* Add ROCm detection to install.sh and expand shell tests Add AMD ROCm GPU detection to get_torch_index_url() in install.sh. When nvidia-smi is not found, probe for ROCm via amd-smi, /opt/rocm version file, hipconfig, dpkg-query, and rpm. Includes validation guard for malformed _rocm_tag, Debian epoch prefix stripping, ROCm 7.2+ cap to rocm7.1 index, bitsandbytes AMD install, and status messaging. Shell tests expanded to 23 cases. Co-authored-by: Daniel Han <danielhanchen@gmail.com> * Add ROCm torch reinstall support to install_python_stack.py Add _detect_rocm_version() and _ensure_rocm_torch() to detect when a Linux host has ROCm but the venv received CPU-only torch, and reinstall with the correct ROCm wheels. Covers ROCm 6.0 through 7.1 with a 30-second timeout on the torch GPU probe subprocess. Co-authored-by: Daniel Han <danielhanchen@gmail.com> * Add ROCm support to llama.cpp prebuilt installer Add has_rocm field to HostInfo, extend detect_host() to probe for ROCm via hipcc/amd-smi/rocm-smi/ROCM_PATH, and route ROCm hosts to upstream prebuilts (Linux ROCm 7.2 prebuilt with source fallback, Windows HIP prebuilt with CPU fallback). Add linux-rocm and windows-hip install kinds to runtime_patterns_for_choice(). Co-authored-by: Daniel Han <danielhanchen@gmail.com> * Add IS_ROCM hardware flag and fix AMD error message Add IS_ROCM flag to hardware.py detect_hardware() (set when torch.version.hip is present, DeviceType stays CUDA). Export IS_ROCM from __init__.py. Add "rocm" key to get_package_versions(). Replace "We do not support AMD" error in tokenizer_utils.py with a helpful message pointing to ROCm installation docs. Co-authored-by: Daniel Han <danielhanchen@gmail.com> * Add comprehensive ROCm support test suite (68 tests) Add tests/studio/install/test_rocm_support.py covering all ROCm code paths across install_llama_prebuilt.py, install_python_stack.py, hardware.py, tokenizer_utils.py, and install.sh. All tests use mocks and run without AMD hardware. Covers: asset selection (11), runtime patterns (5), HostInfo (4), ROCm version detection (9), torch reinstall (9), index mapping (8), hardware flag (8), tokenizer message (2), install.sh structure (10), and live regression (1). * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Harden ROCm support: probe error handling, version cap, validation Address review findings from 8 independent reviewers: - Wrap _ensure_rocm_torch() torch probe in try/except for TimeoutExpired and OSError so a hung or broken torch import does not crash the installer (8/8 reviewers flagged this) - Add torch>=2.4,<2.11.0 version cap to the ROCm reinstall path to prevent installing unsupported torch 2.11.0 from the rocm7.1 index - Use with-statement for file reads in _detect_rocm_version() to avoid resource leaks - Handle ROCM_PATH="" correctly (use `or "/opt/rocm"` instead of default parameter to avoid relative path resolution) - Strengthen shell validation guard from rocm[0-9] to rocm[1-9] to reject rocm0.x tags that would produce nonexistent PyTorch index URLs - Switch shell version cap from blocklist to allowlist (rocm6.*|rocm7.0* |rocm7.1* pass through, everything else caps to rocm7.1) so future ROCm 10+ does not fall through to a nonexistent index - Add sorted() to _ROCM_TORCH_INDEX lookup for defensive ordering - Fix test_probe_timeout_handled: replace zero-assertion test with proper assertions verifying reinstall proceeds after timeout * Clean up rocm_paths list construction in detect_host() Filter None from the ROCM_PATH env var lookup at list construction time instead of relying on the inline `if p` guard in the any() call. * Require actual AMD GPU presence before selecting ROCm paths All 8 reviewers across 2 cycles independently flagged that ROCm detection used toolkit/filesystem hints (hipcc, /opt/rocm, rocm-core) as a proxy for GPU presence, which would misroute CPU-only or NVIDIA hosts that happen to have ROCm tools installed. Now all 3 detection points (install.sh, install_python_stack.py, install_llama_prebuilt.py) probe for an actual AMD GPU before entering the ROCm path: - install.sh: check rocminfo for gfx* GPU names, or amd-smi list for device rows, before version detection - install_python_stack.py: new _has_rocm_gpu() function probes rocminfo and amd-smi list before _ensure_rocm_torch() proceeds - install_llama_prebuilt.py: detect_host() probes rocminfo/amd-smi list instead of just checking tool existence or directory paths Also: - Shell test mock amd-smi now handles "list" subcommand - Python tests updated to mock _has_rocm_gpu where needed - Added test_no_gpu_with_rocm_tools_skips to verify the new guard - Test index lookups now use sorted() to match production code * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Harden hipconfig version parsing and torch probe compatibility - Add parts[1].isdigit() check in hipconfig version parsing to handle versions like "6.3-HIP" where the minor component has non-numeric suffix (strip "-" prefix before int() conversion) - Use getattr() in torch probe subprocess to safely handle old or custom torch builds that may lack torch.version.hip/cuda attributes * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Strengthen AMD GPU detection and add NVIDIA precedence guard - Change amd-smi list detection from any-non-empty-output to requiring "gpu" marker in output, matching the shell-side NR>1 check. Prevents false positives from header-only amd-smi list output. - Add nvidia-smi check at the top of _ensure_rocm_torch() so mixed AMD+NVIDIA hosts preserve NVIDIA precedence (matching install.sh and install_llama_prebuilt.py behavior). - Apply the same amd-smi marker fix to install_llama_prebuilt.py detect_host() for consistency. * Add Windows-specific ROCm/HIP detection in detect_host() The previous detect_host() ROCm check used rocminfo and amd-smi list which are Linux-only tools. On Windows, has_rocm would always be False, making the Windows HIP prebuilt path at line 1794 unreachable. Now detect_host() uses platform-specific detection: - Linux: rocminfo (check for gfx GPU names) or amd-smi list - Windows: hipinfo.exe, amd-smi, or amdhip64.dll on PATH This allows Windows AMD users to get the HIP prebuilt binary instead of silently falling through to the CPU prebuilt. * Add AMD ROCm gaps: Mamba/SSM source builds, GPU monitoring, Windows messaging, RDNA expansion - worker.py: Add HIP detection to causal-conv1d/mamba-ssm probe, check for hipcc before ROCm source builds, improve status messages and error reporting, add timeout and uv support for the source build fallback - amd.py: New AMD GPU monitoring module via amd-smi metric --json, mirroring nvidia.py structure (utilization, temperature, power, VRAM) - hardware.py: Branch to amd.py when IS_ROCM is True for GPU utilization, visible GPU queries, and physical GPU count - install_python_stack.py: Detect AMD GPUs on Windows and warn that ROCm-enabled PyTorch must be installed manually - kernels/utils.py: Expand is_rdna() to cover RDNA2 (gfx1030-1032), RDNA3 (gfx1102-1103), RDNA3.5 (gfx1150-1152) alongside existing entries - tests: Add 32 new tests covering all changes (95/95 pass) * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Harden ROCm detection, fix VRAM heuristic, and expand RDNA2 coverage - Windows ROCm detection: validate actual GPU presence via hipinfo/amd-smi output markers instead of just checking tool existence on PATH - _ensure_rocm_torch: validate nvidia-smi actually reports a GPU before giving NVIDIA precedence (fixes AMD-only hosts with stale NVIDIA tools) - amd.py _parse_numeric: handle dict-shaped metric objects from newer amd-smi versions ({"value": 10, "unit": "W"}) and strip MiB/GiB units - amd.py VRAM heuristic: raise threshold from 100k to 10M to correctly handle MI300X (192 GB = 196608 MB) and other high-VRAM GPUs - amd.py visible GPU: use AMD-reported GPU IDs instead of enumerate index so non-dense sets like CUDA_VISIBLE_DEVICES=1,3 report correctly - install.sh: add ROCm <6.0 minimum version guard (no PyTorch wheels exist for older versions); fix rocm7.1* glob to not match rocm7.10+ - is_rdna: add gfx1033-1036 for RDNA2 mobile GPUs (RX 6600M etc.) - worker.py: increase ROCm source build timeout from 600s to 1800s; fix success log message for ROCm source builds - Tests: update mocks for _has_usable_nvidia_gpu, add RDNA2 target asserts * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Add HIP_VISIBLE_DEVICES support, unit-aware VRAM parsing, Windows GPU validation - hardware.py: check HIP_VISIBLE_DEVICES and ROCR_VISIBLE_DEVICES on ROCm before falling back to CUDA_VISIBLE_DEVICES, so multi-GPU AMD setups with HIP-specific env vars report the correct visible device set - amd.py: add _parse_memory_mb() that reads "unit" from dict-shaped amd-smi JSON (e.g. {"value": 192, "unit": "GiB"}) and converts to MB correctly; fixes MI300X VRAM misreported as 0.19 GB instead of 192 GB - install_python_stack.py: Windows AMD warning now validates actual GPU presence via hipinfo/amd-smi output markers before printing - install_llama_prebuilt.py: restore amdhip64.dll fallback for Windows HIP detection after tool-based checks, so Windows HIP installs without CLI tools on PATH are still detected - hardware.py: fix IS_ROCM comment to accurately describe its role * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Fix HIP_VISIBLE_DEVICES empty-string handling in GPU visibility spec Use explicit None checks instead of Python `or` operator when reading HIP_VISIBLE_DEVICES / ROCR_VISIBLE_DEVICES, so that an empty string ("") is correctly honored as "no visible GPUs" rather than silently falling through to CUDA_VISIBLE_DEVICES on mixed ROCm+CUDA systems. * Fix IS_ROCM test assertion for multi-line formatting * Cap torchvision/torchaudio versions, remove amdhip64.dll fallback, fix visible GPU count - Cap torchvision<0.26.0 and torchaudio<2.11.0 alongside torch<2.11.0 in both install.sh and install_python_stack.py to prevent resolver from selecting incompatible companion packages from ROCm wheel index - Remove amdhip64.dll fallback in Windows ROCm detection (DLL presence without hipinfo/amd-smi is not proof of GPU existence) - Fix get_visible_gpu_count() to use _get_parent_visible_gpu_spec() which respects HIP_VISIBLE_DEVICES/ROCR_VISIBLE_DEVICES on ROCm hosts * Attribute is_rdna() RDNA2/3/3.5/4 expansion to PR #4428 The is_rdna() expansion to cover RDNA2 (gfx1030-1036), RDNA3 (gfx1100-1103), RDNA3.5 (gfx1150-1152), and RDNA4 (gfx1200-1201) architectures is based on the original work from PR #4428. Co-authored-by: GoldenGrapeGentleman <yueyuan@amd.com> Co-authored-by: billishyahao <bill.he@amd.com> * Support AMD Radeon for studio (#4770) Co-authored-by: Iswarya Alex <iswarya.alex@amd.com> * Remove ROCm test files from main PR Move test_rocm_support.py and shell test additions to a separate PR to keep the main ROCm support PR focused on implementation changes. * Fix installer and hardware detection issues for PR #4720 - Fix empty _tri_arg passed to uv pip install in Radeon path (causes "Empty field is not allowed for PEP508" error) - Fix Radeon fallback: use ROCm index instead of CPU-only when repo.radeon.com is unreachable (TORCH_INDEX_URL already has ROCm) - Use $TORCH_CONSTRAINT in fallback paths instead of hardcoded strings - Fix _pick_radeon_wheel: relax suffix to match manylinux_2_28_x86_64 wheels (AMD Radeon repo does not use bare linux_x86_64 platform tag) - Fix IS_ROCM export: use __getattr__ so callers always see the live value after detect_hardware() runs - Fix apply_gpu_ids: set HIP_VISIBLE_DEVICES and ROCR_VISIBLE_DEVICES on ROCm so _get_parent_visible_gpu_spec picks up narrowed GPU set - Fix _parse_memory_mb: distinguish GB (1000 MB) from GiB (1024 MiB) - Add amd-smi version as a fallback in _detect_rocm_version - Fix trailing whitespace and missing newline at EOF in install.sh * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Fix GPU detection false positives and add missing health groups - Fix _has_rocm_gpu() false positive: require "GPU: <number>" data rows from amd-smi list, not just header containing "gpu" - Apply same fix in detect_host() in install_llama_prebuilt.py - Add runtime_payload_health_groups for linux-rocm and windows-hip so partial/corrupt ROCm/HIP prebuilt installs are properly detected - Add bitsandbytes install to Radeon fallback paths (was only in the success path, skipped when repo.radeon.com was unreachable) - Keep DEVICE/CHAT_ONLY as direct imports in __init__.py (matching main) and only use __getattr__ for IS_ROCM * Fix _ensure_rocm_torch and Windows AMD warning false positives - _ensure_rocm_torch: only skip when HIP is already present, not for CUDA builds (which are unusable on AMD-only hosts). Fixes the case where a venv has a stale CUDA wheel and the repair step is skipped. - Windows AMD warning: use GPU data row check (same as Linux fix) to avoid false positives from amd-smi list header-only output. * Fix amd-smi GPU detection for GPU[N] output format Older amd-smi versions output "GPU[0] : Card series: ..." instead of "GPU: 0". The regex now matches both "GPU: <digit>" and "GPU[<digit>" formats to detect actual GPU data rows. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Harden AMD GPU detection against false positives - install.sh: replace weak amd-smi list check (awk 'NR>1 && NF') with strict pattern matching GPU data rows (/^GPU[[:space:]]*[:\[]/) - All files: reject rocminfo gfx000 (CPU HSA agent) by requiring gfx[1-9] instead of gfx[0-9] in the rocminfo GPU probe - Fixes false positives on hosts with ROCm tools but no AMD GPU * Remove duplicate comment from pre-commit merge * Refactor: deduplicate AMD detection, consolidate bitsandbytes, clean up imports - Extract _has_amd_rocm_gpu() shell function to avoid duplicating the rocminfo/amd-smi GPU detection logic in get_torch_index_url and the Radeon auto-detect block - Consolidate bitsandbytes install into a single case block after torch install (was duplicated 4 times across Radeon success/fallback paths) - Move math and re imports to top of amd.py (were inline in functions) - Add _smi_query() helper in hardware.py to centralize IS_ROCM backend selection for get_gpu_utilization and get_visible_gpu_utilization Addresses Gemini code review suggestions. * Fix VRAM parsing for string values and GB/GiB consistency - Extract unit from string-valued VRAM fields (e.g. "192 GiB") so _parse_memory_mb correctly applies the unit multiplier instead of treating the value as bare MB - Treat GB and GiB identically (both as binary x1024) since GPU tools including amd-smi use binary units even when labeling them "GB" - Fixes incorrect VRAM reporting on MI300-class cards (was showing ~0.19 GB instead of 192 GB for string-valued outputs) * Add --no-cache to uv for ROCm HIP source builds Avoid stale cache artifacts from partial HIP source builds when uv is used for causal-conv1d/mamba-ssm compilation on ROCm. The pip path already uses --no-cache-dir; this adds the uv equivalent (--no-cache) only when is_hip is True. * Fix critical: initialize _amd_gpu_radeon before case block _amd_gpu_radeon was only set inside the */rocm*) case arm, so on NVIDIA/CPU/macOS paths where TORCH_INDEX_URL does not contain "rocm", the variable was unbound. With set -u (nounset) enabled, this crashes the installer for every non-AMD user. Move initialization to before the case block so it is always defined. * Fix Windows AMD: route has_rocm hosts to HIP prebuilt path resolve_release_asset_choice was selecting windows-cpu for all Windows x86_64 hosts including those with has_rocm=True. Windows AMD users should fall through to resolve_upstream_asset_choice which tries the HIP prebuilt first. Add "not host.has_rocm" guard to the published windows-cpu selection. * Harden ROCm detection, Radeon wheel fallback, and HIP visibility Addresses review findings from parallel reviewers on PR #4720: - install.sh: add _has_usable_nvidia_gpu() helper requiring nvidia-smi -L to actually list a GPU before treating the host as NVIDIA. Fixes the stale-nvidia-smi-on-PATH regression where AMD-only hosts fell into the CUDA branch. - install.sh: fix hipconfig awk blocks to propagate a non-zero exit code when the output is not a recognisable version string, so the ||-chain continues to dpkg-query / rpm instead of terminating early. - install.sh: fail-closed on Radeon wheel fallback. When torch, torchvision or torchaudio is missing from the Radeon repo for the active Python tag, fall back to the standard ROCm index instead of silently mixing Radeon wheels with PyPI defaults. Quote all wheel arguments individually so wheel filenames cannot be word-split or glob-expanded. - install_llama_prebuilt.py: detect_host() now requires nvidia-smi -L to list a GPU before setting has_physical_nvidia. Routes AMD ROCm hosts with a broken leftover nvidia-smi to the ROCm path instead of misclassifying them as NVIDIA. - install_llama_prebuilt.py: scan upstream assets for any rocm-<version> prebuilt instead of hard-coding rocm-7.2, so ROCm 6.x / 7.0 / 7.1 / 7.3+ users pick up a matching upstream prebuilt when one exists. - install_llama_prebuilt.py: validate_server() adds --n-gpu-layers 1 for linux-rocm and windows-hip hosts, so new HIP prebuilts are preflighted on the GPU path instead of passing validation on CPU only. - install_llama_prebuilt.py: restore the published windows-cpu fallback for AMD Windows hosts without a HIP prebuilt so hash-approved bundles are still preferred over the raw upstream CPU asset. - install_python_stack.py: drop the /opt/rocm / hipcc gate in _ensure_rocm_torch() and rely on _has_rocm_gpu(). Runtime-only ROCm installs (package-managed minimal installs, Radeon software) that ship amd-smi / rocminfo without hipcc can now repair a CPU-only venv via "unsloth studio update". Adds an explicit IS_WINDOWS / IS_MACOS guard. - studio/backend/utils/hardware/amd.py: honour HIP_VISIBLE_DEVICES / ROCR_VISIBLE_DEVICES / CUDA_VISIBLE_DEVICES in get_primary_gpu_utilization(). A process restricted to GPU 2 now reports metrics for GPU 2 instead of physical GPU 0. Tighten the plain bytes unit detection to an explicit allowlist. - studio/backend/utils/hardware/hardware.py: route get_backend_visible_gpu_info()'s backend_cuda_visible_devices field through a helper that reads HIP_VISIBLE_DEVICES on ROCm. Drop the unconditional "(rocm=False)" suffix in apply_gpu_ids() logs. * Fix round 2 regressions: ROCm validate_server and Windows HIP routing Follow-up to |
||
|---|---|---|
| .github | ||
| images | ||
| scripts | ||
| studio | ||
| tests | ||
| unsloth | ||
| unsloth_cli | ||
| .gitattributes | ||
| .gitignore | ||
| .pre-commit-ci.yaml | ||
| .pre-commit-config.yaml | ||
| build.sh | ||
| cli.py | ||
| CODE_OF_CONDUCT.md | ||
| CONTRIBUTING.md | ||
| COPYING | ||
| install.ps1 | ||
| install.sh | ||
| install_gemma4_mlx.sh | ||
| LICENSE | ||
| pyproject.toml | ||
| README.md | ||
| unsloth-cli.py | ||

Run and train AI models with a unified local interface.
Features • Quickstart • Notebooks • Documentation • Reddit
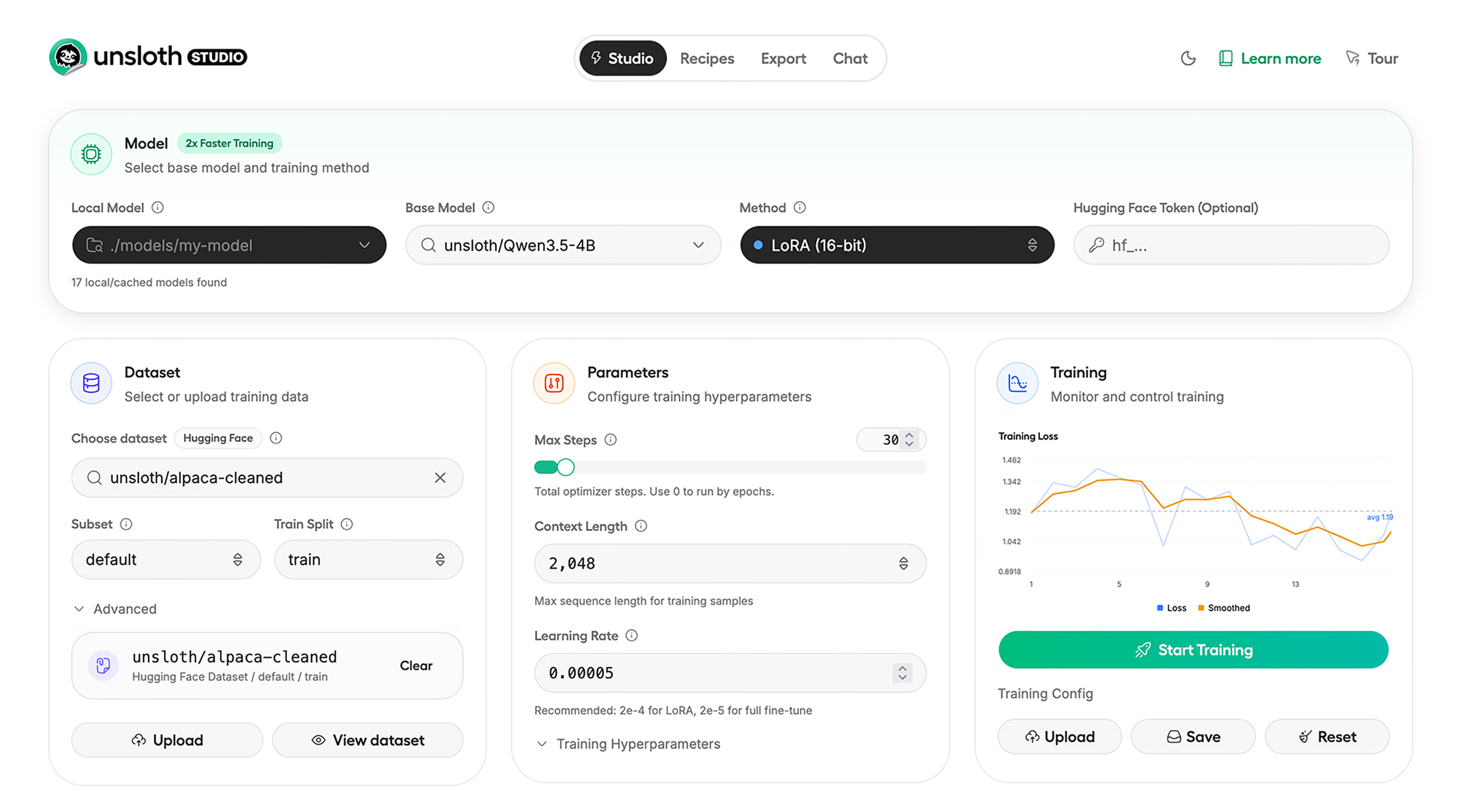
Unsloth Studio (Beta) lets you run and train text, audio, embedding, vision models on Windows, Linux and macOS.
⭐ Features
Unsloth provides several key features for both inference and training:
Inference
- Search + download + run models including GGUF, LoRA adapters, safetensors
- Export models: Save or export models to GGUF, 16-bit safetensors and other formats.
- Tool calling: Support for self-healing tool calling and web search
- Code execution: lets LLMs test code in Claude artifacts and sandbox environments
- Auto-tune inference parameters and customize chat templates.
- We work directly with teams behind gpt-oss, Qwen3, Llama 4, Mistral, Gemma 1-3, and Phi-4, where we’ve fixed bugs that improve model accuracy.
- Upload images, audio, PDFs, code, DOCX and more file types to chat with.
Training
- Train and RL 500+ models up to 2x faster with up to 70% less VRAM, with no accuracy loss.
- Custom Triton and mathematical kernels. See some collabs we did with PyTorch and Hugging Face.
- Data Recipes: Auto-create datasets from PDF, CSV, DOCX etc. Edit data in a visual-node workflow.
- Reinforcement Learning (RL): The most efficient RL library, using 80% less VRAM for GRPO, FP8 etc.
- Supports full fine-tuning, RL, pretraining, 4-bit, 16-bit and, FP8 training.
- Observability: Monitor training live, track loss and GPU usage and customize graphs.
- Multi-GPU training is supported, with major improvements coming soon.
⚡ Quickstart
Unsloth can be used in two ways: through Unsloth Studio, the web UI, or through Unsloth Core, the code-based version. Each has different requirements.
Unsloth Studio (web UI)
Unsloth Studio (Beta) works on Windows, Linux, WSL and macOS.
- CPU: Supported for Chat and Data Recipes currently
- NVIDIA: Training works on RTX 30/40/50, Blackwell, DGX Spark, Station and more
- macOS: Currently supports chat and Data Recipes. MLX training is coming very soon
- AMD: Chat + Data works. Train with Unsloth Core. Studio support is out soon.
- Coming soon: Training support for Apple MLX, AMD, and Intel.
- Multi-GPU: Available now, with a major upgrade on the way
macOS, Linux, WSL:
curl -fsSL https://unsloth.ai/install.sh | sh
Windows:
irm https://unsloth.ai/install.ps1 | iex
Launch
unsloth studio -H 0.0.0.0 -p 8888
Update
To update, use the same install commands as above. Or run (does not work on Windows):
unsloth studio update
Docker
Use our Docker image unsloth/unsloth container. Run:
docker run -d -e JUPYTER_PASSWORD="mypassword" \
-p 8888:8888 -p 8000:8000 -p 2222:22 \
-v $(pwd)/work:/workspace/work \
--gpus all \
unsloth/unsloth
Developer, Nightly, Uninstall
To see developer, nightly and uninstallation etc. instructions, see advanced installation.
Unsloth Core (code-based)
Linux, WSL:
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv unsloth_env --python 3.13
source unsloth_env/bin/activate
uv pip install unsloth --torch-backend=auto
Windows:
winget install -e --id Python.Python.3.13
winget install --id=astral-sh.uv -e
uv venv unsloth_env --python 3.13
.\unsloth_env\Scripts\activate
uv pip install unsloth --torch-backend=auto
For Windows, pip install unsloth works only if you have PyTorch installed. Read our Windows Guide.
You can use the same Docker image as Unsloth Studio.
AMD, Intel:
For RTX 50x, B200, 6000 GPUs: uv pip install unsloth --torch-backend=auto. Read our guides for: Blackwell and DGX Spark.
To install Unsloth on AMD and Intel GPUs, follow our AMD Guide and Intel Guide.
📒 Free Notebooks
Train for free with our notebooks. You can use our new free Unsloth Studio notebook to run and train models for free in a web UI. Read our guide. Add dataset, run, then deploy your trained model.
| Model | Free Notebooks | Performance | Memory use |
|---|---|---|---|
| Gemma 4 (E2B) | ▶️ Start for free | 1.5x faster | 50% less |
| Qwen3.5 (4B) | ▶️ Start for free | 1.5x faster | 60% less |
| gpt-oss (20B) | ▶️ Start for free | 2x faster | 70% less |
| Qwen3.5 GSPO | ▶️ Start for free | 2x faster | 70% less |
| gpt-oss (20B): GRPO | ▶️ Start for free | 2x faster | 80% less |
| Qwen3: Advanced GRPO | ▶️ Start for free | 2x faster | 70% less |
| embeddinggemma (300M) | ▶️ Start for free | 2x faster | 20% less |
| Mistral Ministral 3 (3B) | ▶️ Start for free | 1.5x faster | 60% less |
| Llama 3.1 (8B) Alpaca | ▶️ Start for free | 2x faster | 70% less |
| Llama 3.2 Conversational | ▶️ Start for free | 2x faster | 70% less |
| Orpheus-TTS (3B) | ▶️ Start for free | 1.5x faster | 50% less |
- See all our notebooks for: Kaggle, GRPO, TTS, embedding & Vision
- See all our models and all our notebooks
- See detailed documentation for Unsloth here
🦥 Unsloth News
- Gemma 4: Run and train Google’s new models directly in Unsloth Studio! Blog
- Introducing Unsloth Studio: our new web UI for running and training LLMs. Blog
- Qwen3.5 - 0.8B, 2B, 4B, 9B, 27B, 35-A3B, 112B-A10B are now supported. Guide + notebooks
- Train MoE LLMs 12x faster with 35% less VRAM - DeepSeek, GLM, Qwen and gpt-oss. Blog
- Embedding models: Unsloth now supports ~1.8-3.3x faster embedding fine-tuning. Blog • Notebooks
- New 7x longer context RL vs. all other setups, via our new batching algorithms. Blog
- New RoPE & MLP Triton Kernels & Padding Free + Packing: 3x faster training & 30% less VRAM. Blog
- 500K Context: Training a 20B model with >500K context is now possible on an 80GB GPU. Blog
- FP8 & Vision RL: You can now do FP8 & VLM GRPO on consumer GPUs. FP8 Blog • Vision RL
- gpt-oss by OpenAI: Read our RL blog, Flex Attention blog and Guide.
📥 Advanced Installation
The below advanced instructions are for Unsloth Studio. For Unsloth Core advanced installation, view our docs.
Developer installs: macOS, Linux, WSL:
git clone https://github.com/unslothai/unsloth
cd unsloth
./install.sh --local
unsloth studio -H 0.0.0.0 -p 8888
Then to update :
unsloth studio update
Developer installs: Windows PowerShell:
git clone https://github.com/unslothai/unsloth.git
cd unsloth
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\install.ps1 --local
unsloth studio -H 0.0.0.0 -p 8888
Then to update :
unsloth studio update
Nightly: MacOS, Linux, WSL:
git clone https://github.com/unslothai/unsloth
cd unsloth
git checkout nightly
./install.sh --local
unsloth studio -H 0.0.0.0 -p 8888
Then to launch every time:
unsloth studio -H 0.0.0.0 -p 8888
Nightly: Windows:
Run in Windows Powershell:
git clone https://github.com/unslothai/unsloth.git
cd unsloth
git checkout nightly
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\install.ps1 --local
unsloth studio -H 0.0.0.0 -p 8888
Then to launch every time:
unsloth studio -H 0.0.0.0 -p 8888
Uninstall
You can uninstall Unsloth Studio by deleting its install folder usually located under $HOME/.unsloth/studio on Mac/Linux/WSL and %USERPROFILE%\.unsloth\studio on Windows. Using the rm -rf commands will delete everything, including your history, cache:
- MacOS, WSL, Linux:
rm -rf ~/.unsloth/studio - Windows (PowerShell):
Remove-Item -Recurse -Force "$HOME\.unsloth\studio"
For more info, see our docs.
Deleting model files
You can delete old model files either from the bin icon in model search or by removing the relevant cached model folder from the default Hugging Face cache directory. By default, HF uses:
- MacOS, Linux, WSL:
~/.cache/huggingface/hub/ - Windows:
%USERPROFILE%\.cache\huggingface\hub\
💚 Community and Links
| Type | Links |
|---|---|
| Join Discord server | |
| Join Reddit community | |
| 📚 Documentation & Wiki | Read Our Docs |
| Follow us on X | |
| 🔮 Our Models | Unsloth Catalog |
| ✍️ Blog | Read our Blogs |
Citation
You can cite the Unsloth repo as follows:
@software{unsloth,
author = {Daniel Han, Michael Han and Unsloth team},
title = {Unsloth},
url = {https://github.com/unslothai/unsloth},
year = {2023}
}
If you trained a model with 🦥Unsloth, you can use this cool sticker!
License
Unsloth uses a dual-licensing model of Apache 2.0 and AGPL-3.0. The core Unsloth package remains licensed under Apache 2.0, while certain optional components, such as the Unsloth Studio UI are licensed under the open-source license AGPL-3.0.
This structure helps support ongoing Unsloth development while keeping the project open source and enabling the broader ecosystem to continue growing.
Thank You to
- The llama.cpp library that lets users run and save models with Unsloth
- The Hugging Face team and their libraries: transformers and TRL
- The Pytorch and Torch AO team for their contributions
- NVIDIA for their NeMo DataDesigner library and their contributions
- And of course for every single person who has contributed or has used Unsloth!