* Fix Gemma-4 GRPO catastrophic KL divergence with TRL 1.0.0+
Two compounding bugs caused Gemma-4 GRPO training to diverge with KL ~10^12
at step 1 against TRL 1.0.0+. Both fixes are runtime patches in the existing
TRL/model patch flow and are no-ops for models and TRL versions that are not
affected.
Fix 1 (rl.py): replace trl.models.utils.disable_gradient_checkpointing with
a no-op context manager. TRL 1.0.0+ wraps generation in
`with torch.no_grad(), disable_gradient_checkpointing(self.model, ...):`
purely to suppress a cosmetic PyTorch warning ("None of the inputs have
requires_grad=True"). Inside torch.no_grad() the gradient checkpointing
state has no functional effect on the forward pass. On context exit, TRL
calls model.gradient_checkpointing_enable() which dispatches to HF's
generic implementation and overwrites Unsloth's custom
`use_gradient_checkpointing="unsloth"` wrapper, corrupting Gemma-4 forward
numerics. Replacing the toggle with a no-op preserves Unsloth's custom GC
wrapper across generation passes. The patch walks sys.modules dynamically
to also rebind the symbol on every trl.* module that already imported it
(grpo_trainer, dpo_trainer, rloo_trainer, dppo_trainer, gfpo_trainer,
grpo_with_replay_buffer_trainer, and any future trainer module).
Fix 2 (vision.py): inject `final_logit_softcapping` from `config.text_config`
into the top-level `model.config` for multimodal models. Unsloth's GRPO
trainer reads `getattr(model.config, "final_logit_softcapping", 0)` but
for Gemma-4 the attribute lives only on the nested `Gemma4TextConfig`,
so the lookup silently defaults to 0 instead of 30.
Backwards compatibility:
- trl 0.22.2: no `disable_gradient_checkpointing` symbol exists, the patch
early-returns via `hasattr` guard.
- trl 0.27.1: same broken pattern as 1.0.0, the noop replacement is correct.
- trl 1.0.0+: end-to-end verified on `unsloth/gemma-4-E2B-it` GRPO with TRL
1.0.0 and transformers 5.5.0. Step 1 loss=2.46e-08, kl=2.92e-05 (machine
zero) vs broken baseline loss=1.37e+06, kl=1.76e+09.
- Llama / non-VLM text models: Fix 2 is a no-op (no `text_config`); Fix 1
is functionally identical (Unsloth's GC wrapper is preserved).
- Qwen3-VL and other VLMs without final_logit_softcapping: Fix 2 is a no-op
(text_config.final_logit_softcapping is None).
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
* Apply loop 1 review fixes for PR #4934
- Move Fix 2 from vision.py to rl_replacements.py:858 and :1110 at the
actual consumer sites. This avoids mutating model.config (which could
leak into save_pretrained output) and covers text-only Gemma-4 paths
that do not flow through FastBaseModel.from_pretrained.
- Revert the vision.py injection block entirely.
- Narrow the bare except blocks in patch_trl_disable_gradient_checkpointing
from `except Exception:` to `(AttributeError, ImportError)` and
`(AttributeError, TypeError)` to avoid masking unrelated bugs.
- Add logger.warning_once when the noop patch is installed, matching
patch_trl_openenv and patch_trl_vllm_generation convention.
- Remove the dead per-module `_unsloth_noop_patched` sentinel check inside
the sys.modules walk. The function-level early return already covers
this case.
- Move `import sys` and `from contextlib import contextmanager` to the
module-level imports instead of inside the function body.
- Rewrite the ordering comment in PatchFastRL to accurately describe
why patch_trl_disable_gradient_checkpointing must run before
patch_trl_rl_trainers.
- Fix keyword default spacing to match surrounding rl.py style.
End-to-end verified: Gemma-4-E2B GRPO on TRL 1.0.0 + transformers 5.5.0
step 1 loss=2.464e-08 kl=2.921e-05, all 5 steps succeed.
* Apply loop 2 review fix for PR #4934
Extract the final_logit_softcapping fallback logic into a shared helper
`_unsloth_get_final_logit_softcapping(config)` defined in rl_replacements.py
and injected into the compiled cache via RL_PRE_ITEMS["grpo_trainer"]. Both
call sites (`grpo_trainer__generate_and_score_completions` and
`grpo_trainer_compute_loss`) now use the helper instead of inlining the
same text_config fallback block twice.
Verified: compiled cache file lists the helper at module scope and both
consumer sites call it. Gemma-4-E2B GRPO step 1 loss=2.464e-08 kl=2.921e-05
(unchanged), all 5 steps pass.
* Apply loop 3 review fix for PR #4934
Extend _unsloth_get_final_logit_softcapping to also fall back to
config.get_text_config() for composite configs such as T5GemmaConfig
where the text sub-config is not exposed via the text_config attribute
but only via the get_text_config() method. Guard against (TypeError,
ValueError) raised by ambiguous composite configs, and skip the
self-referential case where get_text_config() returns self.
This addresses the 6/7 reviewer consensus from the third review loop.
Verified:
- Helper returns 30.0 for Gemma-4, T5Gemma, and Gemma 1/2 configs.
- Helper returns 0 for Llama, Qwen, Mistral, Cohere, Granite, and
ambiguous configs raising ValueError.
- Gemma-4-E2B GRPO step 1 loss=2.464e-08 kl=2.921e-05 (unchanged).
- Llama-3.2-1B GRPO all 5 steps loss=0 kl=0 (no regression).
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
---------
Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
|
||
|---|---|---|
| .github | ||
| images | ||
| scripts | ||
| studio | ||
| tests | ||
| unsloth | ||
| unsloth_cli | ||
| .gitattributes | ||
| .gitignore | ||
| .pre-commit-ci.yaml | ||
| .pre-commit-config.yaml | ||
| build.sh | ||
| cli.py | ||
| CODE_OF_CONDUCT.md | ||
| CONTRIBUTING.md | ||
| COPYING | ||
| install.ps1 | ||
| install.sh | ||
| install_gemma4_mlx.sh | ||
| LICENSE | ||
| pyproject.toml | ||
| README.md | ||
| unsloth-cli.py | ||

Run and train AI models with a unified local interface.
Features • Quickstart • Notebooks • Documentation • Reddit
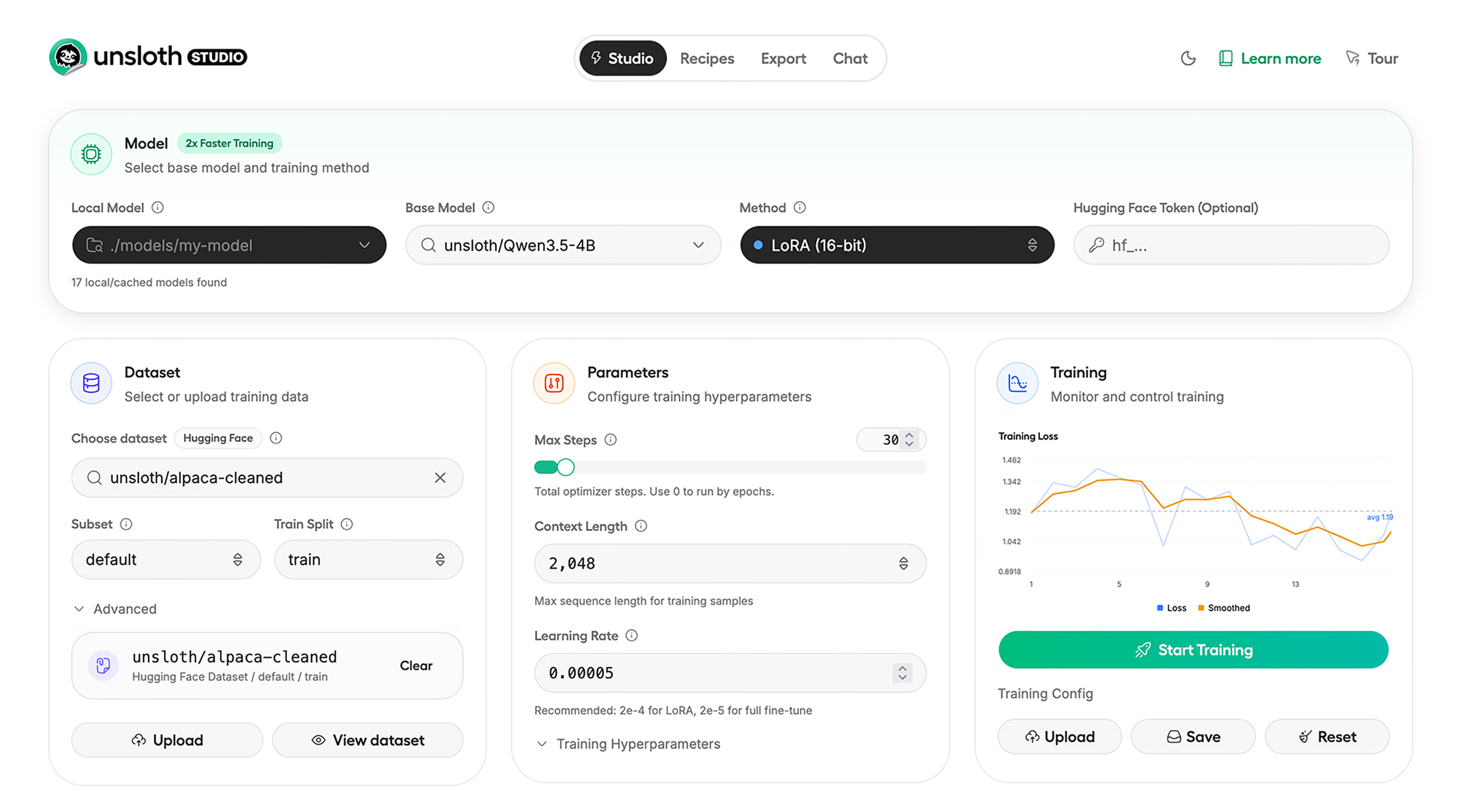
Unsloth Studio (Beta) lets you run and train text, audio, embedding, vision models on Windows, Linux and macOS.
⭐ Features
Unsloth provides several key features for both inference and training:
Inference
- Search + download + run models including GGUF, LoRA adapters, safetensors
- Export models: Save or export models to GGUF, 16-bit safetensors and other formats.
- Tool calling: Support for self-healing tool calling and web search
- Code execution: lets LLMs test code in Claude artifacts and sandbox environments
- Auto-tune inference parameters and customize chat templates.
- We work directly with teams behind gpt-oss, Qwen3, Llama 4, Mistral, Gemma 1-3, and Phi-4, where we’ve fixed bugs that improve model accuracy.
- Upload images, audio, PDFs, code, DOCX and more file types to chat with.
Training
- Train and RL 500+ models up to 2x faster with up to 70% less VRAM, with no accuracy loss.
- Custom Triton and mathematical kernels. See some collabs we did with PyTorch and Hugging Face.
- Data Recipes: Auto-create datasets from PDF, CSV, DOCX etc. Edit data in a visual-node workflow.
- Reinforcement Learning (RL): The most efficient RL library, using 80% less VRAM for GRPO, FP8 etc.
- Supports full fine-tuning, RL, pretraining, 4-bit, 16-bit and, FP8 training.
- Observability: Monitor training live, track loss and GPU usage and customize graphs.
- Multi-GPU training is supported, with major improvements coming soon.
⚡ Quickstart
Unsloth can be used in two ways: through Unsloth Studio, the web UI, or through Unsloth Core, the code-based version. Each has different requirements.
Unsloth Studio (web UI)
Unsloth Studio (Beta) works on Windows, Linux, WSL and macOS.
- CPU: Supported for Chat and Data Recipes currently
- NVIDIA: Training works on RTX 30/40/50, Blackwell, DGX Spark, Station and more
- macOS: Currently supports chat and Data Recipes. MLX training is coming very soon
- AMD: Chat + Data works. Train with Unsloth Core. Studio support is out soon.
- Coming soon: Training support for Apple MLX, AMD, and Intel.
- Multi-GPU: Available now, with a major upgrade on the way
macOS, Linux, WSL:
curl -fsSL https://unsloth.ai/install.sh | sh
Windows:
irm https://unsloth.ai/install.ps1 | iex
Launch
unsloth studio -H 0.0.0.0 -p 8888
Update
To update, use the same install commands as above. Or run (does not work on Windows):
unsloth studio update
Docker
Use our Docker image unsloth/unsloth container. Run:
docker run -d -e JUPYTER_PASSWORD="mypassword" \
-p 8888:8888 -p 8000:8000 -p 2222:22 \
-v $(pwd)/work:/workspace/work \
--gpus all \
unsloth/unsloth
Developer, Nightly, Uninstall
To see developer, nightly and uninstallation etc. instructions, see advanced installation.
Unsloth Core (code-based)
Linux, WSL:
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv unsloth_env --python 3.13
source unsloth_env/bin/activate
uv pip install unsloth --torch-backend=auto
Windows:
winget install -e --id Python.Python.3.13
winget install --id=astral-sh.uv -e
uv venv unsloth_env --python 3.13
.\unsloth_env\Scripts\activate
uv pip install unsloth --torch-backend=auto
For Windows, pip install unsloth works only if you have PyTorch installed. Read our Windows Guide.
You can use the same Docker image as Unsloth Studio.
AMD, Intel:
For RTX 50x, B200, 6000 GPUs: uv pip install unsloth --torch-backend=auto. Read our guides for: Blackwell and DGX Spark.
To install Unsloth on AMD and Intel GPUs, follow our AMD Guide and Intel Guide.
📒 Free Notebooks
Train for free with our notebooks. You can use our new free Unsloth Studio notebook to run and train models for free in a web UI. Read our guide. Add dataset, run, then deploy your trained model.
| Model | Free Notebooks | Performance | Memory use |
|---|---|---|---|
| Gemma 4 (E2B) | ▶️ Start for free | 1.5x faster | 50% less |
| Qwen3.5 (4B) | ▶️ Start for free | 1.5x faster | 60% less |
| gpt-oss (20B) | ▶️ Start for free | 2x faster | 70% less |
| Qwen3.5 GSPO | ▶️ Start for free | 2x faster | 70% less |
| gpt-oss (20B): GRPO | ▶️ Start for free | 2x faster | 80% less |
| Qwen3: Advanced GRPO | ▶️ Start for free | 2x faster | 70% less |
| embeddinggemma (300M) | ▶️ Start for free | 2x faster | 20% less |
| Mistral Ministral 3 (3B) | ▶️ Start for free | 1.5x faster | 60% less |
| Llama 3.1 (8B) Alpaca | ▶️ Start for free | 2x faster | 70% less |
| Llama 3.2 Conversational | ▶️ Start for free | 2x faster | 70% less |
| Orpheus-TTS (3B) | ▶️ Start for free | 1.5x faster | 50% less |
- See all our notebooks for: Kaggle, GRPO, TTS, embedding & Vision
- See all our models and all our notebooks
- See detailed documentation for Unsloth here
🦥 Unsloth News
- Gemma 4: Run and train Google’s new models directly in Unsloth Studio! Blog
- Introducing Unsloth Studio: our new web UI for running and training LLMs. Blog
- Qwen3.5 - 0.8B, 2B, 4B, 9B, 27B, 35-A3B, 112B-A10B are now supported. Guide + notebooks
- Train MoE LLMs 12x faster with 35% less VRAM - DeepSeek, GLM, Qwen and gpt-oss. Blog
- Embedding models: Unsloth now supports ~1.8-3.3x faster embedding fine-tuning. Blog • Notebooks
- New 7x longer context RL vs. all other setups, via our new batching algorithms. Blog
- New RoPE & MLP Triton Kernels & Padding Free + Packing: 3x faster training & 30% less VRAM. Blog
- 500K Context: Training a 20B model with >500K context is now possible on an 80GB GPU. Blog
- FP8 & Vision RL: You can now do FP8 & VLM GRPO on consumer GPUs. FP8 Blog • Vision RL
- gpt-oss by OpenAI: Read our RL blog, Flex Attention blog and Guide.
📥 Advanced Installation
The below advanced instructions are for Unsloth Studio. For Unsloth Core advanced installation, view our docs.
Developer installs: macOS, Linux, WSL:
git clone https://github.com/unslothai/unsloth
cd unsloth
./install.sh --local
unsloth studio -H 0.0.0.0 -p 8888
Then to update :
unsloth studio update
Developer installs: Windows PowerShell:
git clone https://github.com/unslothai/unsloth.git
cd unsloth
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\install.ps1 --local
unsloth studio -H 0.0.0.0 -p 8888
Then to update :
unsloth studio update
Nightly: MacOS, Linux, WSL:
git clone https://github.com/unslothai/unsloth
cd unsloth
git checkout nightly
./install.sh --local
unsloth studio -H 0.0.0.0 -p 8888
Then to launch every time:
unsloth studio -H 0.0.0.0 -p 8888
Nightly: Windows:
Run in Windows Powershell:
git clone https://github.com/unslothai/unsloth.git
cd unsloth
git checkout nightly
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\install.ps1 --local
unsloth studio -H 0.0.0.0 -p 8888
Then to launch every time:
unsloth studio -H 0.0.0.0 -p 8888
Uninstall
You can uninstall Unsloth Studio by deleting its install folder usually located under $HOME/.unsloth/studio on Mac/Linux/WSL and %USERPROFILE%\.unsloth\studio on Windows. Using the rm -rf commands will delete everything, including your history, cache:
- MacOS, WSL, Linux:
rm -rf ~/.unsloth/studio - Windows (PowerShell):
Remove-Item -Recurse -Force "$HOME\.unsloth\studio"
For more info, see our docs.
Deleting model files
You can delete old model files either from the bin icon in model search or by removing the relevant cached model folder from the default Hugging Face cache directory. By default, HF uses:
- MacOS, Linux, WSL:
~/.cache/huggingface/hub/ - Windows:
%USERPROFILE%\.cache\huggingface\hub\
💚 Community and Links
| Type | Links |
|---|---|
| Join Discord server | |
| Join Reddit community | |
| 📚 Documentation & Wiki | Read Our Docs |
| Follow us on X | |
| 🔮 Our Models | Unsloth Catalog |
| ✍️ Blog | Read our Blogs |
Citation
You can cite the Unsloth repo as follows:
@software{unsloth,
author = {Daniel Han, Michael Han and Unsloth team},
title = {Unsloth},
url = {https://github.com/unslothai/unsloth},
year = {2023}
}
If you trained a model with 🦥Unsloth, you can use this cool sticker!
License
Unsloth uses a dual-licensing model of Apache 2.0 and AGPL-3.0. The core Unsloth package remains licensed under Apache 2.0, while certain optional components, such as the Unsloth Studio UI are licensed under the open-source license AGPL-3.0.
This structure helps support ongoing Unsloth development while keeping the project open source and enabling the broader ecosystem to continue growing.
Thank You to
- The llama.cpp library that lets users run and save models with Unsloth
- The Hugging Face team and their libraries: transformers and TRL
- The Pytorch and Torch AO team for their contributions
- NVIDIA for their NeMo DataDesigner library and their contributions
- And of course for every single person who has contributed or has used Unsloth!