZEPPELIN-116] renamed add_mahout_interpreters.py and overwrite_existing feature
e7d4e12 [rawkintrevo] [ZEPPELIN-116] Made add_mahout.py script more resilient
7e83832 [rawkintrevo] [ZEPPELIN-116] Add Mahout Interpreters
### What is this PR for?
This PR is the first of two major steps needed to improve matplotlib integration in Zeppelin (ZEPPELIN-1344). The latter, which is a plotting backend with fully interactive tools enabled, will be done afterwards in a separate PR. This PR specifically for automatically displaying output from calls to matplotlib plotting functions inline with each paragraph. Thanks to the addition of post-execute hooks (ZEPPELIN-1423), there is no need to call any `show()` function to display an inline plot, just like in Jupyter.
### What type of PR is it?
Improvement
### Todos
The main code has been written and anyone who reads this is encouraged to test it, but there are a few minor todos:
- [x] - Add unit tests
- [x] - Add documentation
- [x] - Add screenshot showing iterative plotting with angular mode
### What is the Jira issue?
[ZEPPELIN-1345](https://issues.apache.org/jira/browse/ZEPPELIN-1345)
### How should this be tested?
In a pyspark or python paragraph, enter and run
``` python
import matplotlib.pyplot as plt
plt.plot([1, 2, 3])
```
The plot should be displayed automatically without calling any `show()` function whatsoever. A special method called `configure_mpl()` can also be used to modify the inline plotting behavior. For example,
``` python
z.configure_mpl(close=False, angular=True)
plt.plot([1, 2, 3])
```
allows for iterative updates to the plot provided you have PY4J installed for your python installation (which of course is always the case if you use pypsark). To clarify, this feature only currently works with pyspark (not python as there are no `angularBind()` and `angularUnbind()` methods yet). Doing something like:
```
plt.plot([3, 2, 1])
```
will update the plot that was generated by the previous paragraph by leveraging Zeppelin's Angular Display System. However, by setting `close=False`, matplotlib will no longer automatically close figures so it is now up to the user to explicitly close each figure instance they create. There's quite a bit more options for `z.configure_mpl()`, but I will save that discussion for the documentation.
### Screenshots (if appropriate)

### Questions:
- Does the licenses files need update? No
- Is there breaking changes for older versions? No
- Does this needs documentation? Yes
Author: Alex Goodman <agoodm@users.noreply.github.com>
Closes#1534 from agoodm/ZEPPELIN-1345 and squashes the following commits:
9ef6ff7 [Alex Goodman] Move mpl backend files to /interpreter
24f89c6 [Alex Goodman] Catch potential NullPointerExceptions from hook registry
bdb584e [Alex Goodman] Make sure expressions are printed when no plots are shown
22b6fe4 [Alex Goodman] Remove unused variable
d3d1aa0 [Alex Goodman] Fix CI test failure
c90d204 [Alex Goodman] Update spark.md
bcf0bf3 [Alex Goodman] Update python.md for new matplotlib integration
c9b65a5 [Alex Goodman] Add iterative plotting example image
8029a05 [Alex Goodman] Update python/README.md
f2d9e86 [Alex Goodman] Exclude tests are excluded in python/pom.xml
86b1c90 [Alex Goodman] Fix tutorial notebook not loading
c37b00f [Alex Goodman] Fix legend in tutorial notebook
a321d79 [Alex Goodman] Update python.md
82350e3 [Alex Goodman] Update matplotlib tutorial notebook
9792f97 [Alex Goodman] Add unit tests
8b9b973 [Alex Goodman] Fix NullPointerExceptions in unit tests
82135ad [Alex Goodman] Removed unused variable
f9c9498 [Alex Goodman] Added support for Angular Display System
edf750a [Alex Goodman] Add new matplotlib backend for python/pyspark interpreters
### What is this PR for?
Rename "R" directory to "2BWJFTXKJ" under notebook directory to make it look like all other notebooks.
### What type of PR is it?
[Refactoring]
### Todos
* [x] - Rename
### What is the Jira issue?
* N/A
### How should this be tested?
goto $ZEPPELIN_HOME/notebook directory, under this there should be no "R" directory.
On starting zeppelin-server, the existing notebook should be listed.
### Screenshots (if appropriate)
N/A
### Questions:
* Does the licenses files need update? N/A
* Is there breaking changes for older versions? N/A
* Does this needs documentation? N/A
Author: Prabhjyot Singh <prabhjyotsingh@gmail.com>
Closes#1394 from prabhjyotsingh/renameRDirectory and squashes the following commits:
5993506 [Prabhjyot Singh] rename r directory to 2BWJFTXKJ
### What is this PR for?
Add new interpreter to Python group: `%python.sql` for SQL over DataFrame support
### What type of PR is it?
Improvement
### TODOs
* [x] add new interpreter `%python.sql`
* [x] add test
* [x] make Python-dependant tests, excluded from CI
* PythonInterpreterWithPythonInstalledTest
* PythonPandasSqlInterpreterTest
* run manually by `mvn -Dpython.test.exclude='' test -pl python -am`
* [x] add docs `%python.sql`
* [x] make `%python.sql` fail gracefully in case there is no Pandas or PandaSQL installed
* [x] after #747 is merged - rebase and remove `-Dpython.test.exclude=''` from both profiles
### What is the Jira issue?
[ZEPPELIN-1115](https://issues.apache.org/jira/browse/ZEPPELIN-1115)
### How should this be tested?
`mvn -Dpython.test.exclude='' test -pl python -am` should pass or manually run
- Given the DataFrame i.e
```
%python
import pandas as pd
rates = pd.read_csv("bank.csv", sep=";")
```
- SQL query it like
```
%python.sql
SELECT * FROM rates LIMIT 10
```
### Screenshots (if appropriate)

### Questions:
* Does the licenses files need update? No, no dependencies were included in source or binary release
* Is there breaking changes for older versions? No
* Does this needs documentation? Yes
Author: Alexander Bezzubov <bzz@apache.org>
Closes#1164 from bzz/ZEPPELIN-1115/python/add-sql-for-dataframes and squashes the following commits:
0f2f852 [Alexander Bezzubov] Fail SQL gracefully if no python dependencies installed
aca2bdf [Alexander Bezzubov] Fix typos in docs ⚡158ba6a [Alexander Bezzubov] Remove third-party dependant test from CI
5fe46fc [Alexander Bezzubov] Update Python Matplotlib notebook example
72884c8 [Alexander Bezzubov] Add docs for %python.sql feature
e931dc4 [Alexander Bezzubov] Make test for PythonPandasSqlInterpreter usable
76bbb44 [Alexander Bezzubov] Complete implementation of the PythonPandasSqlInterpreter
f6ca1eb [Alexander Bezzubov] Add %python.sql to interpreter menue
11ba490 [Alexander Bezzubov] Add draft implementation of %python.sql for DataFrames
### What is this PR for?
Display Pandas DataFrame using Zeppelin's Table Display system.
### What type of PR is it?
Feature
### Todos
* [x] fix NPE in logs on empty paragraph execution
* [x] matplotlib: refactor `zeppelin_show(plt)` -> `z.show(plt)`
* [x] pandas: support `z.show(df)`
* [x] update docs
### What is the Jira issue?
[ZEPPELIN-1048](https://issues.apache.org/jira/browse/ZEPPELIN-1048)
### How should this be tested?
"Zeppelin Tutorial: Python - matplotlib basic" should work, and
```python
import pandas as pd
rates = pd.read_csv("bank.csv", sep=";")
z.show(rates)
```
### Screenshots (if appropriate)

### Questions:
* Does the licenses files need update? No
* Is there breaking changes for older versions? No
* Does this needs documentation? Yes
Author: Alexander Bezzubov <bzz@apache.org>
Closes#1067 from bzz/python/pandas-support and squashes the following commits:
3b1ad36 [Alexander Bezzubov] Python: update docs to reffer new API
ee6668b [Alexander Bezzubov] Python: update docs, add Pandas integration
71be418 [Alexander Bezzubov] Python: limit 1000 for table display system on DataFrame
52e787d [Alexander Bezzubov] Python: pandas DataFrame using Table display system
bc91b86 [Alexander Bezzubov] Python: skip interpreting empty paragraphs
a7248cd [Alexander Bezzubov] Python: draft of pandas support
15646a1 [Alexander Bezzubov] Python: refactoring to z.show()
### What is this PR for?
Implement R and SpakR Intepreter as part of the Spark Interpreter Group. It also implements R and Scala binding (in both directions).
### What type of PR is it?
[Feature]
### Todos
* [ ] - Documentation
* [ ] - Unit test (if relevant, as we depend on R being available on the host)
* [ ] - Assess licensing (a priori ok as we don't delive anything out of ASL2, but we should corectly phrase the NOTICE as we depend on non-ASL2 comptabile licenses (R) to run the interpreter).
### Is there a relevant Jira issue?
https://issues.apache.org/jira/browse/ZEPPELIN-156 SparkR support
### How should this be tested?
You need R available on the host running the notebook.
For Centos: yum install R R-devel
For Ubuntu: apt-get install r-base r-cran-rserve
Install additional R packages:
```
curl https://cran.r-project.org/src/contrib/Archive/rscala/rscala_1.0.6.tar.gz -o /tmp/rscala_1.0.6.tar.gz
R CMD INSTALL /tmp/rscala_1.0.6.tar.gz
R -e "install.packages('ggplot2', repos = 'http://cran.us.r-project.org')"
R -e install.packages('knitr', repos = 'http://cran.us.r-project.org')
```
- Build + launch Zeppelin and test the R note.
!!! you need rscala_1.0.6 (if not, you need to build with -Drscala.version=...)
### Screenshots (if appropriate)
#### Simple R
[](https://raw.githubusercontent.com/datalayer/zeppelin-R/rscala/_Rimg/simple-r.png)
#### Plot
[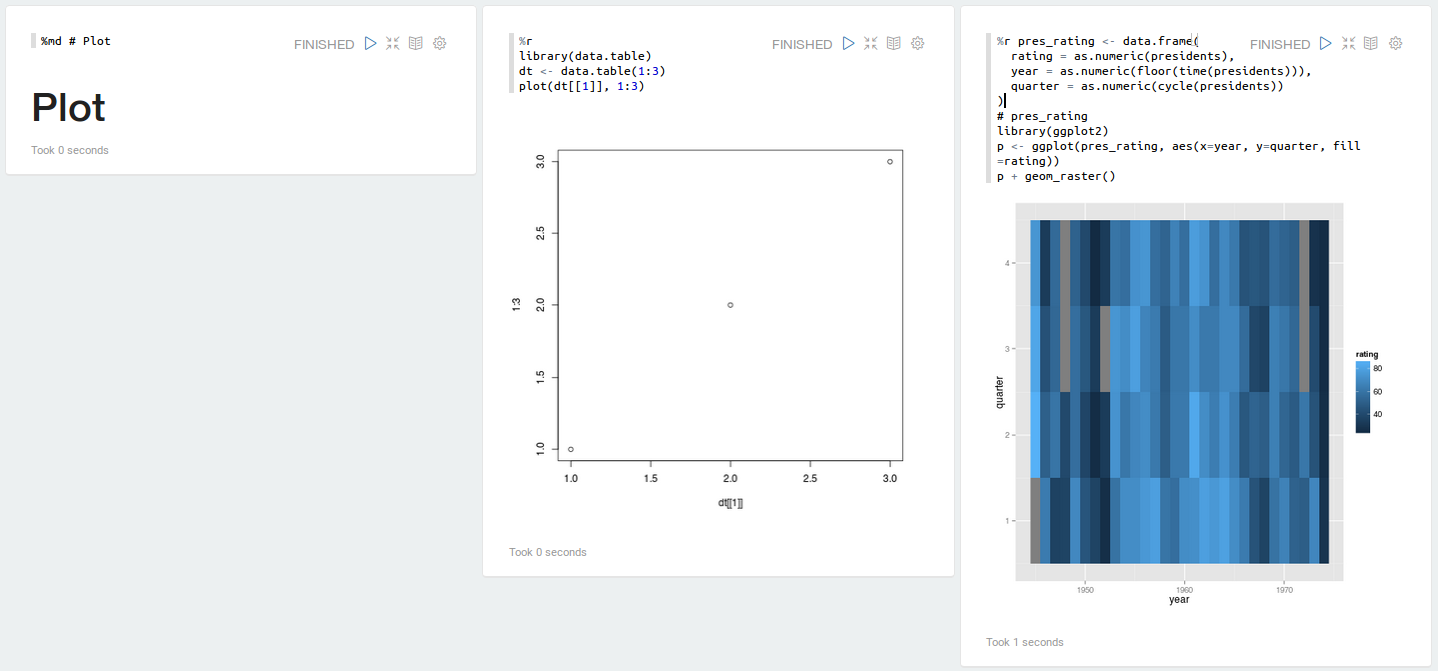](https://raw.githubusercontent.com/datalayer/zeppelin-R/rscala/_Rimg/plot.png)
#### Scala R Binding
[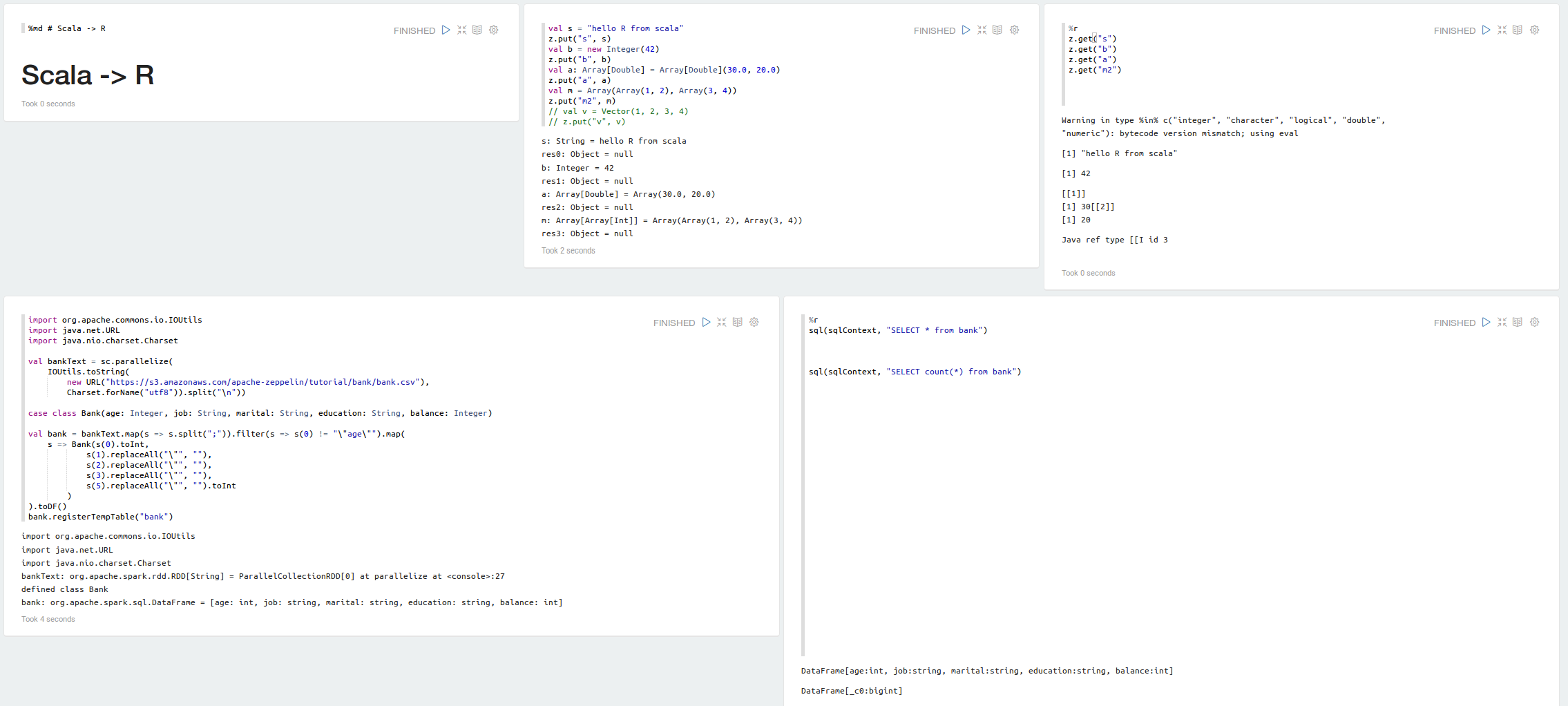](https://raw.githubusercontent.com/datalayer/zeppelin-R/rscala/_Rimg/scala-r.png)
#### R Scala Binding
[](https://raw.githubusercontent.com/datalayer/zeppelin-R/rscala/_Rimg/r-scala.png)
#### SparkR
[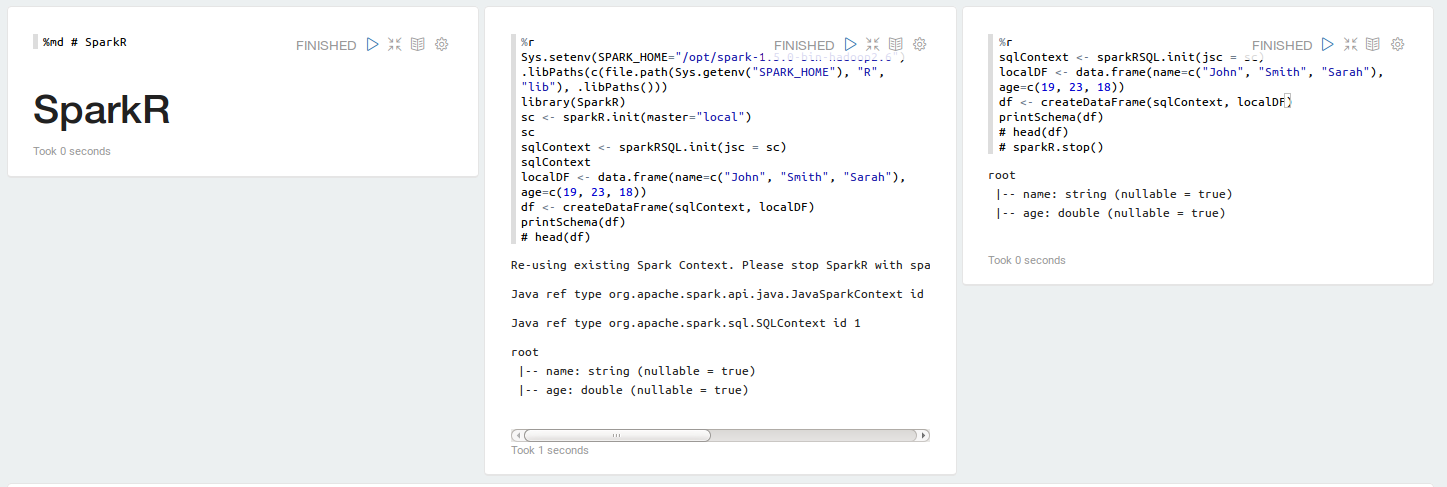](https://raw.githubusercontent.com/datalayer/zeppelin-R/rscala/_Rimg/sparkr.png)
### Questions:
* Does the licenses files need update? to be checked... (cfr R needs to be available to make this interpreter operational).
* Is there breaking changes for older versions? No
* Does this needs documentation? Yes
Author: Eric Charles <eric@datalayer.io>
Author: Lee moon soo <moon@apache.org>
This patch had conflicts when merged, resolved by
Committer: Lee moon soo <moon@apache.org>
Closes#702 from echarles/rscala-z and squashes the following commits:
137040c [Eric Charles] Trigger build again
53645f6 [Eric Charles] Trigger build
519f3a9 [Eric Charles] Add back the spark.bin.download.url property for sparkr profile
d1f0521 [Eric Charles] Merge with master
72ab72c [Eric Charles] Trigger travis build
151af0a [Eric Charles] Enable back the R install in travis
ed70820 [Eric Charles] Merge with master
ae21036 [Eric Charles] Note: unlist array passed from scala to R, patch contributed by @jeffsteinmetz
ac0e16d [Eric Charles] Merge pull request #8 from Leemoonsoo/rscala-z-fix-interpreter-list-order
90c1b4d [Lee moon soo] Sort interpreter list correctly
c36fe8a [Eric Charles] Return SUCCESS if result is empty
463c066 [Eric Charles] Log exception on open
f6e685a [Eric Charles] Remove SparkRInterpeterTest, test is convered in ZeppelinSparkClusterTest
19ec4f3 [Eric Charles] Add back SparkRInterpreterTest.java
58227e9 [Eric Charles] Merge branch 'rscala-z-rs' into rscala-z
290289f [Eric Charles] Merge with master
eb6c40c [Eric Charles] Merge remote rscala-z-rs
962d0d9 [Eric Charles] DOC: Add more visualization libraries
9b95d60 [Lee moon soo] Remove unnecessary test
894c399 [Lee moon soo] Remove SparkRInterpreterTest
bac1e1b [Lee moon soo] R on travis
f6661c2 [Lee moon soo] fix profile activation
1a0195f [Lee moon soo] exclude test when sparkr profile is not defined
2307115 [Lee moon soo] Make sparkr work without SPARK_HOME
dcfee32 [Lee moon soo] Add test
aa35a83 [Lee moon soo] Download sparkR package
1d99fa8 [Lee moon soo] Remove rscala related stuff from project
fc66da9 [Lee moon soo] R -> r
a122894 [Lee moon soo] render output
9df9535 [Lee moon soo] Remove rscala dependency
1e2c99b [Eric Charles] DOC: no need for r-cran-rserve, thx to @jeffsteinmetz
2300ebc [Eric Charles] Update to latest change in interpeter constructs
ecf8bc4 [Eric Charles] Merge with master
a119b72 [Eric Charles] Merge with remote
454c1cb [Eric Charles] Rebase on master and update test to deal with interpretercontext constructor change
b30f6f4 [Eric Charles] Support HTML, TABLE and IMG display - Dynamic form in progress
89d6a3a [Eric Charles] DOC: Fix typo (contributed by @AhyoungRyu) + fix missing depencies (contributed by @btiernay on https://github.com/datalayer/datalayer-zeppelin/issues/6)
a6a3695 [Eric Charles] fix SparkInterpreterTest to deal with previous commit chanching the returned html
35486c7 [Eric Charles] Always return html preview in case of pure text
a0306fc [Eric Charles] Fix the expected html value for test
47eec88 [Eric Charles] Fix code format to make checkstyle happy
f963e1c [Eric Charles] polish examples with title
6cf8615 [Eric Charles] Make it work also on chromium
7b04b6b [Eric Charles] Support ggplot2 output size https://github.com/datalayer/zeppelin-R/issues/217d6b0d [Eric Charles] Less test in the SparkRInterpreterTest
f4aac04 [Eric Charles] Add interactive visualization example
816f4d9 [Eric Charles] Run only one test method and see Travis reaction
702556f [Eric Charles] RAT: Disabel RAT check on downloaded rscala folder
d5538a2 [Eric Charles] update pom to download rscala on build
40efe33 [Eric Charles] Add test for SparkRInterpreter
09bb458 [Eric Charles] Use java factory to allow mockito usage
5385adb [Eric Charles] Add jar in R folder
c0063fc [Eric Charles] Ignore downloaded rscala
4d5cfa5 [Eric Charles] Initial documentation for R Interpreter
3e24d02 [Eric Charles] Add license for rscala
c88a914 [Eric Charles] Remove rscala jar
554bcb6 [Eric Charles] Add README.md placeholder for rscala lib folder
40b4ec6 [Eric Charles] Remove png files and restore README.md
220fe51 [Eric Charles] Make rscala configurable in the spark-dependencies module
15375eb [Eric Charles] Add SparRInterpreter implementation
4161619 [Eric Charles] Support HTML, TABLE and IMG display - Dynamic form in progress
8e635e1 [Eric Charles] DOC: Fix typo (contributed by @AhyoungRyu) + fix missing depencies (contributed by @btiernay on https://github.com/datalayer/datalayer-zeppelin/issues/6)
9a988f9 [Eric Charles] fix SparkInterpreterTest to deal with previous commit chanching the returned html
28fc9b2 [Eric Charles] Always return html preview in case of pure text
e8ed8dd [Eric Charles] Fix the expected html value for test
facc682 [Eric Charles] Fix code format to make checkstyle happy
9b168ff [Eric Charles] polish examples with title
8b059c4 [Eric Charles] Make it work also on chromium
66c3545 [Eric Charles] Support ggplot2 output size https://github.com/datalayer/zeppelin-R/issues/23ae0bc1 [Eric Charles] Less test in the SparkRInterpreterTest
b9b2787 [Eric Charles] Add interactive visualization example
9218d65 [Eric Charles] Run only one test method and see Travis reaction
ee6e43b [Eric Charles] RAT: Disabel RAT check on downloaded rscala folder
8d664f6 [Eric Charles] update pom to download rscala on build
21668b3 [Eric Charles] Add test for SparkRInterpreter
068ac24 [Eric Charles] Use java factory to allow mockito usage
caf157b [Eric Charles] Add jar in R folder
1eddadb [Eric Charles] Ignore downloaded rscala
0af2bec [Eric Charles] Initial documentation for R Interpreter
8e3c997 [Eric Charles] Add license for rscala
7a95ef4 [Eric Charles] Remove rscala jar
b8ae4eb [Eric Charles] Add README.md placeholder for rscala lib folder
aa6a7a1 [Eric Charles] Remove png files and restore README.md
9312a0c [Eric Charles] Make rscala configurable in the spark-dependencies module
363b244 [Eric Charles] Add SparRInterpreter implementation
### What is this PR for?
Add an interpreter to work with a tachyon file system.
Properties required for the interpreter are:
* tachyon master hostname
* tachyon master port
### What type of PR is it?
feature
### Is there a relevant Jira issue?
https://issues.apache.org/jira/browse/ZEPPELIN-604
### How should this be tested?
* [Install and configure Tachyon](http://tachyon-project.org/downloads/) on a local machine.
* run Tachyon in local mode ```$ ./bin/tachyon-start.sh local```
* check that interpreter params are setted to default values (hostname: localhost, port: 19998)
* use the [Tachyon CLI commands](http://tachyon-project.org/documentation/Command-Line-Interface.html) to interact with your Tachyon file system
### Screenshots (if appropriate)

### Questions:
* Does the licenses files need update? no
* Is there breaking changes for older versions? no
* Does this needs documentation? no
/cc jsimsa for the support he give us to develop this feature
Author: maocorte <mauro.cortellazzi@radicalbit.io>
Closes#632 from maocorte/tachyon-interpreter and squashes the following commits:
6f01654 [maocorte] added new line on tachyon doc to fix visualization problem
700ff48 [maocorte] added a simple test example to tachyon doc
e7341af [maocorte] small fixes on tachyon doc
3f1c455 [maocorte] formatted tachyon doc with new guidelines + added link to tachyon doc into navigation page
1018409 [maocorte] added tachyon dependency licences
cc622ce [maocorte] added Tachyon interpreter tests
9c51dca [maocorte] changed tachyon module order into main pom
5eaafbb [maocorte] added tachyon interpreter md doc
12fbf03 [maocorte] added help command to list all available commands
e5465a5 [maocorte] resolved conflict
eeb37d6 [maocorte] resolved comflict
f0ed930 [maocorte] removed unused import
8d7ae93 [maocorte] changed completion implementation
0ded511 [maocorte] added tachyon shell license
8a33ea5 [maocorte] added logs on opening and closing interpreter
53011dc [maocorte] Merge branch 'master' into tachyon-interpreter
ca64582 [maocorte] code cleanup
7c09709 [maocorte] updated code to master branch
b8add66 [maocorte] using system properties to set tachyon client configuration
2895a59 [maocorte] updated to code to lastest master version
b5a4b54 [maocorte] added tachyon interpreter to available interpreters list
8a84514 [maocorte] added tachyon interpreter module to main project pom
88f2bcf [maocorte] added tachyon interpreter module
Tutorial notebook is downloading data using `wget` and unzip and load the csv file.
This works only in local-mode and not going to work with cluster deployments.
Discussed solution in the issue ZEPPELIN-55 are
* Upload data to HDFS
* Upload data to S3
However, not all user will install HDFS, and accessing S3 via hdfs client needs accessKey and secretKey in configuration.
this PR make tutorial notebook independent from any filesystem, by reading data from http(s) address and parallelize directly.
Here's how this PR loads data
```
// load bank data
val bankText = sc.parallelize(
IOUtils.toString(
new URL("https://s3.amazonaws.com/apache-zeppelin/tutorial/bank/bank.csv"),
Charset.forName("utf8")).split("\n"))
case class Bank(age: Integer, job: String, marital: String, education: String, balance: Integer)
val bank = bankText.map(s => s.split(";")).filter(s => s(0) != "\"age\"").map(
s => Bank(s(0).toInt,
s(1).replaceAll("\"", ""),
s(2).replaceAll("\"", ""),
s(3).replaceAll("\"", ""),
s(5).replaceAll("\"", "").toInt
)
).toDF()
bank.registerTempTable("bank")
```
Author: Lee moon soo <moon@apache.org>
Closes#140 from Leemoonsoo/ZEPPELIN-55 and squashes the following commits:
653b1bc [Lee moon soo] Load data directly from http without using filesystem
Remove sqlContext creation from tutorial notebook.
sqlContext is supposed to created and injected by Zeppelin.
Author: Lee moon soo <moon@apache.org>
Closes#102 from Leemoonsoo/update_tutorial and squashes the following commits:
8818a6a [Lee moon soo] Remove sqlContext creation from tutorial notebook
I updated the tutorial to ignore the default settings for the file system when looking up bank.csv by prepending ("file://"). This is safe since the working directory for $zeppelinHome is set on the previous line to PWD which will always be the local FS.
Author: Ilya Ganelin <ilya.ganelin@capitalone.com>
Closes#70 from ilganeli/ZEPPELIN-5 and squashes the following commits:
01fb781 [Ilya Ganelin] Changed tutorial string to ignore default setting for local FS
Also a couple of minor grammar tweaks in the first paragraph.
Author: Digeratus <digerat@gmail.com>
Closes#24 from langley/tweak_notebook_for_Spark_1.3.0 and squashes the following commits:
9d6c378 [Digeratus] Minor tweaks to the tutorial notebook to support Spark 1.3.0 Also a couple of minor grammar tweaks in the first paragraph.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}