* Chat-template repair: warn-by-default, AST classification, dict support Follow-up hardening on top of PR #4426 (which fixed the #4150 RuntimeError for ChatML LoRA reloads). Behavior changes: - Warn-by-default instead of RuntimeError. When fix_chat_template cannot repair a broken template, emit a warning and return the original. Set UNSLOTH_STRICT_CHAT_TEMPLATE=1 to restore the pre-warn hard fail. Fixes the UX where a missing `{% if add_generation_prompt %}` block on a saved LoRA (typical after LlamaFactory / Axolotl re-serialize) would block model loading entirely. - Local path vs HF hub distinguished in the warning message. For local paths the message points at the likely downstream tool; for HF IDs it points at the upstream model maintainers. Previously both said "file a bug report to the maintainers of <path>" even when <path> was the user's own saves/ directory. - Dict / list chat_template now handled. Hermes-3 ships with {default, tool_use} and the previous code crashed with AttributeError: 'dict' object has no attribute 'find' when entering _fix_chat_template with a dict. Each variant is now fixed independently; structure is preserved. Internals: - _find_end_position now matches all four Jinja whitespace-control variants ({% %}, {%- %}, {% -%}, {%- -%}) and returns the rightmost endfor/endif so multi-for templates aren't locked onto the first loop. Previously {%- endfor -%} (both-side dash, used by Qwen3-Guard) was silently bypassed. - _has_add_generation_prompt_block uses Jinja AST via jinja2.nodes.If/Name walks instead of substring matching, so templates that hide the block behind comments or dash-style variants are classified correctly. - _template_ends_with_toplevel_for gates the GH#4150 ChatML repair on the AST: only fires when the last structural top-level node is a For (standard ChatML shape), ignoring trailing pure-whitespace output nodes. Templates wrapped in an outer If (Qwen3-Guard) are now explicitly skipped at the _fix_chat_template level as well, not just at load_correct_tokenizer's name-based exemption. - _validate_patched_template renders the patched template with and without add_generation_prompt and confirms the patched output responds to the flag by appending (not replacing) content. If validation fails, the patch is discarded and we fall through to the warn path. Verified with an expanded regression suite in tests/: - test_fix_chat_template_pr4426.py: 42/42 template-matrix cells - test_load_correct_tokenizer_pr4426.py: 5/5 tokenizer loads - test_chat_template_followups.py: 10/10 new follow-up tests - test_mistral_pr4426.py: 5 Mistral variants byte-identical - test_qwen_pr4426.py: 14 Qwen variants byte-identical (Qwen1.5, Qwen2, Qwen2.5-Instruct/Coder/Math/VL, Qwen3, Qwen3-Coder, QwQ, Qwen3-Guard-Gen) * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Guard _validate_patched_template against read-only chat_template If tokenizer.chat_template is a property or otherwise read-only, the validation helper would crash with AttributeError when trying to temporarily set the patched template. Catch the assignment failure and return False (skip validation), and best-effort restore in the finally block. * Replace regex separator inference with render-diff; broaden repair to non-ChatML templates The previous `_infer_assistant_separator` was a four-tier regex heuristic that only worked on ChatML-shaped templates and forced a hard `<|im_start|>` / `<|im_end|>` presence gate on Case 2 repair. This meant a Llama-3, Gemma, or Phi-3 template stripped of its generation-prompt block by a downstream tool (LlamaFactory, Axolotl, etc.) would still warn-and-return even though the structural shape is identical to the ChatML case the PR already handles. This replaces the regex with `_derive_assistant_prefix_by_render`: render the template with two dialogs that differ only in assistant content, then `os.path.commonprefix` on the tails captures the exact assistant-turn prefix the template emits. The template itself is ground truth, so non-ChatML shapes work as long as the assistant block is a literal the template emits once per message. Three guards keep the derivation safe: A. both assistant renders extend the base render (no reordering); B. the divergence point is exactly the content-insertion site (sentinel follows the common prefix); C. a user-role cross-check: if a render with a user sentinel also emits the same prefix, role has no effect on output and we reject. A render failure on [user, user] (e.g. Gemma's `raise_exception` alternation check) is evidence that role matters; we accept. Sentinels differ at character 0 so `commonprefix` cannot absorb them, and trailing whitespace/comments after the last `{% endfor %}` are stripped before probing (they would appear in base but not after the appended assistant turn and break Guard A). `_fix_chat_template` and `_repair_string_template` now thread an `is_sharegpt` kwarg; `_fix_chat_template` retries once with `is_sharegpt=True` if the first probe returns None (dual-probe fallback for dict/list callers). The ChatML `<|im_start|>` / `<|im_end|>` hard gate in Case 2 is dropped. `_infer_assistant_separator` is deleted. Verified via: - tests/test_fix_chat_template_pr4426.py: 51/51 cells (new Llama-3, Gemma, Phi-3 broken-template rows all repair FIX-OK) - tests/test_load_correct_tokenizer_pr4426.py: 5/5 - tests/test_chat_template_followups.py: 18/18 (T11-T18 cover non-ChatML repair + probe failure modes) - tests/test_mistral_pr4426.py: 5/5 byte-identical - tests/test_qwen_pr4426.py: 14/14 byte-identical (Qwen3-Guard AST gate still rejects) - tests/hermes3_lora_pr4426.py reload: patched template ends with `<|im_start|>assistant\n`, inference returns sensible output. - temp/sim/battery.py: 79/79 followup; vs baseline: 0 regressions, 9 improvements. - Spot-check probe on real stripped tokenizers (Hermes-3, Phi-4, Llama-3.2-1B, Gemma-3-1B): all derive the expected prefix. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Address reviewer findings: variant routing, positive-gate detection, comment-safe end scan Resolves three reviewer findings on PR #5049 (`fix/chat-template-followups`): Finding #1 [10/10]: dict/list variants now route through `_fix_chat_template_for_tokenizer` via a new `_VariantTokenizerProxy` adapter. Previously the dict/list branches called `_fix_chat_template` directly, silently bypassing the warn/strict (`UNSLOTH_STRICT_CHAT_TEMPLATE`) contract, the `no == yes` diagnostic, broken-existing-block detection, and `_validate_patched_template` guard. The proxy swaps `base.chat_template` to the variant string before each `apply_chat_template` call so tokenizer globals (`bos_token`, custom filters, `raise_exception`) remain available; if the base is read-only it falls back to isolated Jinja rendering. Finding #2 [1/10]: `_has_add_generation_prompt_block` now requires the `If` body to contain at least one `Output` node (a new `_if_body_emits_content` helper walks descendants). This distinguishes a real generation-prompt block from a header guard like `{% if not add_generation_prompt is defined %}{% set ... %}{% endif %}` (body contains only `Assign`) which references the name but emits nothing. Also dropped a now-redundant `"add_generation_prompt" not in scrubbed` guard in `_fix_chat_template` Case 2 so header-guarded templates still get repaired. Finding #4 [1/10]: `_find_end_position` now replaces Jinja comments with equal-length whitespace before scanning for `{% endfor %}` / `{% endif %}` tokens. This prevents a trailing comment containing those tokens from being picked as the real end tag. Positions in the padded string map 1:1 to positions in the original template. Tests: - tests/test_chat_template_followups.py: 21/21 (T19 strict-mode dict variant, T20 header-guard repair, T21 comment-endfor trap added; T4/T5 stubs updated with a working apply_chat_template that routes through Jinja). - tests/test_fix_chat_template_pr4426.py: 51/51 cells unchanged. - tests/test_load_correct_tokenizer_pr4426.py: 5/5. - tests/test_mistral_pr4426.py: 5/5 byte-identical. - tests/test_qwen_pr4426.py: 14/14 byte-identical. - temp/sim/battery.py: 79/79 followup; 0 regressions vs baseline. - Phase 3 Hermes-3 broken-LoRA reload: inference still returns `'The answer to the equation 2+2 is 4.'`. - Spot-checks on Hermes-3 / Phi-4 / Llama-3.2-1B / Gemma-3-1B real stripped templates: probe still derives the expected prefix. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Tighten comments in chat-template helpers Pure comment minimization across `_find_end_position`, `_has_add_generation_prompt_block`, `_if_body_emits_content`, `_derive_assistant_prefix_by_render`, `_fix_chat_template` Case 2, and `_VariantTokenizerProxy`. No behavior change; same intent, fewer lines. All 21 follow-up tests and the 51-cell Phase 1 matrix still pass. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Sandbox probe, fix is_sharegpt validator mismatch, reject negated gates Three real bugs from the 10-agent Opus review: 1. Probe now uses `jinja2.sandbox.SandboxedEnvironment` instead of bare `jinja2.Environment`. The probe renders at model-load time (before the user calls `apply_chat_template`), so it was a new eager code-execution surface that the base HF tokenizer loading does not have. SandboxedEnvironment blocks attribute-chain exploits at negligible cost. 2. `_repair_string_template` now tries validation with both `is_sharegpt=False` and `is_sharegpt=True`. Previously, when `_fix_chat_template` internally fell back to the other schema via its dual-probe, the outer validation still used the caller's original `is_sharegpt` -- rendering with the wrong message keys and spuriously dropping a valid repair. 3. `_has_add_generation_prompt_block` now skips `If` nodes whose test is a `Not` expression. A negated gate like `{% if not add_generation_prompt %}{{ x }}{% endif %}` fires when agp=False, so its emitting body is not a generation block -- but the old code counted any Name reference regardless of polarity. Cleanup: removed unused `self._label`, added `\r` escape in generation-block literal, switched variant labels to `!r` formatting, removed redundant `import os as _os`. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Fix jinja2.sandbox import and sandbox proxy fallback Two critical findings from the 20-reviewer pass: 1. [20/20] The proxy read-only fallback used bare `jinja2.Environment`, not sandboxed. All 20 reviewers independently reproduced marker-file creation via `cycler.__init__.__globals__['os'].system(...)` during `fix_chat_template()`. Fixed: fallback now uses `from jinja2.sandbox import SandboxedEnvironment`. 2. [14/20] The render-diff probe did `import jinja2` then referenced `jinja2.sandbox.SandboxedEnvironment`. `jinja2.sandbox` is a submodule that is NOT auto-imported by `import jinja2` on Jinja 3.1.6. This caused `AttributeError` (swallowed by `except Exception`), making the entire Case 2 repair path silently return None in a clean process. The 6 reviewers who saw it work had `jinja2.sandbox` pre-imported by an earlier module in their process. Fixed: both the probe and the proxy fallback now use `from jinja2.sandbox import SandboxedEnvironment`. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci --------- Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> |
||
|---|---|---|
| .github | ||
| images | ||
| scripts | ||
| studio | ||
| tests | ||
| unsloth | ||
| unsloth_cli | ||
| .gitattributes | ||
| .gitignore | ||
| .pre-commit-ci.yaml | ||
| .pre-commit-config.yaml | ||
| build.sh | ||
| cli.py | ||
| CODE_OF_CONDUCT.md | ||
| CONTRIBUTING.md | ||
| COPYING | ||
| install.ps1 | ||
| install.sh | ||
| LICENSE | ||
| pyproject.toml | ||
| README.md | ||
| unsloth-cli.py | ||

Run and train AI models with a unified local interface.
Features • Quickstart • Notebooks • Documentation • Reddit
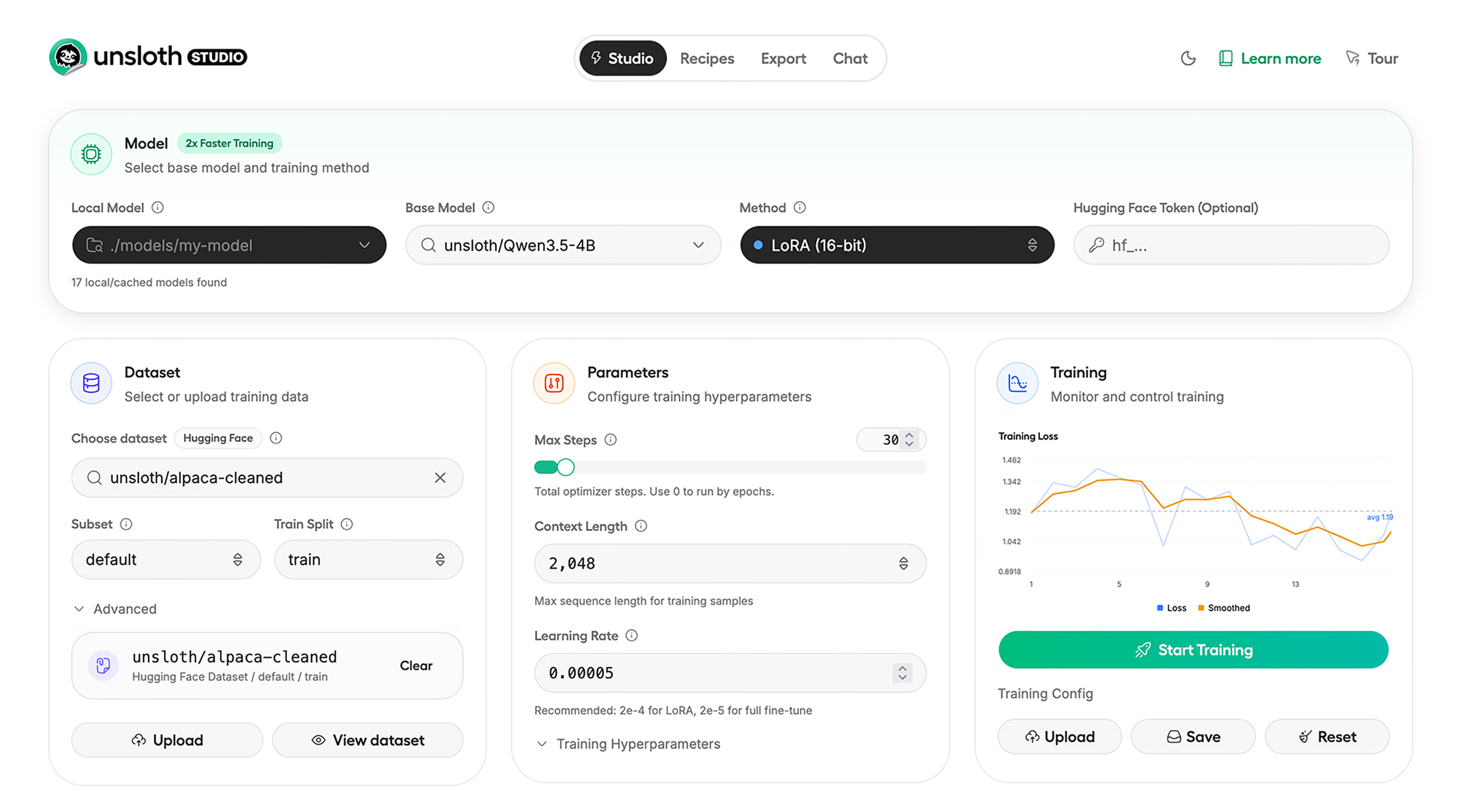
Unsloth Studio (Beta) lets you run and train text, audio, embedding, vision models on Windows, Linux and macOS.
⭐ Features
Unsloth provides several key features for both inference and training:
Inference
- Search + download + run models including GGUF, LoRA adapters, safetensors
- Export models: Save or export models to GGUF, 16-bit safetensors and other formats.
- Tool calling: Support for self-healing tool calling and web search
- Code execution: lets LLMs test code in Claude artifacts and sandbox environments
- Auto-tune inference parameters and customize chat templates.
- We work directly with teams behind gpt-oss, Qwen3, Llama 4, Mistral, Gemma 1-3, and Phi-4, where we’ve fixed bugs that improve model accuracy.
- Upload images, audio, PDFs, code, DOCX and more file types to chat with.
Training
- Train and RL 500+ models up to 2x faster with up to 70% less VRAM, with no accuracy loss.
- Custom Triton and mathematical kernels. See some collabs we did with PyTorch and Hugging Face.
- Data Recipes: Auto-create datasets from PDF, CSV, DOCX etc. Edit data in a visual-node workflow.
- Reinforcement Learning (RL): The most efficient RL library, using 80% less VRAM for GRPO, FP8 etc.
- Supports full fine-tuning, RL, pretraining, 4-bit, 16-bit and, FP8 training.
- Observability: Monitor training live, track loss and GPU usage and customize graphs.
- Multi-GPU training is supported, with major improvements coming soon.
⚡ Quickstart
Unsloth can be used in two ways: through Unsloth Studio, the web UI, or through Unsloth Core, the code-based version. Each has different requirements.
Unsloth Studio (web UI)
Unsloth Studio (Beta) works on Windows, Linux, WSL and macOS.
- CPU: Supported for Chat and Data Recipes currently
- NVIDIA: Training works on RTX 30/40/50, Blackwell, DGX Spark, Station and more
- macOS: Currently supports chat and Data Recipes. MLX training is coming very soon
- AMD: Chat + Data works. Train with Unsloth Core. Studio support is out soon.
- Coming soon: Training support for Apple MLX, AMD, and Intel.
- Multi-GPU: Available now, with a major upgrade on the way
macOS, Linux, WSL:
curl -fsSL https://unsloth.ai/install.sh | sh
Windows:
irm https://unsloth.ai/install.ps1 | iex
Launch
unsloth studio -H 0.0.0.0 -p 8888
Update
To update, use the same install commands as above. Or run (does not work on Windows):
unsloth studio update
Docker
Use our Docker image unsloth/unsloth container. Run:
docker run -d -e JUPYTER_PASSWORD="mypassword" \
-p 8888:8888 -p 8000:8000 -p 2222:22 \
-v $(pwd)/work:/workspace/work \
--gpus all \
unsloth/unsloth
Developer, Nightly, Uninstall
To see developer, nightly and uninstallation etc. instructions, see advanced installation.
Unsloth Core (code-based)
Linux, WSL:
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv unsloth_env --python 3.13
source unsloth_env/bin/activate
uv pip install unsloth --torch-backend=auto
Windows:
winget install -e --id Python.Python.3.13
winget install --id=astral-sh.uv -e
uv venv unsloth_env --python 3.13
.\unsloth_env\Scripts\activate
uv pip install unsloth --torch-backend=auto
For Windows, pip install unsloth works only if you have PyTorch installed. Read our Windows Guide.
You can use the same Docker image as Unsloth Studio.
AMD, Intel:
For RTX 50x, B200, 6000 GPUs: uv pip install unsloth --torch-backend=auto. Read our guides for: Blackwell and DGX Spark.
To install Unsloth on AMD and Intel GPUs, follow our AMD Guide and Intel Guide.
📒 Free Notebooks
Train for free with our notebooks. You can use our new free Unsloth Studio notebook to run and train models for free in a web UI. Read our guide. Add dataset, run, then deploy your trained model.
| Model | Free Notebooks | Performance | Memory use |
|---|---|---|---|
| Gemma 4 (E2B) | ▶️ Start for free | 1.5x faster | 50% less |
| Qwen3.5 (4B) | ▶️ Start for free | 1.5x faster | 60% less |
| gpt-oss (20B) | ▶️ Start for free | 2x faster | 70% less |
| Qwen3.5 GSPO | ▶️ Start for free | 2x faster | 70% less |
| gpt-oss (20B): GRPO | ▶️ Start for free | 2x faster | 80% less |
| Qwen3: Advanced GRPO | ▶️ Start for free | 2x faster | 70% less |
| embeddinggemma (300M) | ▶️ Start for free | 2x faster | 20% less |
| Mistral Ministral 3 (3B) | ▶️ Start for free | 1.5x faster | 60% less |
| Llama 3.1 (8B) Alpaca | ▶️ Start for free | 2x faster | 70% less |
| Llama 3.2 Conversational | ▶️ Start for free | 2x faster | 70% less |
| Orpheus-TTS (3B) | ▶️ Start for free | 1.5x faster | 50% less |
- See all our notebooks for: Kaggle, GRPO, TTS, embedding & Vision
- See all our models and all our notebooks
- See detailed documentation for Unsloth here
🦥 Unsloth News
- Gemma 4: Run and train Google’s new models directly in Unsloth Studio! Blog
- Introducing Unsloth Studio: our new web UI for running and training LLMs. Blog
- Qwen3.5 - 0.8B, 2B, 4B, 9B, 27B, 35-A3B, 112B-A10B are now supported. Guide + notebooks
- Train MoE LLMs 12x faster with 35% less VRAM - DeepSeek, GLM, Qwen and gpt-oss. Blog
- Embedding models: Unsloth now supports ~1.8-3.3x faster embedding fine-tuning. Blog • Notebooks
- New 7x longer context RL vs. all other setups, via our new batching algorithms. Blog
- New RoPE & MLP Triton Kernels & Padding Free + Packing: 3x faster training & 30% less VRAM. Blog
- 500K Context: Training a 20B model with >500K context is now possible on an 80GB GPU. Blog
- FP8 & Vision RL: You can now do FP8 & VLM GRPO on consumer GPUs. FP8 Blog • Vision RL
- gpt-oss by OpenAI: Read our RL blog, Flex Attention blog and Guide.
📥 Advanced Installation
The below advanced instructions are for Unsloth Studio. For Unsloth Core advanced installation, view our docs.
Developer installs: macOS, Linux, WSL:
git clone https://github.com/unslothai/unsloth
cd unsloth
./install.sh --local
unsloth studio -H 0.0.0.0 -p 8888
Then to update :
unsloth studio update
Developer installs: Windows PowerShell:
git clone https://github.com/unslothai/unsloth.git
cd unsloth
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\install.ps1 --local
unsloth studio -H 0.0.0.0 -p 8888
Then to update :
unsloth studio update
Nightly: MacOS, Linux, WSL:
git clone https://github.com/unslothai/unsloth
cd unsloth
git checkout nightly
./install.sh --local
unsloth studio -H 0.0.0.0 -p 8888
Then to launch every time:
unsloth studio -H 0.0.0.0 -p 8888
Nightly: Windows:
Run in Windows Powershell:
git clone https://github.com/unslothai/unsloth.git
cd unsloth
git checkout nightly
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\install.ps1 --local
unsloth studio -H 0.0.0.0 -p 8888
Then to launch every time:
unsloth studio -H 0.0.0.0 -p 8888
Uninstall
You can uninstall Unsloth Studio by deleting its install folder usually located under $HOME/.unsloth/studio on Mac/Linux/WSL and %USERPROFILE%\.unsloth\studio on Windows. Using the rm -rf commands will delete everything, including your history, cache:
- MacOS, WSL, Linux:
rm -rf ~/.unsloth/studio - Windows (PowerShell):
Remove-Item -Recurse -Force "$HOME\.unsloth\studio"
For more info, see our docs.
Deleting model files
You can delete old model files either from the bin icon in model search or by removing the relevant cached model folder from the default Hugging Face cache directory. By default, HF uses:
- MacOS, Linux, WSL:
~/.cache/huggingface/hub/ - Windows:
%USERPROFILE%\.cache\huggingface\hub\
💚 Community and Links
| Type | Links |
|---|---|
| Join Discord server | |
| Join Reddit community | |
| 📚 Documentation & Wiki | Read Our Docs |
| Follow us on X | |
| 🔮 Our Models | Unsloth Catalog |
| ✍️ Blog | Read our Blogs |
Citation
You can cite the Unsloth repo as follows:
@software{unsloth,
author = {Daniel Han, Michael Han and Unsloth team},
title = {Unsloth},
url = {https://github.com/unslothai/unsloth},
year = {2023}
}
If you trained a model with 🦥Unsloth, you can use this cool sticker!
License
Unsloth uses a dual-licensing model of Apache 2.0 and AGPL-3.0. The core Unsloth package remains licensed under Apache 2.0, while certain optional components, such as the Unsloth Studio UI are licensed under the open-source license AGPL-3.0.
This structure helps support ongoing Unsloth development while keeping the project open source and enabling the broader ecosystem to continue growing.
Thank You to
- The llama.cpp library that lets users run and save models with Unsloth
- The Hugging Face team and their libraries: transformers and TRL
- The Pytorch and Torch AO team for their contributions
- NVIDIA for their NeMo DataDesigner library and their contributions
- And of course for every single person who has contributed or has used Unsloth!