mirror of
https://github.com/apache/zeppelin
synced 2026-05-24 09:38:26 +00:00
Remove png files and restore README.md
This commit is contained in:
parent
220fe51e01
commit
40b4ec6ba5
6 changed files with 198 additions and 66 deletions
264
README.md
264
README.md
|
|
@ -1,102 +1,234 @@
|
|||
# Apache Zeppelin R
|
||||
#Zeppelin
|
||||
|
||||
This adds [R](http://cran.r-project.org) interpeter to the [Apache Zeppelin notebook](http://zeppelin.incubator.apache.org).
|
||||
**Documentation:** [User Guide](http://zeppelin.incubator.apache.org/docs/latest/index.html)<br/>
|
||||
**Mailing Lists:** [User and Dev mailing list](http://zeppelin.incubator.apache.org/community.html)<br/>
|
||||
**Continuous Integration:** [](https://travis-ci.org/apache/incubator-zeppelin) <br/>
|
||||
**Contributing:** [Contribution Guide](https://github.com/apache/incubator-zeppelin/blob/master/CONTRIBUTING.md)<br/>
|
||||
**Issue Tracker:** [Jira](https://issues.apache.org/jira/browse/ZEPPELIN)<br/>
|
||||
**License:** [Apache 2.0](https://github.com/apache/incubator-zeppelin/blob/master/LICENSE)
|
||||
|
||||
It supports:
|
||||
|
||||
+ R code.
|
||||
+ SparkR code.
|
||||
+ Cross paragraph R variables.
|
||||
+ Scala to R binding (passing basic Scala data structure to R).
|
||||
+ R to Scala binding (passing basic R data structure to Scala).
|
||||
+ R plot (ggplot2...).
|
||||
**Zeppelin**, a web-based notebook that enables interactive data analytics. You can make beautiful data-driven, interactive and collaborative documents with SQL, Scala and more.
|
||||
|
||||
## Simple R
|
||||
Core feature:
|
||||
* Web based notebook style editor.
|
||||
* Built-in Apache Spark support
|
||||
|
||||
[](https://raw.githubusercontent.com/datalayer/zeppelin-R/rscala/_Rimg/simple-r.png)
|
||||
|
||||
## Plot
|
||||
To know more about Zeppelin, visit our web site [http://zeppelin.incubator.apache.org](http://zeppelin.incubator.apache.org)
|
||||
|
||||
[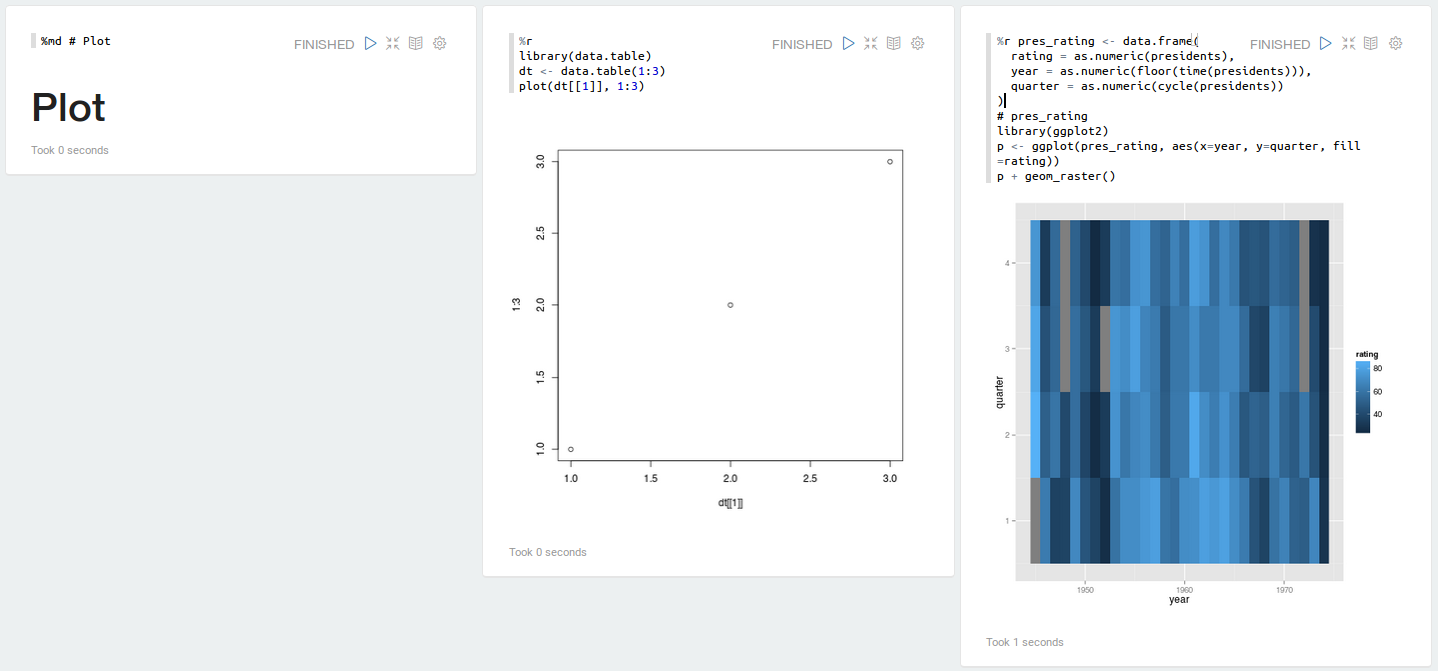](https://raw.githubusercontent.com/datalayer/zeppelin-R/rscala/_Rimg/plot.png)
|
||||
## Requirements
|
||||
* Java 1.7
|
||||
* Tested on Mac OSX, Ubuntu 14.X, CentOS 6.X
|
||||
* Maven (if you want to build from the source code)
|
||||
* Node.js Package Manager
|
||||
|
||||
## Scala R Binding
|
||||
## Getting Started
|
||||
|
||||
[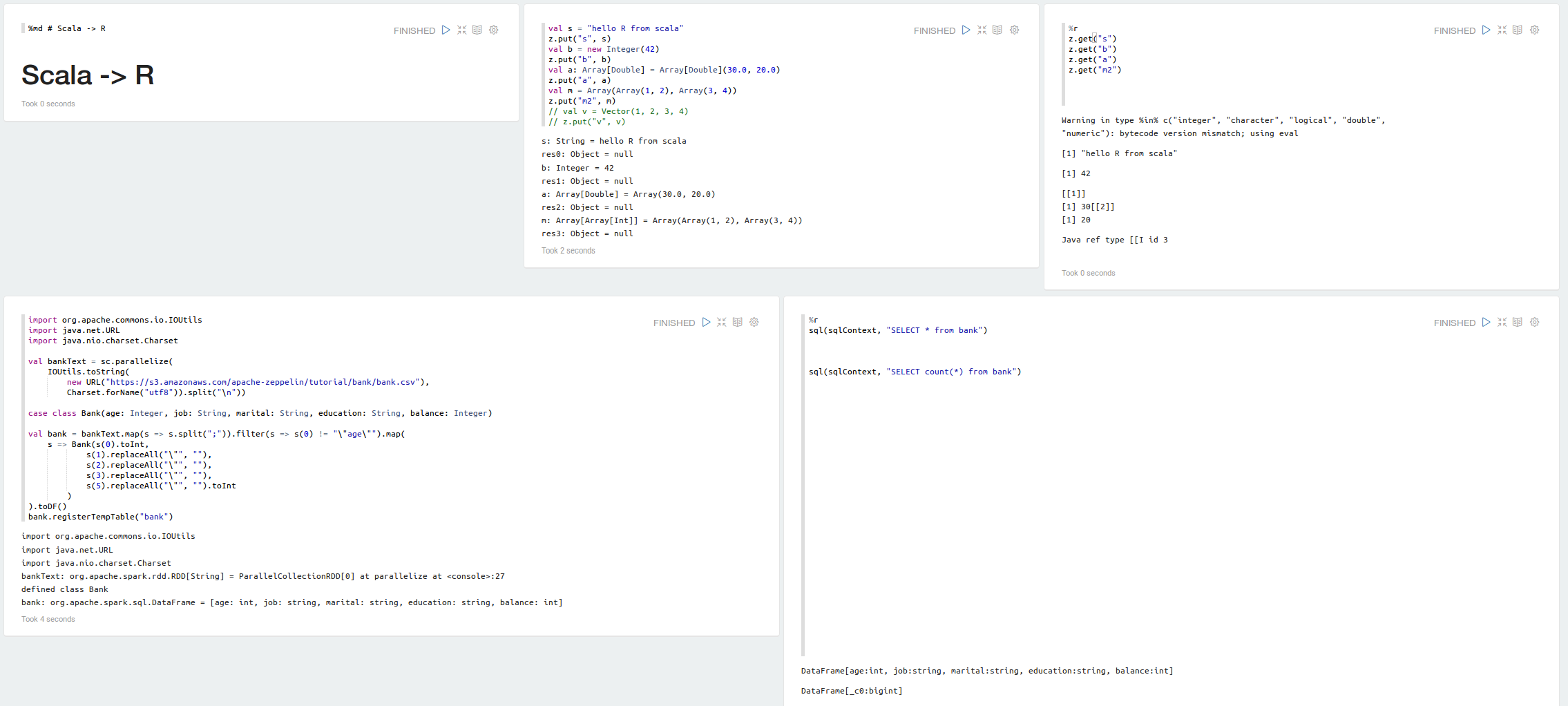](https://raw.githubusercontent.com/datalayer/zeppelin-R/rscala/_Rimg/scala-r.png)
|
||||
|
||||
## R Scala Binding
|
||||
|
||||
[](https://raw.githubusercontent.com/datalayer/zeppelin-R/rscala/_Rimg/r-scala.png)
|
||||
|
||||
## SparkR
|
||||
|
||||
[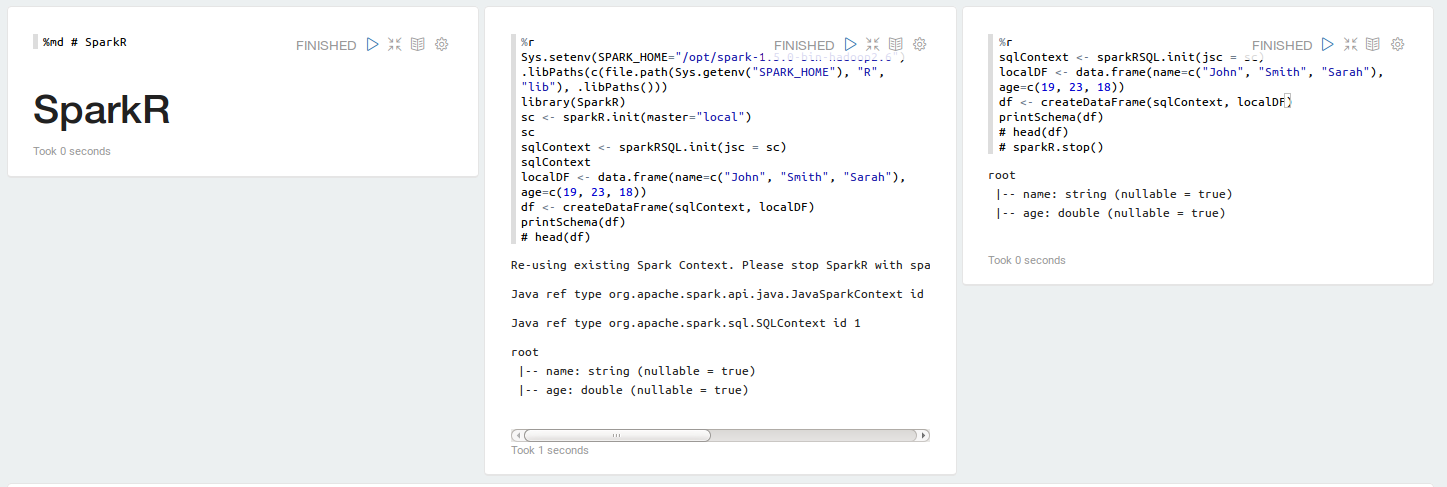](https://raw.githubusercontent.com/datalayer/zeppelin-R/rscala/_Rimg/sparkr.png)
|
||||
|
||||
# Prerequisite
|
||||
|
||||
You need R available on the host running the notebook.
|
||||
|
||||
+ For Centos: `yum install R R-devel`
|
||||
+ For Ubuntu: `apt-get install r-base r-cran-rserve`
|
||||
|
||||
Install additional R packages:
|
||||
### Before Build
|
||||
If you don't have requirements prepared, install it.
|
||||
(The installation method may vary according to your environment, example is for Ubuntu.)
|
||||
|
||||
```
|
||||
curl https://cran.r-project.org/src/contrib/Archive/rscala/rscala_1.0.6.tar.gz -o /tmp/rscala_1.0.6.tar.gz
|
||||
R CMD INSTALL /tmp/rscala_1.0.6.tar.gz
|
||||
R -e "install.packages('ggplot2', repos = 'http://cran.us.r-project.org')"
|
||||
R -e install.packages('knitr', repos = 'http://cran.us.r-project.org')
|
||||
sudo apt-get update
|
||||
sudo apt-get install git
|
||||
sudo apt-get install openjdk-7-jdk
|
||||
sudo apt-get install npm
|
||||
sudo apt-get install libfontconfig
|
||||
|
||||
# install maven
|
||||
wget http://www.eu.apache.org/dist/maven/maven-3/3.3.3/binaries/apache-maven-3.3.3-bin.tar.gz
|
||||
sudo tar -zxf apache-maven-3.3.3-bin.tar.gz -C /usr/local/
|
||||
sudo ln -s /usr/local/apache-maven-3.3.3/bin/mvn /usr/local/bin/mvn
|
||||
```
|
||||
|
||||
You also need a compiled version of Spark 1.5.0. Download [the binary distribution](http://archive.apache.org/dist/spark/spark-1.5.0/spark-1.5.0-bin-hadoop2.6.tgz) and untar to make it accessible in `/opt/spark` folder.
|
||||
_Notes:_
|
||||
- Ensure node is installed by running `node --version`
|
||||
- Ensure maven is running version 3.1.x or higher with `mvn -version`
|
||||
- Configure maven to use more memory than usual by ```export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=1024m"```
|
||||
|
||||
# Build and Run
|
||||
### Build
|
||||
If you want to build Zeppelin from the source, please first clone this repository, then:
|
||||
|
||||
```
|
||||
mvn clean install -Pspark-1.5 -Dspark.version=1.5.0 \
|
||||
-Dhadoop.version=2.7.1 -Phadoop-2.6 -Ppyspark \
|
||||
-Dmaven.findbugs.enable=false -Drat.skip=true -Dcheckstyle.skip=true \
|
||||
-DskipTests \
|
||||
-pl '!flink,!ignite,!phoenix,!postgresql,!tajo,!hive,!cassandra,!lens,!kylin'
|
||||
mvn clean package -DskipTests [Options]
|
||||
```
|
||||
|
||||
Each Interpreter requires different Options.
|
||||
|
||||
|
||||
#### Spark Interpreter
|
||||
|
||||
To build with a specific Spark version, Hadoop version or specific features, define one or more of the following profiles and options:
|
||||
|
||||
##### -Pspark-[version]
|
||||
|
||||
Set spark major version
|
||||
|
||||
Available profiles are
|
||||
|
||||
```
|
||||
SPARK_HOME=/opt/spark ./bin/zeppelin.sh
|
||||
-Pspark-1.6
|
||||
-Pspark-1.5
|
||||
-Pspark-1.4
|
||||
-Pspark-1.3
|
||||
-Pspark-1.2
|
||||
-Pspark-1.1
|
||||
-Pcassandra-spark-1.5
|
||||
-Pcassandra-spark-1.4
|
||||
-Pcassandra-spark-1.3
|
||||
-Pcassandra-spark-1.2
|
||||
-Pcassandra-spark-1.1
|
||||
```
|
||||
|
||||
Go to [http://localhost:8080](http://localhost:8080) and test the `R Tutorial` note.
|
||||
minor version can be adjusted by `-Dspark.version=x.x.x`
|
||||
|
||||
## Get the image from the Docker Repository
|
||||
|
||||
For your convenience, [Datalayer](http://datalayer.io) provides an up-to-date Docker image for [Apache Zeppelin](http://zeppelin.incubator.apache.org), the WEB Notebook for Big Data Science.
|
||||
##### -Phadoop-[version]
|
||||
|
||||
In order to get the image, you can run with the appropriate rights:
|
||||
set hadoop major version
|
||||
|
||||
`docker pull datalayer/zeppelin-rscala`
|
||||
Available profiles are
|
||||
|
||||
Run the Zeppelin notebook with:
|
||||
```
|
||||
-Phadoop-0.23
|
||||
-Phadoop-1
|
||||
-Phadoop-2.2
|
||||
-Phadoop-2.3
|
||||
-Phadoop-2.4
|
||||
-Phadoop-2.6
|
||||
```
|
||||
|
||||
`docker run -it -p 2222:22 -p 8080:8080 -p 4040:4040 datalayer/zeppelin-rscala`
|
||||
minor version can be adjusted by `-Dhadoop.version=x.x.x`
|
||||
|
||||
and go to [http://localhost:8080](http://localhost:8080) to test the `R Tutorial` note.
|
||||
##### -Pyarn (optional)
|
||||
|
||||
# License
|
||||
enable YARN support for local mode
|
||||
|
||||
Copyright 2015 Datalayer http://datalayer.io
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
##### -Ppyspark (optional)
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
enable PySpark support for local mode
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
|
||||
[](http://cran.r-project.org)
|
||||
##### -Pvendor-repo (optional)
|
||||
|
||||
[](http://zeppelin.incubator.apache.org)
|
||||
enable 3rd party vendor repository (cloudera)
|
||||
|
||||
[](http://datalayer.io)
|
||||
|
||||
##### -Pmapr[version] (optional)
|
||||
|
||||
For the MapR Hadoop Distribution, these profiles will handle the Hadoop version. As MapR allows different versions
|
||||
of Spark to be installed, you should specify which version of Spark is installed on the cluster by adding a Spark profile (-Pspark-1.2, -Pspark-1.3, etc.) as needed. For Hive, check the hive/pom.xml and adjust the version installed as well. The correct Maven
|
||||
artifacts can be found for every version of MapR at http://doc.mapr.com
|
||||
|
||||
Available profiles are
|
||||
|
||||
```
|
||||
-Pmapr3
|
||||
-Pmapr40
|
||||
-Pmapr41
|
||||
-Pmapr50
|
||||
```
|
||||
|
||||
|
||||
Here're some examples:
|
||||
|
||||
```
|
||||
# basic build
|
||||
mvn clean package -Pspark-1.6 -Phadoop-2.4 -Pyarn -Ppyspark
|
||||
|
||||
# spark-cassandra integration
|
||||
mvn clean package -Pcassandra-spark-1.5 -Dhadoop.version=2.6.0 -Phadoop-2.6 -DskipTests
|
||||
|
||||
# with CDH
|
||||
mvn clean package -Pspark-1.5 -Dhadoop.version=2.6.0-cdh5.5.0 -Phadoop-2.6 -Pvendor-repo -DskipTests
|
||||
|
||||
# with MapR
|
||||
mvn clean package -Pspark-1.5 -Pmapr50 -DskipTests
|
||||
```
|
||||
|
||||
|
||||
#### Ignite Interpreter
|
||||
|
||||
```
|
||||
mvn clean package -Dignite.version=1.1.0-incubating -DskipTests
|
||||
```
|
||||
|
||||
#### Scalding Interpreter
|
||||
|
||||
```
|
||||
mvn clean package -Pscalding -DskipTests
|
||||
```
|
||||
|
||||
### Configure
|
||||
If you wish to configure Zeppelin option (like port number), configure the following files:
|
||||
|
||||
```
|
||||
./conf/zeppelin-env.sh
|
||||
./conf/zeppelin-site.xml
|
||||
```
|
||||
(You can copy ```./conf/zeppelin-env.sh.template``` into ```./conf/zeppelin-env.sh```.
|
||||
Same for ```zeppelin-site.xml```.)
|
||||
|
||||
|
||||
#### Setting SPARK_HOME and HADOOP_HOME
|
||||
|
||||
Without SPARK_HOME and HADOOP_HOME, Zeppelin uses embedded Spark and Hadoop binaries that you have specified with mvn build option.
|
||||
If you want to use system provided Spark and Hadoop, export SPARK_HOME and HADOOP_HOME in zeppelin-env.sh
|
||||
You can use any supported version of spark without rebuilding Zeppelin.
|
||||
|
||||
```
|
||||
# ./conf/zeppelin-env.sh
|
||||
export SPARK_HOME=...
|
||||
export HADOOP_HOME=...
|
||||
```
|
||||
|
||||
#### External cluster configuration
|
||||
Mesos
|
||||
|
||||
# ./conf/zeppelin-env.sh
|
||||
export MASTER=mesos://...
|
||||
export ZEPPELIN_JAVA_OPTS="-Dspark.executor.uri=/path/to/spark-*.tgz" or SPARK_HOME="/path/to/spark_home"
|
||||
export MESOS_NATIVE_LIBRARY=/path/to/libmesos.so
|
||||
|
||||
If you set `SPARK_HOME`, you should deploy spark binary on the same location to all worker nodes. And if you set `spark.executor.uri`, every worker can read that file on its node.
|
||||
|
||||
Yarn
|
||||
|
||||
# ./conf/zeppelin-env.sh
|
||||
export SPARK_HOME=/path/to/spark_dir
|
||||
|
||||
### Run
|
||||
./bin/zeppelin-daemon.sh start
|
||||
|
||||
browse localhost:8080 in your browser.
|
||||
|
||||
|
||||
For configuration details check __./conf__ subdirectory.
|
||||
|
||||
### Package
|
||||
To package the final distribution including the compressed archive, run:
|
||||
|
||||
mvn clean package -Pbuild-distr
|
||||
|
||||
To build a distribution with specific profiles, run:
|
||||
|
||||
mvn clean package -Pbuild-distr -Pspark-1.5 -Phadoop-2.4 -Pyarn -Ppyspark
|
||||
|
||||
The profiles `-Pspark-1.5 -Phadoop-2.4 -Pyarn -Ppyspark` can be adjusted if you wish to build to a specific spark versions, or omit support such as `yarn`.
|
||||
|
||||
The archive is generated under _zeppelin-distribution/target_ directory
|
||||
|
||||
###Run end-to-end tests
|
||||
Zeppelin comes with a set of end-to-end acceptance tests driving headless selenium browser
|
||||
|
||||
#assumes zeppelin-server running on localhost:8080 (use -Durl=.. to override)
|
||||
mvn verify
|
||||
|
||||
#or take care of starting\stoping zeppelin-server from packaged _zeppelin-distribuion/target_
|
||||
mvn verify -P using-packaged-distr
|
||||
|
||||
|
||||
|
||||
[](https://github.com/igrigorik/ga-beacon)
|
||||
|
|
|
|||
BIN
_Rimg/plot.png
BIN
_Rimg/plot.png
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 59 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 49 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 136 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 42 KiB |
BIN
_Rimg/sparkr.png
BIN
_Rimg/sparkr.png
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 74 KiB |
Loading…
Reference in a new issue