* Studio: Ollama support, recommended folders, Custom Folders UX polish
Backend:
- Add _scan_ollama_dir that reads manifests/registry.ollama.ai/library/*
and creates .gguf symlinks under <ollama_dir>/.studio_links/ pointing
at the content-addressable blobs, so detect_gguf_model and llama-server
-m work unchanged for Ollama models
- Filter entries under .studio_links from the generic models/hf/lmstudio
scanners to avoid duplicate rows and leaked internal paths in the UI
- New GET /api/models/recommended-folders endpoint returning LM Studio
and Ollama model directories that currently exist on the machine
(OLLAMA_MODELS env var + standard paths, ~/.lmstudio/models, legacy
LM Studio cache), used by the Custom Folders quick-add chips
- detect_gguf_model now uses os.path.abspath instead of Path.resolve so
the readable symlink name is preserved as display_name (e.g.
qwen2.5-0.5b-Q4_K_M.gguf instead of sha256-abc...)
- llama-server failure with a path under .studio_links or .cache/ollama
surfaces a friendlier message ("Some Ollama models do not work with
llama.cpp. Try a different model, or use this model directly through
Ollama instead.") instead of the generic validation error
Frontend:
- ListLabel supports an optional leading icon and collapse toggle; used
for Downloaded (download icon), Custom Folders (folder icon), and
Recommended (star icon)
- Custom Folders header gets folder icon on the left, and +, search,
and chevron buttons on the right; chevron uses ml-auto so it aligns
with the Downloaded and Recommended chevrons
- New recommended folder chips render below the registered scan folders
when there are unregistered well-known paths; one click adds them as
a scan folder
- Custom folder rows that are direct .gguf files (Ollama symlinks) load
immediately via onSelect instead of opening the GGUF variant expander
(which is for repos containing multiple quants, not single files)
- When loading a direct .gguf file path, send max_seq_length = 0 so the
backend uses the model's native context instead of the 4096 chat
default (qwen2.5:0.5b now loads at 32768 instead of 4096)
- New listRecommendedFolders() helper on the chat API
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
* Address review: log silent exceptions and support read-only Ollama dirs
Replace silent except blocks in _scan_ollama_dir and the
recommended-folders endpoint with narrower exception types plus debug
or warning logs, so failures are diagnosable without hiding signal.
Add _ollama_links_dir helper that falls back to a per-ollama-dir hashed
namespace under Studio's own cache (~/.unsloth/studio/cache/ollama_links)
when the Ollama models directory is read-only. Common for system installs
at /usr/share/ollama/.ollama/models and /var/lib/ollama/.ollama/models
where the Studio process has read but not write access. Previously the
scanner returned an empty list in that case and Ollama models would
silently not appear.
The fallback preserves the .gguf suffix on symlink names so
detect_gguf_model keeps recognising them. The prior "raw sha256 blob
path" fallback would have missed the suffix check and failed to load.
* Address review: detect mmproj next to symlink target for vision GGUFs
Codex P1 on model_config.py:1012: when detect_gguf_model returns the
symlink path (to preserve readable display names), detect_mmproj_file
searched the symlink's parent directory instead of the target's. For
vision GGUFs surfaced via Ollama's .studio_links/ -- where the weight
file is symlinked but any mmproj sidecar lives next to the real blob
-- mmproj was no longer detected, so the model was misclassified as
text-only and llama-server would start without --mmproj.
detect_mmproj_file now adds the resolved target's parent to the scan
order when path is a symlink. Direct (non-symlink) .gguf paths are
unchanged, so LM Studio and HF cache layouts keep working exactly as
before. Verified with a fake layout reproducing the bug plus a
regression check on a non-symlink LM Studio model.
* Address review: support all Ollama namespaces and vision projector layers
- Iterate over all directories under registry.ollama.ai/ instead of
hardcoding the "library" namespace. Custom namespaces like
"mradermacher/llama3" now get scanned and include the namespace
prefix in display names, model IDs, and symlink names to avoid
collisions.
- Create companion -mmproj.gguf symlinks for Ollama vision models
that have an "application/vnd.ollama.image.projector" layer, so
detect_mmproj_file can find the projector alongside the model.
- Extract symlink creation into _make_symlink helper to reduce
duplication between model and projector paths.
* Address review: move imports to top level and add scan limit
- Move hashlib and json imports to the top of the file (PEP 8).
- Remove inline `import json as _json` and `import hashlib` from
function bodies, use the top-level imports directly.
- Add `limit` parameter to `_scan_ollama_dir()` with early exit
when the threshold is reached.
- Pass `_MAX_MODELS_PER_FOLDER` into the scanner so it stops
traversing once enough models are found.
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
* Address review: Windows fallback, all registry hosts, collision safety
_make_link (formerly _make_symlink):
- Falls back to os.link() hardlink when symlink_to() fails (Windows
without Developer Mode), then to shutil.copy2 as last resort
- Uses atomic os.replace via tmp file to avoid race window where the
.gguf path is missing during rescan
Scanner now handles all Ollama registry layouts:
- Uses rglob over manifests/ instead of hardcoding registry.ollama.ai
- Discovers hf.co/org/repo:tag and any other host, not just library/
- Filenames include a stable sha1 hash of the manifest path to prevent
collisions between models that normalize to the same stem
Per-model subdirectories under .studio_links/:
- Each model's links live in their own hash-keyed subdirectory
- detect_mmproj_file only sees the projector for that specific model,
not siblings from other Ollama models
Friendly Ollama error detection:
- Now also matches ollama_links/ (the read-only fallback cache path)
and model_identifier starting with "ollama/"
Recommended folders:
- Added os.access(R_OK | X_OK) check so unreadable system directories
like /var/lib/ollama/.ollama/models are not advertised as chips
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
* Address review: filter ollama_links from generic scanners
The generic scanners (models_dir, hf_cache, lmstudio) already filter
out .studio_links to avoid duplicate Ollama entries, but missed the
ollama_links fallback cache directory used for read-only Ollama
installs. Add it to the filter.
* Address review: idempotent link creation and path-component filter
_make_link:
- Skip recreation when a valid link/copy already exists (samefile or
matching size check). Prevents blocking the model-list API with
multi-GB copies on repeated scans.
- Use uuid4 instead of os.getpid() for tmp file names to avoid race
conditions from concurrent scans.
- Log cleanup errors instead of silently swallowing them.
Path filter:
- Use os.sep-bounded checks instead of bare substring match to avoid
false positives on paths like "my.studio_links.backup/model.gguf".
* [pre-commit.ci] auto fixes from pre-commit.com hooks
for more information, see https://pre-commit.ci
* Address review: drop copy fallback, targeted glob, robust path filter
_make_link:
- Drop shutil.copy2 fallback -- copying multi-GB GGUFs inside a sync
API request would block the backend. Log a warning and skip the
model when both symlink and hardlink fail.
Scanner:
- Replace rglob("*") with targeted glob patterns (*/*/* and */*/*/*)
to avoid traversing unrelated subdirectories in large custom folders.
Path filter:
- Use Path.parts membership check instead of os.sep substring matching
for robustness across platforms.
Scan limit:
- Skip _scan_ollama_dir when _generic already fills the per-folder cap.
* Address review: sha256, top-level uuid import, Path.absolute()
- Switch hashlib.sha1 to hashlib.sha256 for path hashing consistency.
- Move uuid import to the top of the file instead of inside _make_link.
- Replace os.path.abspath with Path.absolute() in detect_gguf_model
to match the pathlib style used throughout the codebase.
* Address review: fix stale comments (sha1, rglob, copy fallback)
Update three docstrings/comments that still referenced the old
implementation after recent changes:
- sha1 comment now says "not a security boundary" (no hash name)
- "rglob" -> "targeted glob patterns"
- "file copies as a last resort" -> removed (copy fallback was dropped)
* Address review: fix stale links, support all manifest depths, scope error
_make_link:
- Drop size-based idempotency shortcut that kept stale links after
ollama pull updates a tag to a same-sized blob. Only samefile()
is used now -- if the link doesn't point at the exact same inode,
it gets replaced.
Scanner:
- Revert targeted glob back to rglob so deeper OCI-style repo names
(5+ path segments) are not silently skipped.
Ollama error:
- Only show "Some Ollama models do not work with llama.cpp" when the
server output contains GGUF compatibility hints (key not found,
unknown architecture, failed to load). Unrelated failures like
OOM or missing binaries now show the generic error instead of
being misdiagnosed.
---------
Co-authored-by: Daniel Han <info@unsloth.ai>
Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com>
Co-authored-by: danielhanchen <michaelhan2050@gmail.com>
|
||
|---|---|---|
| .github | ||
| images | ||
| scripts | ||
| studio | ||
| tests | ||
| unsloth | ||
| unsloth_cli | ||
| .gitattributes | ||
| .gitignore | ||
| .pre-commit-ci.yaml | ||
| .pre-commit-config.yaml | ||
| build.sh | ||
| cli.py | ||
| CODE_OF_CONDUCT.md | ||
| CONTRIBUTING.md | ||
| COPYING | ||
| install.ps1 | ||
| install.sh | ||
| LICENSE | ||
| pyproject.toml | ||
| README.md | ||
| unsloth-cli.py | ||

Run and train AI models with a unified local interface.
Features • Quickstart • Notebooks • Documentation • Reddit
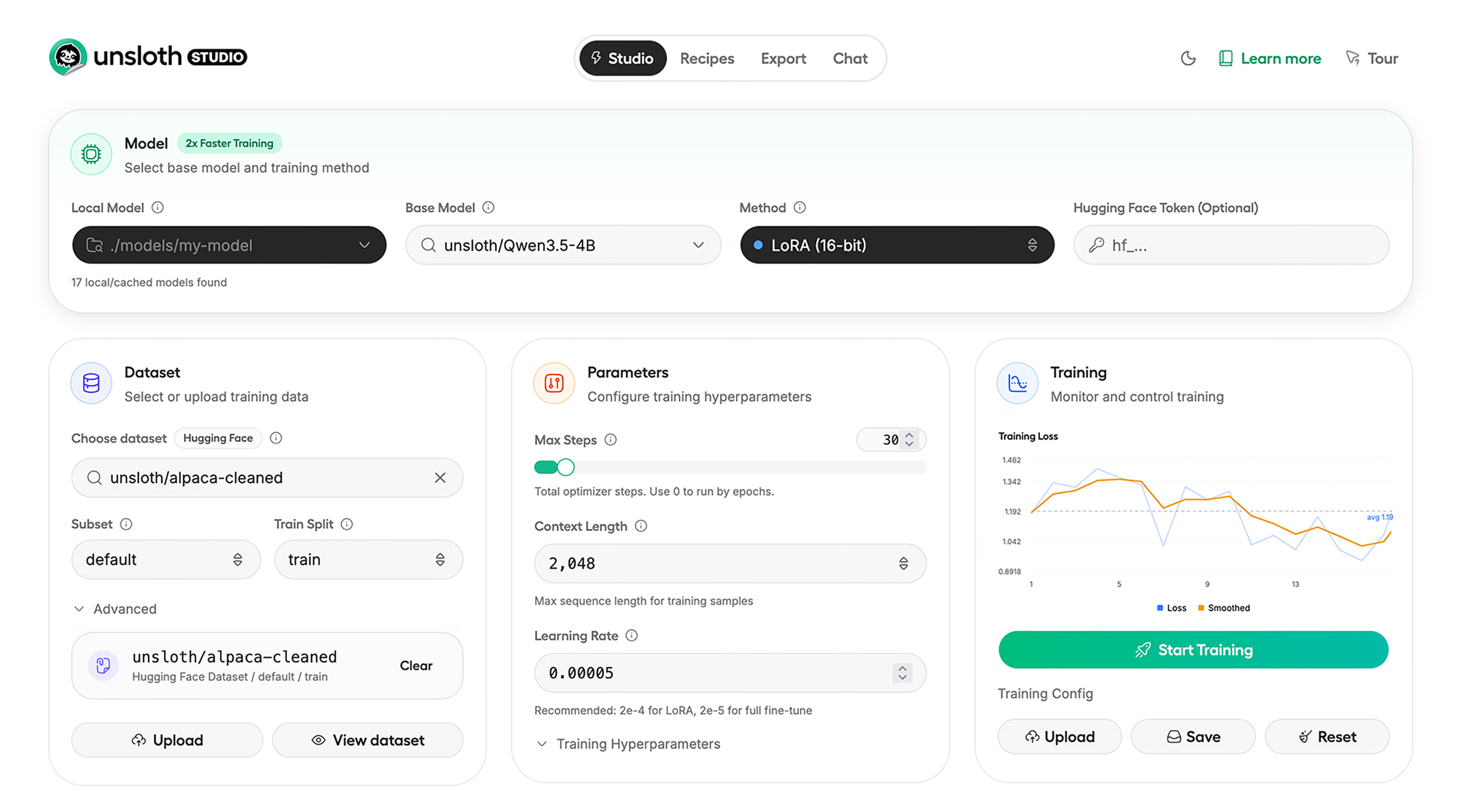
Unsloth Studio (Beta) lets you run and train text, audio, embedding, vision models on Windows, Linux and macOS.
⭐ Features
Unsloth provides several key features for both inference and training:
Inference
- Search + download + run models including GGUF, LoRA adapters, safetensors
- Export models: Save or export models to GGUF, 16-bit safetensors and other formats.
- Tool calling: Support for self-healing tool calling and web search
- Code execution: lets LLMs test code in Claude artifacts and sandbox environments
- Auto-tune inference parameters and customize chat templates.
- We work directly with teams behind gpt-oss, Qwen3, Llama 4, Mistral, Gemma 1-3, and Phi-4, where we’ve fixed bugs that improve model accuracy.
- Upload images, audio, PDFs, code, DOCX and more file types to chat with.
Training
- Train and RL 500+ models up to 2x faster with up to 70% less VRAM, with no accuracy loss.
- Custom Triton and mathematical kernels. See some collabs we did with PyTorch and Hugging Face.
- Data Recipes: Auto-create datasets from PDF, CSV, DOCX etc. Edit data in a visual-node workflow.
- Reinforcement Learning (RL): The most efficient RL library, using 80% less VRAM for GRPO, FP8 etc.
- Supports full fine-tuning, RL, pretraining, 4-bit, 16-bit and, FP8 training.
- Observability: Monitor training live, track loss and GPU usage and customize graphs.
- Multi-GPU training is supported, with major improvements coming soon.
⚡ Quickstart
Unsloth can be used in two ways: through Unsloth Studio, the web UI, or through Unsloth Core, the code-based version. Each has different requirements.
Unsloth Studio (web UI)
Unsloth Studio (Beta) works on Windows, Linux, WSL and macOS.
- CPU: Supported for Chat and Data Recipes currently
- NVIDIA: Training works on RTX 30/40/50, Blackwell, DGX Spark, Station and more
- macOS: Currently supports chat and Data Recipes. MLX training is coming very soon
- AMD: Chat + Data works. Train with Unsloth Core. Studio support is out soon.
- Coming soon: Training support for Apple MLX, AMD, and Intel.
- Multi-GPU: Available now, with a major upgrade on the way
macOS, Linux, WSL:
curl -fsSL https://unsloth.ai/install.sh | sh
Windows:
irm https://unsloth.ai/install.ps1 | iex
Launch
unsloth studio -H 0.0.0.0 -p 8888
Update
To update, use the same install commands as above. Or run (does not work on Windows):
unsloth studio update
Docker
Use our Docker image unsloth/unsloth container. Run:
docker run -d -e JUPYTER_PASSWORD="mypassword" \
-p 8888:8888 -p 8000:8000 -p 2222:22 \
-v $(pwd)/work:/workspace/work \
--gpus all \
unsloth/unsloth
Developer, Nightly, Uninstall
To see developer, nightly and uninstallation etc. instructions, see advanced installation.
Unsloth Core (code-based)
Linux, WSL:
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv unsloth_env --python 3.13
source unsloth_env/bin/activate
uv pip install unsloth --torch-backend=auto
Windows:
winget install -e --id Python.Python.3.13
winget install --id=astral-sh.uv -e
uv venv unsloth_env --python 3.13
.\unsloth_env\Scripts\activate
uv pip install unsloth --torch-backend=auto
For Windows, pip install unsloth works only if you have PyTorch installed. Read our Windows Guide.
You can use the same Docker image as Unsloth Studio.
AMD, Intel:
For RTX 50x, B200, 6000 GPUs: uv pip install unsloth --torch-backend=auto. Read our guides for: Blackwell and DGX Spark.
To install Unsloth on AMD and Intel GPUs, follow our AMD Guide and Intel Guide.
📒 Free Notebooks
Train for free with our notebooks. You can use our new free Unsloth Studio notebook to run and train models for free in a web UI. Read our guide. Add dataset, run, then deploy your trained model.
| Model | Free Notebooks | Performance | Memory use |
|---|---|---|---|
| Gemma 4 (E2B) | ▶️ Start for free | 1.5x faster | 50% less |
| Qwen3.5 (4B) | ▶️ Start for free | 1.5x faster | 60% less |
| gpt-oss (20B) | ▶️ Start for free | 2x faster | 70% less |
| Qwen3.5 GSPO | ▶️ Start for free | 2x faster | 70% less |
| gpt-oss (20B): GRPO | ▶️ Start for free | 2x faster | 80% less |
| Qwen3: Advanced GRPO | ▶️ Start for free | 2x faster | 70% less |
| embeddinggemma (300M) | ▶️ Start for free | 2x faster | 20% less |
| Mistral Ministral 3 (3B) | ▶️ Start for free | 1.5x faster | 60% less |
| Llama 3.1 (8B) Alpaca | ▶️ Start for free | 2x faster | 70% less |
| Llama 3.2 Conversational | ▶️ Start for free | 2x faster | 70% less |
| Orpheus-TTS (3B) | ▶️ Start for free | 1.5x faster | 50% less |
- See all our notebooks for: Kaggle, GRPO, TTS, embedding & Vision
- See all our models and all our notebooks
- See detailed documentation for Unsloth here
🦥 Unsloth News
- Gemma 4: Run and train Google’s new models directly in Unsloth Studio! Blog
- Introducing Unsloth Studio: our new web UI for running and training LLMs. Blog
- Qwen3.5 - 0.8B, 2B, 4B, 9B, 27B, 35-A3B, 112B-A10B are now supported. Guide + notebooks
- Train MoE LLMs 12x faster with 35% less VRAM - DeepSeek, GLM, Qwen and gpt-oss. Blog
- Embedding models: Unsloth now supports ~1.8-3.3x faster embedding fine-tuning. Blog • Notebooks
- New 7x longer context RL vs. all other setups, via our new batching algorithms. Blog
- New RoPE & MLP Triton Kernels & Padding Free + Packing: 3x faster training & 30% less VRAM. Blog
- 500K Context: Training a 20B model with >500K context is now possible on an 80GB GPU. Blog
- FP8 & Vision RL: You can now do FP8 & VLM GRPO on consumer GPUs. FP8 Blog • Vision RL
- gpt-oss by OpenAI: Read our RL blog, Flex Attention blog and Guide.
📥 Advanced Installation
The below advanced instructions are for Unsloth Studio. For Unsloth Core advanced installation, view our docs.
Developer installs: macOS, Linux, WSL:
git clone https://github.com/unslothai/unsloth
cd unsloth
./install.sh --local
unsloth studio -H 0.0.0.0 -p 8888
Then to update :
unsloth studio update
Developer installs: Windows PowerShell:
git clone https://github.com/unslothai/unsloth.git
cd unsloth
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\install.ps1 --local
unsloth studio -H 0.0.0.0 -p 8888
Then to update :
unsloth studio update
Nightly: MacOS, Linux, WSL:
git clone https://github.com/unslothai/unsloth
cd unsloth
git checkout nightly
./install.sh --local
unsloth studio -H 0.0.0.0 -p 8888
Then to launch every time:
unsloth studio -H 0.0.0.0 -p 8888
Nightly: Windows:
Run in Windows Powershell:
git clone https://github.com/unslothai/unsloth.git
cd unsloth
git checkout nightly
Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass
.\install.ps1 --local
unsloth studio -H 0.0.0.0 -p 8888
Then to launch every time:
unsloth studio -H 0.0.0.0 -p 8888
Uninstall
You can uninstall Unsloth Studio by deleting its install folder usually located under $HOME/.unsloth/studio on Mac/Linux/WSL and %USERPROFILE%\.unsloth\studio on Windows. Using the rm -rf commands will delete everything, including your history, cache:
- MacOS, WSL, Linux:
rm -rf ~/.unsloth/studio - Windows (PowerShell):
Remove-Item -Recurse -Force "$HOME\.unsloth\studio"
For more info, see our docs.
Deleting model files
You can delete old model files either from the bin icon in model search or by removing the relevant cached model folder from the default Hugging Face cache directory. By default, HF uses:
- MacOS, Linux, WSL:
~/.cache/huggingface/hub/ - Windows:
%USERPROFILE%\.cache\huggingface\hub\
💚 Community and Links
| Type | Links |
|---|---|
| Join Discord server | |
| Join Reddit community | |
| 📚 Documentation & Wiki | Read Our Docs |
| Follow us on X | |
| 🔮 Our Models | Unsloth Catalog |
| ✍️ Blog | Read our Blogs |
Citation
You can cite the Unsloth repo as follows:
@software{unsloth,
author = {Daniel Han, Michael Han and Unsloth team},
title = {Unsloth},
url = {https://github.com/unslothai/unsloth},
year = {2023}
}
If you trained a model with 🦥Unsloth, you can use this cool sticker!
License
Unsloth uses a dual-licensing model of Apache 2.0 and AGPL-3.0. The core Unsloth package remains licensed under Apache 2.0, while certain optional components, such as the Unsloth Studio UI are licensed under the open-source license AGPL-3.0.
This structure helps support ongoing Unsloth development while keeping the project open source and enabling the broader ecosystem to continue growing.
Thank You to
- The llama.cpp library that lets users run and save models with Unsloth
- The Hugging Face team and their libraries: transformers and TRL
- The Pytorch and Torch AO team for their contributions
- NVIDIA for their NeMo DataDesigner library and their contributions
- And of course for every single person who has contributed or has used Unsloth!