,) to ('http://127.0.0.1:5000/login',)
AT LINE: login.twill:7
Note: submit is using submit button: name="login", value="登入"
AT LINE: login.twill:9
==> at http://127.0.0.1:5000/login
--
1 of 1 files SUCCEEDED.
一个成功的测试诞生了。
## Fake Server
实践了一下怎么用 sinon 去 fake server,还没用 respondWith,于是写一下。
这里需要用到 sinon 框架来测试。
当我们 fetch 的时候,我们就可以返回我们想要 fake 的结果。
var data = {"id":1,"name":"Rice","type":"Good","price":12,"quantity":1,"description":"Made in China"};
beforeEach(function() {
this.server = sinon.fakeServer.create();
this.rices = new Rices();
this.server.respondWith(
"GET",
"http://localhost:8080/all/rice",
[
200,
{"Content-Type": "application/json"},
JSON.stringify(data)
]
);
});
于是在 afterEach 的时候,我们需要恢复这个 server。
afterEach(function() {
this.server.restore();
});
接着写一个 jasmine 测试来测试
describe("Collection Test", function() {
it("should get data from the url", function() {
this.rices.fetch();
this.server.respond();
var result = JSON.parse(JSON.stringify(this.rices.models[0]));
expect(result["id"])
.toEqual(1);
expect(result["price"])
.toEqual(12);
expect(result)
.toEqual(data);
});
});
如何推广
===
除了擅长编写 md 电子书来攒 Star,我还写了一系列的开源软件,也掌握了一些项目运营的技巧。
**开源并不是你把软件、README 写好就行了,还有详细的文档、示例程序等等**。
**开源也不是你的项目好了,就会有一堆人参与进来**。
**开源还要你帮助别人解决 Bug,……**。
**人们做事都是有原因的**,即动机。再举例一下,如果你的项目不够火,别人都没听过,那么**写到简历上可能没啥用**。
Marketing First
---
开源需要一些营销的技巧,这些技巧可以帮你吸引关注。举个简单的例子,司徒正美的 [avalon](https://github.com/RubyLouvre/avalon) 框架出身得很早,也 MV* 方面也做得很不错,但是在 marketing 上就……。以至于国内的很多前端,都不了解这个框架,要不今天在国内可能就是 AVRR 四大框架了。
Vue 不是因为好用,而一下子火了。这一点我印象特别深,当时在 GitHub Trending 上看到了这个项目,发现它还不能很好地 work。
而如文章 《[FIRST WEEK OF LAUNCHING VUE.JS](http://blog.evanyou.me/2014/02/11/first-week-of-launching-an-oss-project/)》所说,项目刚开始的时候作者做了一系列的营销计划:
- HackerNews
- Reddit /r/javascript
- EchoJS
- The DailyJS blog
- JavaScript Weekly
- Maintain a project Twitter account(维护项目的 Vue 账户)
除此,文中还提到了一篇文章《[How to Spread The Word About Your Code](https://hacks.mozilla.org/2013/05/how-to-spread-the-word-about-your-code/?utm_source=statuscode&utm_medium=email)》 。
这一点相当的有意思,如果你的想法好的话,那么大家都会肯定,点下链接,为你来个 Star。那么,你就获得更好的动力去做这件事。项目也在开头的时候,获得了相当多的关注。而如果大家觉得你的项目没有新意的话,那么你懂的~。
除此,还有一种可能是,你的 ID 不够 fancy,即你在社区的影响上比较少。此时,就需要**一点点慢慢积累人气**了。当你积累了一些人气,你就能和松本行弘一样,在创建 mRuby 的时候就有 1000+ 的 Star。并且,在社区上还有一些相关的文章介绍,各个头条也由他的粉丝发了上去。如,一年多以前,我创建了 [mole](https://github.com/phodal/mole) 项目。

当时,是为了给自己做一个基于 GitHub 云笔记的工具,在完成度到一定程度的时候。我在我的微信公从号上发了相关的介绍,第二天就有 100+ 的 Star 了,还接收到一些鼓舞的话语。对应于国内则有:
- 极客头条
- 掘金
- 开发者头条
- v2ex
- 知乎
- 不成器的微博
所以,你觉得呢?
编写一个好的 README
---
在一个开源项目里,README 是最重要的内容。它快速地介绍了这个项目,并决定了它能不能吸引用户:
- **这个项目做什么?**
- **它解决了什么问题**
- **它有什么特性**
- **hello, world 示例**
### 这个项目做什么——一句话文案
GitHub 的 Description 是我们在 Hacking News、GitHub Trneding 等等,第一时间看到的介绍。也是我们能快速介绍给别人的东西,如下图所示:
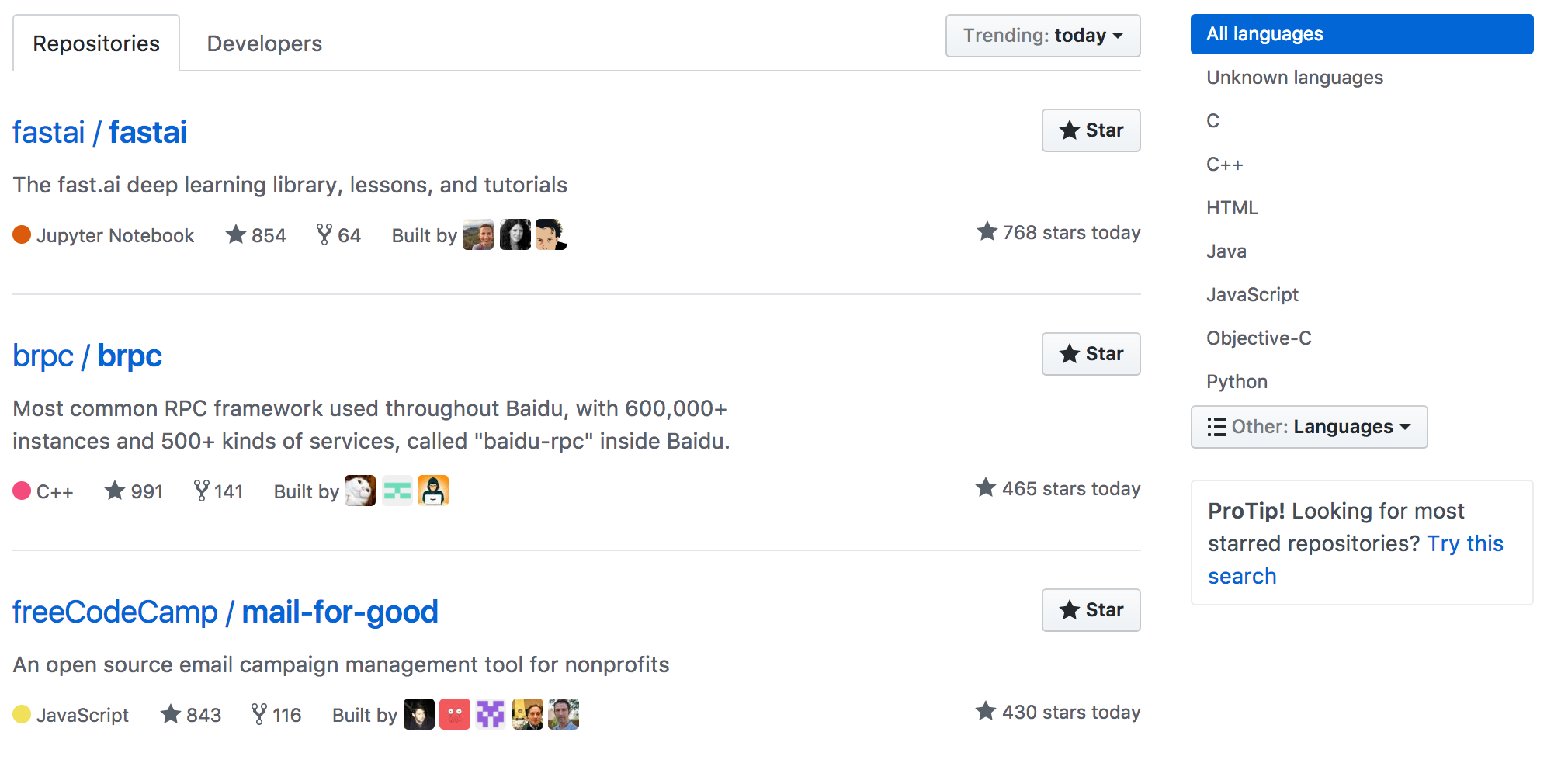
这一句话,必须简单明了也介绍,它是干什么的。
如 Angular 的一句话方案是:One framework. Mobile & desktop.
而 React 是:A declarative, efficient, and flexible JavaScript library for building user interfaces.
Vue 则是:A progressive, incrementally-adoptable JavaScript framework for building UI on the web.
### 它解决了什么问题
上面的一句话描述,它不能很好地说明,它能解决什么问题。
如下是今天在 GitHub Trending 上榜的 RPC 项目的简介:
> Most machines on internet communicate with each other via TCP/IP. However TCP/IP only guarantees reliable data transmissions, we need to abstract more to build services:
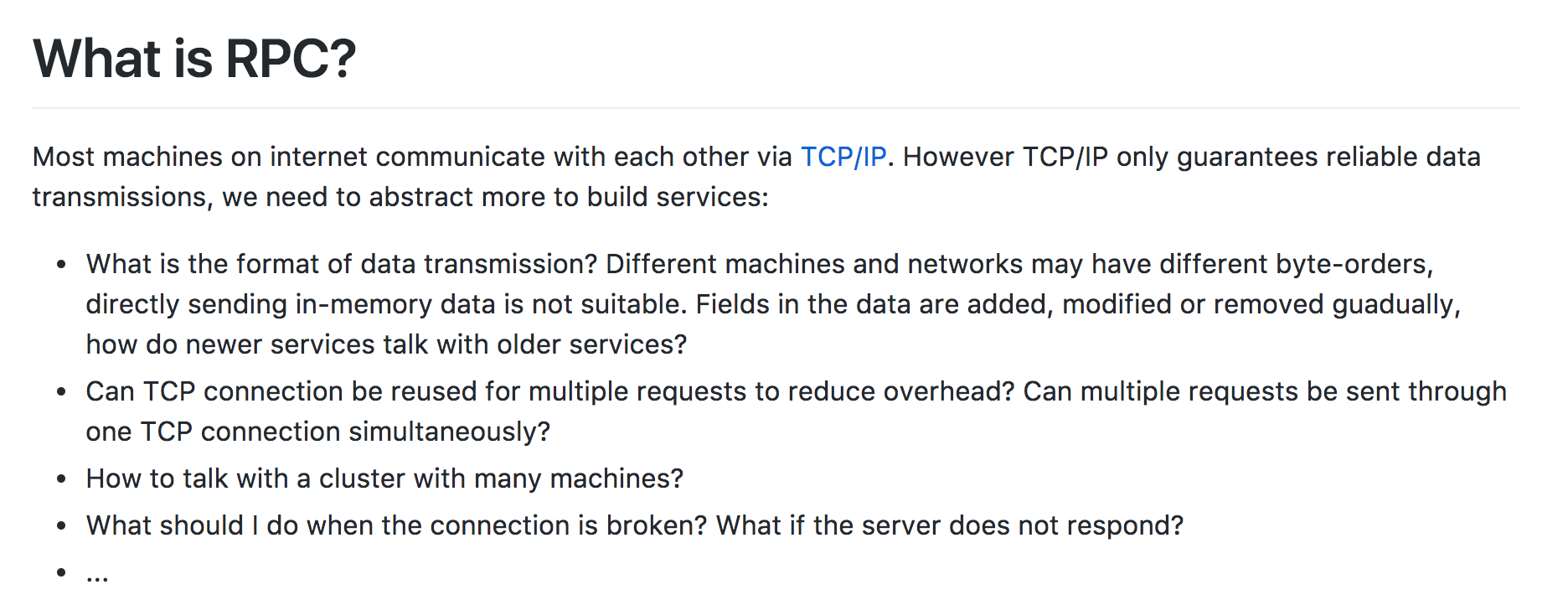
以上便是这个项目能解决的问题,不过这个项目能解决的问题倒是比较长,哈哈哈。
### 它有什么特性
当我们有 A、B、C 几个不同的框架的时候,作为一个开发人员,就需要对比他们的特性。如下是 Go 语言实现的 MQTT 示例:

这个项目只支持的 Qos 级别为 0。如果我们需要的级别是 1,那么就不能用这个项目了。
又比如 lodash 项目:
> Lodash makes JavaScript easier by taking the hassle out of working with arrays,
numbers, objects, strings, etc. Lodash’s modular methods are great for:
- Iterating arrays, objects, & strings
- Manipulating & testing values
- Creating composite functions
你会怎么写?脸皮够厚的话,可以直接写一下,与其它项目的对比,blabla:

当然了,这种事不能太过,要不然会招来一堆黑。
### 安装及 hello, world 示例
在我们看完了上面的介绍之后,紧接着接一个 hello, world 的示例。在运行 hello, world 之前,我们可能需要一些额外的安装工作,如:
```
npm install koa
```
如 Koa 的示例:
```
const Koa = require('koa');
const app = new Koa();
// response
app.use(ctx => {
ctx.body = 'Hello Koa';
});
app.listen(3000);
```
作为一个程序员,你应该懂得它的重要性。
好在这里的安装工作只有两步,而不是:

对于那些需要复杂的安装过程的软件,应该简化安装过程,如提供 Docker 镜像,或者直接提供一个可运行的 Demo 环境。以免用户在看完 README 之后,直接放弃了使用该库。
技术文档
---
好了,依一个开发人员的角度,如果上面的步骤一切顺利的话,接下来,便是使用这个开源项目来完成我们的功能。这个时候,我们开始转移注意力到文档上了。
由于,之前在某一个项目,经历过一个第三方 API 文档的大坑——文档中只罗列了 API 的用法。如下 Intellij Idea 生成的结构图:
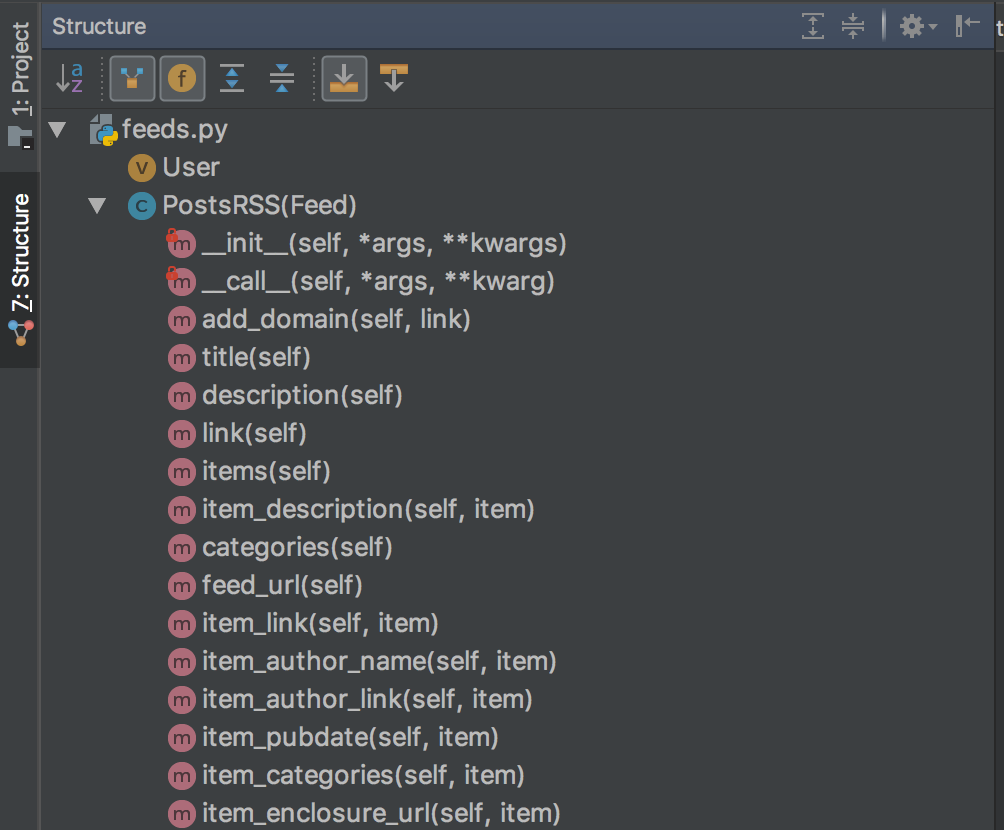
文档中上,罗列了每个函数,以及每个函数需要的参数。我使用 Intellij Idea 直接反编译 jar 包,看到的信息都比文档多多了。文档上,没有任务示例,甚至连怎么初始化这个库的代码都没有。
WTF!
### 技术文档
对于一个复杂的开源项目来说,文档上要写明安装、编译、配置等等的过程。如下图所示:
并且在我们发布包的时候,就要不断地去重复这个过程——如果你使用了自动化测试,那么这个过程便自动完成了。
如果我们的项目使用起来相当的简单,那么我们就可以只写一些示例代码即可。
并且,我们可以将文档直接入到代码里。它可以有效地减少文档不同步,带来的一些问题。

上图是使用了 JSDoc 的 Lodash 示例。
除了上面的示例,我们还可以录制一些视频,写一些文章说明项目的思考、架构等等。
### 更多的示例程序
示例代码本身也是文档的一部分,不要问我为什么~~。
反正,除了一个 hello, world,你还要有各种场景下的示例:

没有这么多示例,敢说自己是好用的开源项目?
### 编写技术文章、书籍
到目前为止,我们做了一系列 markdown 相关的工作,却也还没有结束。要知道只有真正写过一系列开源项目的人,才能体会到什么是 markdown 程序员~~。
官方文档,一般要以比较正式的口吻来描述过程,这种写法相当的压抑。如果要用轻松诙谐的口气,那么就可以写一系列的技术文章。假如这是一个前端框架,那么我们可以介绍它如何与某个后端框架配合使用;又或者是,它与某个框架的对比等等。
好了,一切顺利了,那么下一步就是吸引更多的人参与到项目上来了。
鼓励、吸引贡献者
---
要吸引其它开发人员来到你的项目,不是一件容易的事。
你需要不断地鼓励他/她们,并适时地帮他/她们解决问题,以避免他/她们在提 pull request 的过程中放弃了。这一点特别的有意思,当有一个开发人员发现了项目中的 bug,那么他/她会尝试去解决这个问题。与此同时,他/她还会为你的项目带来 pull request,但是在这个过程中,因为测试等等的问题,可能会阻碍他的 PR。这个时候,就需要我们主要去提示/教他们怎么做,又或者是帮他/她们解决完剩下的问题。那么,下次他/她提一个 PR 的时候,他/她就能解决问题了。
这一点可以在 README,以及介绍上体现:

哪怕只是一个错误字的 PR,那么你也可以 merge,啊哈哈~。然后,就有人帮你宣传了,『我给 xxx 项目一个 PR 了』。刚毕业的时候,我也是从这种类型的 PR 做起的~~。
开源项目维护
===
Release
---
Git 与 GitHub 工具推荐
===
Git 命令行增强
---
### [diff-so-fancy](https://github.com/so-fancy/diff-so-fancy)
### [git-extras](https://github.com/tj/git-extras)
**Ubuntu**
```
$ sudo apt-get install git-extras
```
**Mac OS X with Homebrew**
```
$ brew install git-extras
```
```
$ git-summary
project : github-roam
repo age : 2 years, 7 months
active : 40 days
commits : 124
files : 101
authors :
72 Fengda HUANG 58.1%
29 Fengda Huang 23.4%
8 Phodal HUANG 6.5%
3 Phodal Huang 2.4%
2 yangpei3720 1.6%
2 WangXiaolong 1.6%
2 TZS 1.6%
1 安正超 0.8%
1 Li 0.8%
1 Qiuer 0.8%
1 SCaffrey 0.8%
1 oncealong 0.8%
1 zminds 0.8%
```
Intellij IDEA
---
由于日常用的开发工是 Intellij IDEA 企业版,所以就有点依赖于这个工具了。最常用的功能便是:**修复 Bug 时,对于文件修改的追溯**。了解某行代码修改的原因,对应的修改人等等。
Intellij IDEA
Git、GitHub桌面增强
---
### SourceTree
SourceTree 方便用来查看一些非我写的项目,寻找其中的一些问题。个中缘由便是:**Intelli IDEA 刚打开某个项目的时候,需要花费大量的时间 index**,只可惜现有的 SourceTree 客户端都需要登录 Atlassian 账户了。
gitflow 分支合并、查看

### GitHub Desktop
Git 娱乐
---
### githug
```
$ githug
********************************************************************************
* Githug *
********************************************************************************
No githug directory found, do you wish to create one? [yn] y
Welcome to Githug!
Name: init
Level: 1
Difficulty: *
A new directory, `git_hug`, has been created; initialize an empty repository in it.
```
```
$ githug play
********************************************************************************
* Githug *
********************************************************************************
Congratulations, you have solved the level!
Name: config
Level: 2
Difficulty: *
Set up your git name and email, this is important so that your commits can be identified.
```
```
#1: init
#2: config
#3: add
#4: commit
#5: clone
#6: clone_to_folder
#7: ignore
#8: include
#9: status
#10: number_of_files_committed
#11: rm
#12: rm_cached
#13: stash
#14: rename
#15: restructure
#16: log
#17: tag
#...
```
### Gource

# GitHub 用户分析
## 生成图表
如何分析用户的数据是一个有趣的问题,特别是当我们有大量的数据的时候。除了 ``matlab``,我们还可以用 ``numpy`` + ``matplotlib``
数据可以在这边寻找到
[https://github.com/gmszone/ml](https://github.com/gmszone/ml)
最后效果图

要解析的 JSON 文件位于``data/2014-01-01-0.json``,大小 6.6M,显然我们可能需要用每次只读一行的策略,这足以解释为什么诸如 sublime 打开的时候很慢,而现在我们只需要里面的 JSON 数据中的创建时间。。
==, 这个文件代表什么?
**2014年1月1日零时到一时,用户在 GitHub 上的操作,这里的用户指的是很多。。一共有 4814 条数据,从 commit、create 到 issues 都有。**
### 数据解析
```python
import json
for line in open(jsonfile):
line = f.readline()
```
然后再解析 JSON
```python
import dateutil.parser
lin = json.loads(line)
date = dateutil.parser.parse(lin["created_at"])
```
这里用到了 ``dateutil``,因为新鲜出炉的数据是 string 需要转换为 ``dateutil``,再到数据放到数组里头。最后有就有了 ``parse_data``
```python
def parse_data(jsonfile):
f = open(jsonfile, "r")
dataarray = []
datacount = 0
for line in open(jsonfile):
line = f.readline()
lin = json.loads(line)
date = dateutil.parser.parse(lin["created_at"])
datacount += 1
dataarray.append(date.minute)
minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]
f.close()
return minuteswithcount
```
下面这句代码就是将上面的解析为
```python
minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]
```
这样的数组以便于解析
```python
[(0, 92), (1, 67), (2, 86), (3, 73), (4, 76), (5, 67), (6, 61), (7, 71), (8, 62), (9, 71), (10, 70), (11, 79), (12, 62), (13, 67), (14, 76), (15, 67), (16, 74), (17, 48), (18, 78), (19, 73), (20, 89), (21, 62), (22, 74), (23, 61), (24, 71), (25, 49), (26, 59), (27, 59), (28, 58), (29, 74), (30, 69), (31, 59), (32, 89), (33, 67), (34, 66), (35, 77), (36, 64), (37, 71), (38, 75), (39, 66), (40, 62), (41, 77), (42, 82), (43, 95), (44, 77), (45, 65), (46, 59), (47, 60), (48, 54), (49, 66), (50, 74), (51, 61), (52, 71), (53, 90), (54, 64), (55, 67), (56, 67), (57, 55), (58, 68), (59, 91)]
```
### Matplotlib
开始之前需要安装`matplotlib`
```bash
sudo pip install matplotlib
```
然后引入这个库
import matplotlib.pyplot as plt
如上面的那个结果,只需要
plt.figure(figsize=(8,4))
plt.plot(x, y,label = files)
plt.legend()
plt.show()
最后代码可见
```python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import json
import dateutil.parser
import numpy as np
import matplotlib.mlab as mlab
import matplotlib.pyplot as plt
def parse_data(jsonfile):
f = open(jsonfile, "r")
dataarray = []
datacount = 0
for line in open(jsonfile):
line = f.readline()
lin = json.loads(line)
date = dateutil.parser.parse(lin["created_at"])
datacount += 1
dataarray.append(date.minute)
minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]
f.close()
return minuteswithcount
def draw_date(files):
x = []
y = []
mwcs = parse_data(files)
for mwc in mwcs:
x.append(mwc[0])
y.append(mwc[1])
plt.figure(figsize=(8,4))
plt.plot(x, y,label = files)
plt.legend()
plt.show()
draw_date("data/2014-01-01-0.json")
```
## 每周分析
继上篇之后,我们就可以分析用户的每周提交情况,以得出用户的真正的工具效率,每个程序员的工作时间可能是不一样的,如

这是我的每周情况,显然如果把星期六移到前面的话,随着工作时间的增长,在 GitHub 上的使用在下降,作为一个
a fulltime hacker who works best in the evening (around 8 pm).
不过这个是 osrc 的分析结果。
### Python GitHub 每周情况分析
看一张分析后的结果

结果正好与我的情况相反?似乎图上是这么说的,但是数据上是这样的情况。
data
├── 2014-01-01-0.json
├── 2014-02-01-0.json
├── 2014-02-02-0.json
├── 2014-02-03-0.json
├── 2014-02-04-0.json
├── 2014-02-05-0.json
├── 2014-02-06-0.json
├── 2014-02-07-0.json
├── 2014-02-08-0.json
├── 2014-02-09-0.json
├── 2014-02-10-0.json
├── 2014-02-11-0.json
├── 2014-02-12-0.json
├── 2014-02-13-0.json
├── 2014-02-14-0.json
├── 2014-02-15-0.json
├── 2014-02-16-0.json
├── 2014-02-17-0.json
├── 2014-02-18-0.json
├── 2014-02-19-0.json
└── 2014-02-20-0.json
我们获取是每天晚上0点时的情况,至于为什么是0点,我想这里的数据量可能会比较少。除去1月1号的情况,就是上面的结果,在只有一周的情况时,总会以为因为在国内那时是假期,但是总觉得不是很靠谱,国内的程序员虽然很多,会在 GitHub 上活跃的可能没有那么多,直至列出每一周的数据时。
6570, 7420, 11274, 12073, 12160, 12378, 12897,
8474, 7984, 12933, 13504, 13763, 13544, 12940,
7119, 7346, 13412, 14008, 12555
### Python 数据分析
重写了一个新的方法用于计算提交数,直至后面才意识到其实我们可以算行数就够了,但是方法上有点hack
```python
def get_minutes_counts_with_id(jsonfile):
datacount, dataarray = handle_json(jsonfile)
minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]
return minuteswithcount
def handle_json(jsonfile):
f = open(jsonfile, "r")
dataarray = []
datacount = 0
for line in open(jsonfile):
line = f.readline()
lin = json.loads(line)
date = dateutil.parser.parse(lin["created_at"])
datacount += 1
dataarray.append(date.minute)
f.close()
return datacount, dataarray
def get_minutes_count_num(jsonfile):
datacount, dataarray = handle_json(jsonfile)
return datacount
def get_month_total():
"""
:rtype : object
"""
monthdaycount = []
for i in range(1, 20):
if i < 10:
filename = 'data/2014-02-0' + i.__str__() + '-0.json'
else:
filename = 'data/2014-02-' + i.__str__() + '-0.json'
monthdaycount.append(get_minutes_count_num(filename))
return monthdaycount
```
接着我们需要去遍历每个结果,后面的后面会发现这个效率真的是太低了,为什么木有多线程?
### Python Matplotlib图表
让我们的matplotlib来做这些图表的工作
```python
if __name__ == '__main__':
results = pd.get_month_total()
print results
plt.figure(figsize=(8, 4))
plt.plot(results.__getslice__(0, 7), label="first week")
plt.plot(results.__getslice__(7, 14), label="second week")
plt.plot(results.__getslice__(14, 21), label="third week")
plt.legend()
plt.show()
```
蓝色的是第一周,绿色的是第二周,红色的是第三周就有了上面的结果。
我们还需要优化方法,以及多线程的支持。
让我们分析之前的程序,然后再想办法做出优化。网上看到一篇文章[http://www.huyng.com/posts/python-performance-analysis/](http://www.huyng.com/posts/python-performance-analysis/)讲的就是分析这部分内容的。
## 存储到数据库中
### SQLite3
我们创建了一个名为 ``userdata.db`` 的数据库文件,然后创建了一个表,里面有 owner, language, eventtype, name url
```python
def init_db():
conn = sqlite3.connect('userdata.db')
c = conn.cursor()
c.execute('''CREATE TABLE userinfo (owner text, language text, eventtype text, name text, url text)''')
```
接着我们就可以查询数据,这里从结果讲起。
```python
def get_count(username):
count = 0
userinfo = []
condition = 'select * from userinfo where owener = \'' + str(username) + '\''
for zero in c.execute(condition):
count += 1
userinfo.append(zero)
return count, userinfo
```
当我查询 ``gmszone`` 的时候,也就是我自己就会有如下的结果
```bash
(u'gmszone', u'ForkEvent', u'RESUME', u'TeX', u'https://github.com/gmszone/RESUME')
(u'gmszone', u'WatchEvent', u'iot-dashboard', u'JavaScript', u'https://github.com/gmszone/iot-dashboard')
(u'gmszone', u'PushEvent', u'wechat-wordpress', u'Ruby', u'https://github.com/gmszone/wechat-wordpress')
(u'gmszone', u'WatchEvent', u'iot', u'JavaScript', u'https://github.com/gmszone/iot')
(u'gmszone', u'CreateEvent', u'iot-doc', u'None', u'https://github.com/gmszone/iot-doc')
(u'gmszone', u'CreateEvent', u'iot-doc', u'None', u'https://github.com/gmszone/iot-doc')
(u'gmszone', u'PushEvent', u'iot-doc', u'TeX', u'https://github.com/gmszone/iot-doc')
(u'gmszone', u'PushEvent', u'iot-doc', u'TeX', u'https://github.com/gmszone/iot-doc')
(u'gmszone', u'PushEvent', u'iot-doc', u'TeX', u'https://github.com/gmszone/iot-doc')
109
````
一共有109个事件,有 ``Watch``, ``Create``, ``Push``, ``Fork`` 还有其他的,
项目主要有``iot``, ``RESUME``, ``iot-dashboard``, ``wechat-wordpress``,
接着就是语言了,``Tex``, ``Javascript``, ``Ruby``,接着就是项目的 url 了。
值得注意的是。
```bash
-rw-r--r-- 1 fdhuang staff 905M Apr 12 14:59 userdata.db
```
这个数据库文件有 **905M**,不过查询结果相当让人满意,至少相对于原来的结果来说。
Python 自带了对 SQLite3 的支持,然而我们还需要安装 SQLite3
```bash
brew install sqlite3
```
或者是
```bash
sudo port install sqlite3
```
或者是 Ubuntu 的
```bash
sudo apt-get install sqlite3
```
openSUSE 自然就是
```bash
sudo zypper install sqlite3
```
不过,用 yast2 也很不错,不是么。。
### 数据导入
需要注意的是这里是需要 Python 2.7,起源于对 gzip 的上下文管理器的支持问题
```python
def handle_gzip_file(filename):
userinfo = []
with gzip.GzipFile(filename) as f:
events = [line.decode("utf-8", errors="ignore") for line in f]
for n, line in enumerate(events):
try:
event = json.loads(line)
except:
continue
actor = event["actor"]
attrs = event.get("actor_attributes", {})
if actor is None or attrs.get("type") != "User":
continue
key = actor.lower()
repo = event.get("repository", {})
info = str(repo.get("owner")), str(repo.get("language")), str(event["type"]), str(repo.get("name")), str(
repo.get("url"))
userinfo.append(info)
return userinfo
def build_db_with_gzip():
init_db()
conn = sqlite3.connect('userdata.db')
c = conn.cursor()
year = 2014
month = 3
for day in range(1,31):
date_re = re.compile(r"([0-9]{4})-([0-9]{2})-([0-9]{2})-([0-9]+)\.json.gz")
fn_template = os.path.join("march",
"{year}-{month:02d}-{day:02d}-{n}.json.gz")
kwargs = {"year": year, "month": month, "day": day, "n": "*"}
filenames = glob.glob(fn_template.format(**kwargs))
for filename in filenames:
c.executemany('INSERT INTO userinfo VALUES (?,?,?,?,?)', handle_gzip_file(filename))
conn.commit()
c.close()
```
``executemany`` 可以插入多条数据,对于我们的数据来说,一小时的文件大概有五六千个会符合我们上面的安装,也就是有 ``actor`` 又有 ``type`` 才是我们需要记录的数据,我们只需要统计用户的那些事件,而非全部的事件。
我们需要去遍历文件,然后找到合适的部分,这里只是要找``2014-03-01``到``2014-03-31``的全部事件,而光这些数据的 gz 文件就有 1.26G,同上面那些解压为 JSON 文件显得不合适,只能用遍历来处理。
这里参考了 osrc 项目中的写法,或者说直接复制过来。
首先是正规匹配
```python
date_re = re.compile(r"([0-9]{4})-([0-9]{2})-([0-9]{2})-([0-9]+)\.json.gz")
```
不过主要的还是在于 ``glob.glob``
> glob是 Python 自己带的一个文件操作相关模块,用它可以查找符合自己目的的文件,就类似于Windows下的文件搜索,支持通配符操作。
这里也就用上了 ``gzip.GzipFile`` 又一个不错的东西。
最后代码可以见
[github.com/gmszone/ml](http://github.com/gmszone/ml)
更好的方案?
### Redis
查询用户事件总数
```python
import redis
r = redis.StrictRedis(host='localhost', port=6379, db=0)
pipe = pipe = r.pipeline()
pipe.zscore('osrc:user',"gmszone")
pipe.execute()
```
系统返回了 ``227.0``,试试别人。
```bash
>>> pipe.zscore('osrc:user',"dfm")
>>> pipe.execute()
[425.0]
>>>
```
看看主要是在哪一天提交的
```python
>>> pipe.hgetall('osrc:user:gmszone:day')
>>> pipe.execute()
[{'1': '51', '0': '41', '3': '17', '2': '34', '5': '28', '4': '22', '6': '34'}]
```
结果大致如下图所示:

看看主要的事件是?
>>> pipe.zrevrange("osrc:user:gmszone:event".format("gmszone"), 0, -1,withscores=True)
>>> pipe.execute()
[[('PushEvent', 154.0), ('CreateEvent', 41.0), ('WatchEvent', 18.0), ('GollumEvent', 8.0), ('MemberEvent', 3.0), ('ForkEvent', 2.0), ('ReleaseEvent', 1.0)]]
>>>

蓝色的就是 push 事件,黄色的是 create 等等。
到这里我们算是知道了 OSRC 的数据库部分是如何工作的。
#### Redis 查询
主要代码如下所示
```python
def get_vector(user, pipe=None):
r = redis.StrictRedis(host='localhost', port=6379, db=0)
no_pipe = False
if pipe is None:
pipe = pipe = r.pipeline()
no_pipe = True
user = user.lower()
pipe.zscore(get_format("user"), user)
pipe.hgetall(get_format("user:{0}:day".format(user)))
pipe.zrevrange(get_format("user:{0}:event".format(user)), 0, -1,
withscores=True)
pipe.zcard(get_format("user:{0}:contribution".format(user)))
pipe.zcard(get_format("user:{0}:connection".format(user)))
pipe.zcard(get_format("user:{0}:repo".format(user)))
pipe.zcard(get_format("user:{0}:lang".format(user)))
pipe.zrevrange(get_format("user:{0}:lang".format(user)), 0, -1,
withscores=True)
if no_pipe:
return pipe.execute()
```
结果在上一篇中显示出来了,也就是
```
[227.0, {'1': '51', '0': '41', '3': '17', '2': '34', '5': '28', '4': '22', '6': '34'}, [('PushEvent', 154.0), ('CreateEvent', 41.0), ('WatchEvent', 18.0), ('GollumEvent', 8.0), ('MemberEvent', 3.0), ('ForkEvent', 2.0), ('ReleaseEvent', 1.0)], 0, 0, 0, 11, [('CSS', 74.0), ('JavaScript', 60.0), ('Ruby', 12.0), ('TeX', 6.0), ('Python', 6.0), ('Java', 5.0), ('C++', 5.0), ('Assembly', 5.0), ('C', 3.0), ('Emacs Lisp', 2.0), ('Arduino', 2.0)]]
```
有意思的是在这里生成了和自己相近的人
```
['alesdokshanin', 'hjiawei', 'andrewreedy', 'christj6', '1995eaton']
```
osrc 最有意思的一部分莫过于 flann,当然说的也是系统后台的设计的一个很关键及有意思的部分。
## 邻近算法与相似用户
邻近算法是在这个分析过程中一个很有意思的东西。
>邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法可以说是整个数据挖掘分类技术中最简单的方法了。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用她最接近的k个邻居来代表。
换句话说,我们需要一些样本来当作我们的分析资料,这里东西用到的就是我们之前的。
```
[227.0, {'1': '51', '0': '41', '3': '17', '2': '34', '5': '28', '4': '22', '6': '34'}, [('PushEvent', 154.0), ('CreateEvent', 41.0), ('WatchEvent', 18.0), ('GollumEvent', 8.0), ('MemberEvent', 3.0), ('ForkEvent', 2.0), ('ReleaseEvent', 1.0)], 0, 0, 0, 11, [('CSS', 74.0), ('JavaScript', 60.0), ('Ruby', 12.0), ('TeX', 6.0), ('Python', 6.0), ('Java', 5.0), ('C++', 5.0), ('Assembly', 5.0), ('C', 3.0), ('Emacs Lisp', 2.0), ('Arduino', 2.0)]]
```
在代码中是构建了一个 points.h5 的文件来分析每个用户的 points,之后再记录到 hdf5 文件中。
```
[ 0.00438596 0.18061674 0.2246696 0.14977974 0.07488987 0.0969163
0.12334802 0.14977974 0. 0.18061674 0. 0. 0.
0.00881057 0. 0. 0.03524229 0. 0.
0.01321586 0. 0. 0. 0.6784141 0.
0.07929515 0.00440529 1. 1. 1. 0.08333333
0.26431718 0.02202643 0.05286344 0.02643172 0. 0.01321586
0.02202643 0. 0. 0. 0. 0. 0.
0. 0. 0.00881057 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0.00881057]
```
这里分析到用户的大部分行为,再找到与其行为相近的用户,主要的行为有下面这些:
- 每星期的情况
- 事件的类型
- 贡献的数量,连接以及语言
- 最多的语言
osrc 中用于解析的代码
```python
def parse_vector(results):
points = np.zeros(nvector)
total = int(results[0])
points[0] = 1.0 / (total + 1)
# Week means.
for k, v in results[1].iteritems():
points[1 + int(k)] = float(v) / total
# Event types.
n = 8
for k, v in results[2]:
points[n + evttypes.index(k)] = float(v) / total
# Number of contributions, connections and languages.
n += nevts
points[n] = 1.0 / (float(results[3]) + 1)
points[n + 1] = 1.0 / (float(results[4]) + 1)
points[n + 2] = 1.0 / (float(results[5]) + 1)
points[n + 3] = 1.0 / (float(results[6]) + 1)
# Top languages.
n += 4
for k, v in results[7]:
if k in langs:
points[n + langs.index(k)] = float(v) / total
else:
# Unknown language.
points[-1] = float(v) / total
return points
```
这样也就返回我们需要的点数,然后我们可以用 ``get_points`` 来获取这些
```python
def get_points(usernames):
r = redis.StrictRedis(host='localhost', port=6379, db=0)
pipe = r.pipeline()
results = get_vector(usernames)
points = np.zeros([len(usernames), nvector])
points = parse_vector(results)
return points
```
就会得到我们的相应的数据,接着找找和自己邻近的,看看结果。
```
[ 0.01298701 0.19736842 0. 0.30263158 0.21052632 0.19736842
0. 0.09210526 0. 0.22368421 0.01315789 0. 0.
0. 0. 0. 0.01315789 0. 0.
0.01315789 0. 0. 0. 0.73684211 0. 0.
0. 1. 1. 1. 0.2 0.42105263
0.09210526 0. 0. 0. 0. 0.23684211
0. 0. 0.03947368 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. ]
```
真看不出来两者有什么相似的地方 。。。。
如何在 GitHub "寻找灵感(fork)"
===
> 重造轮子是重新创造一个已有的或是已被其他人优化的基本方法。
最近萌发了一个想法写游戏引擎,之前想着做一个 JavaScript 前端框架。看看,这个思路是怎么来的。
## Lettuce 构建过程
> Lettuce 是一个简约的移动开发框架。
故事的出发点是这样的:``写了很多代码,用的都是框架,最后不知道收获什么了``?事实也是如此,当自己做了一些项目之后,发现最后什么也没有收获到。于是,就想着做一个框架。
### 需求
有这样的几个前提
- 为什么我只需要 jQuery 里的选择器、Ajax 要引入那么重的库呢?
- 为什么我只需要一个 Template,却想着用 Mustache
- 为什么我需要一个 Router,却要用 Backbone 呢?
- 为什么我需要的是一个 isObject 函数,却要用到整个 Underscore?
我想要的只是一个简单的功能,而我不想引入一个庞大的库。换句话说,我只需要不同库里面的一小部分功能,而不是一个库。
实际上想要的是:
> 构建一个库,里面从不同的库里面抽取出不同的函数。
### 计划
这时候我参考了一本电子书《Build JavaScript FrameWork》,加上一些平时的需求,于是很快的就知道自己需要什么样的功能:
- Promise 支持
- Class类(PS:没有一个好的类使用的方式)
- Template 一个简单的模板引擎
- Router 用来控制页面的路由
- Ajax 基本的 Ajax Get/Post 请求
在做一些实际的项目中,还遇到了这样的一些功能支持:
- Effect 简单的一些页面效果
- AMD 支持
而我们有一个前提是要保持这个库尽可能的小、同时我们还需要有测试。
### 实现第一个需求
简单说说是如何实现一个简单的需求。
#### 生成框架
因为 Yeoman 可以生成一个简单的轮廓,所以我们可以用它来生成这个项目的骨架。
- Gulp
- Jasmine
#### 寻找
在 GitHub 上搜索了一个看到了下面的几个结果:
- [https://github.com/then/promise](https://github.com/then/promise)
- [https://github.com/reactphp/promise](https://github.com/reactphp/promise)
- [https://github.com/kriskowal/q](https://github.com/kriskowal/q)
- [https://github.com/petkaantonov/bluebird](https://github.com/petkaantonov/bluebird)
- [https://github.com/cujojs/when](https://github.com/cujojs/when)
但是显然,他们都太重了。事实上,对于一个库来说,80% 的人只需要其中 20% 的代码。于是,找到了[https://github.com/stackp/promisejs](https://github.com/stackp/promisejs),看了看用法,这就是我们需要的功能:
```javascript
function late(n) {
var p = new promise.Promise();
setTimeout(function() {
p.done(null, n);
}, n);
return p;
}
late(100).then(
function(err, n) {
return late(n + 200);
}
).then(
function(err, n) {
return late(n + 300);
}
).then(
function(err, n) {
return late(n + 400);
}
).then(
function(err, n) {
alert(n);
}
);
```
接着打开看看 Promise 对象,有我们需要的功能,但是又有一些功能超出我的需求。接着把自己不需要的需求去掉,这里函数最后就变成了
```javascript
function Promise() {
this._callbacks = [];
}
Promise.prototype.then = function(func, context) {
var p;
if (this._isdone) {
p = func.apply(context, this.result);
} else {
p = new Promise();
this._callbacks.push(function () {
var res = func.apply(context, arguments);
if (res && typeof res.then === 'function') {
res.then(p.done, p);
}
});
}
return p;
};
Promise.prototype.done = function() {
this.result = arguments;
this._isdone = true;
for (var i = 0; i < this._callbacks.length; i++) {
this._callbacks[i].apply(null, arguments);
}
this._callbacks = [];
};
var promise = {
Promise: Promise
};
```
需要注意的是:``License``,不同的软件有不同的 License,如 MIT、GPL 等等。最好能在遵循协议的情况下,使用别人的代码。
### 实现第二个需求
由于已经有了现有的很多库,所以就可以直接参照(抄)别人写的代码。
```javascript
Lettuce.get = function (url, callback) {
Lettuce.send(url, 'GET', callback);
};
Lettuce.load = function (url, callback) {
Lettuce.send(url, 'GET', callback);
};
Lettuce.post = function (url, data, callback) {
Lettuce.send(url, 'POST', callback, data);
};
Lettuce.send = function (url, method, callback, data) {
data = data || null;
var request = new XMLHttpRequest();
if (callback instanceof Function) {
request.onreadystatechange = function () {
if (request.readyState === 4 && (request.status === 200 || request.status === 0)) {
callback(request.responseText);
}
};
}
request.open(method, url, true);
if (data instanceof Object) {
data = JSON.stringify(data);
request.setRequestHeader('Content-Type', 'application/json');
}
request.setRequestHeader('X-Requested-With', 'XMLHttpRequest');
request.send(data);
};
```
如何以“正确的姿势”阅读开源软件代码
===
> 所有让你直接看最新源码的文章都是在扯淡,你应该从“某个版本”开始阅读代码。
我们并不建议所有的读者都直接看最新的代码,正确的姿势应该是:
- clone 某个项目的代码到本地
- 查看这个项目的 release 列表
- 找到一个看得懂的 release 版本,如 1.0 或者更早的版本
- 读懂上一个版本的代码
- 向后阅读大版本的源码
- 读最新的源码
最好的在这个过程中,**可以自己造轮子来实现一遍**。
## 阅读过程
在我阅读的前端库、Python 后台库的过程中,我们都是以造轮子为目的展开的。所以在最开始的时候,我需要一个可以工作,并且拥有我想要的功能的版本。

紧接着,我就可以开始去实践这个版本中的一些功能,并理解他们是怎么工作的。再用 `git` 大法展开之前修改的内容,可以使用 IDE 自带的 Diff 工具:

或者类似于 `SourceTree` 这样的工具,来查看修改的内容。
在我们理解了基本的核心功能后,我们就可以向后查看大、中版本的更新内容了。
开始之前,我们希望大家对版本号管理有一些基本的认识。
## 版本号管理
我最早阅读的开始软件是 Linux,而下面则是 Linux 的 Release 过程:

表格源自一本书叫《Linux内核0.11(0.95)完全注释》,简单地再介绍一下:
- 版本 0.00 是一个 hello, world 程序
- 版本 0.01 包含了可以工作的代码
- 版本 0.11 是基本可以正常的版本
这里就要扯到《GNU 风格的版本号管理策略》:
1. 项目初版本时,版本号可以为 0.1 或 0.1.0, 也可以为 1.0 或 1.0.0,如果你为人很低调,我想你会选择那个主版本号为 0 的方式;
2. 当项目在进行了局部修改或 bug 修正时,主版本号和子版本号都不变,修正版本号加 1;
3. 当项目在原有的基础上增加了部分功能时,主版本号不变,子版本号加 1,修正版本号复位为 0,因而可以被忽略掉;
4. 当项目在进行了重大修改或局部修正累积较多,而导致项目整体发生全局变化时,主版本号加 1;
5. 另外,编译版本号一般是编译器在编译过程中自动生成的,我们只定义其格式,并不进行人为控制。
因此,我们可以得到几个简单的结论:
- 我们需要阅读最早的有核心代码的版本
- 我们需要阅读 1.0 版本的 Release
- 往后每一次大的 Release 我们都需要了解一下
## 示例
以 Flask 为例:
一、先 Clone 它。

二、从 Release 页面找到它的早期版本:

三、 从上面拿到它的提交号 `8605cc3`,然后 checkout 到这次提交,查看功能。在这个版本里,一共有六百多行代码

还是有点长
四、我们可以找到它的最早版本:

然后查看它的 `flask.py` 文件,只有简单的三百多行,并且还包含一系列注释:

五、接着,再回过头去阅读
- 0.1 版本
- 。。。
- 最新的 0.10.1 版本
GitHub 连击
===
## 100 天
我也是蛮拼的,虽然我想的只是在 GitHub 上连击 100~200 天,然而到了今天也算不错。

``在不停地造轮子的过程中,也不停地造车子。``
在那篇连续冲击 365 天的文章出现之前,我们公司的大大([https://github.com/dreamhead](https://github.com/dreamhead))也曾经在公司内部说过,天天 commit 什么的。当然这不是我的动力,在连击 140 天之前
- 给过 Google 的``ngx_speed``、``node-coap`` 等项目创建过 pull request
- 也有``free-programming-books``、``free-programming-books-zh_CN``这样的项目。
- 当然还有一个连击 20 天。
对比了一下 365 天连击的 commit,我发现我在 total 上整整多了近 0.5 倍。

同时这似乎也意味着,我每天的 commit 数与之相比多了很多。
在连击20的时候,有这样的问题:*为了 commit 而 commit 代码*,最后就放弃了。
而现在是``为了填坑而 commit``,为自己挖了太多的想法。
### 40 天的提升
当时我需要去印度接受毕业生培训,大概有 5 周左右,想着总不能空手而归。于是在国庆结束后有了第一次 commit,当时旅游归来,想着自己在不同的地方有不同的照片,于是这个 repo 的名字是 [onmap](https://github.com/phodal/onmap)——将自己的照片显示在地图上的拍摄地点(手机是 Lumia 920)。然而,中间因为修改账号的原因,丢失了 commit。
再从印度说起,当时主要维护三个 repo:
- 物联网的 CoAP 协议
- [一步步设计物联网系统](https://github.com/phodal/designiot)的电子书
- 一个 Node.js + JS 的网站
说说最后一个,最后一个是练习的项目。因为当时培训比较无聊,业余时间比较多,英语不好,加上听不懂印度人的话。晚上基本上是在住的地方默默地写代码,所以当时的目标有这么几个:
- TDD
- 测试覆盖率
- 代码整洁
这也就是为什么那个 repo 有这样的一行:

做到 98% 的覆盖率也算蛮拼的,当然还有 Code Climate 也达到了 4.0,也有了 112 个 commits。因此也带来了一些提高:
- 提高了代码的质量(code climate 比 jslint 更注重重复代码等等一些 bad smell)。
- 对于 Mock、Stub、FakesServer 等用法有更好的掌握
- 可以持续地交付软件(版本管理、自动测试、CI、部署等等)
### 100 天的挑战
(PS:从印度回来之后,由于女朋友在泰国实习,有了更多的时间可以看书、写代码)
有意思的是越到中间的一些时间,commits 的次数上去了,除了一些简单的 pull request,还有一些新的轮子出现了。

这是上一星期的 commits,这也就意味着,在一星期里面,我需要在 8 个 repo 里切换。而现在我又有了一个新的 idea,这时就发现了一堆的问题:
- 今天工作在这个 repo 上,突然发现那个 repo 上有 issue,需要去修复,于是就放下了当前的代码。
- 在不同的 repo 间切换容易分散精力
- 很容易就发现有太多的功能可以实现,但是时间是有限的。
- 没有足够的空闲时间,除了周末。
- 希望去寻找那些有兴趣的人,然而却发现原来没有那么多时间去找人。
### 140 天的希冀
在经历了 100 天之后,似乎整个人都轻松了,毕竟目标是 100~200 天。似乎到现在,也不会有什么特殊的情怀,除了一些希冀。
当然,对于一个开源项目的作者来说,最好有下面的情况:
- 很多人知道了这个项目
- 很多人用它的项目。
- 在某些可以用这个项目快速解决问题的地方提到了这个项目
- 提了 bug、issue、问题。
- 提了 bug,并解决了。(PS:这是最理想的情况)
## 200 天的 Showcase
今天是我连续泡在 GitHub 上的第200天,也是蛮高兴的,终于到达了:
故事的背影是:去年国庆完后要去印度接受毕业生培训——就是那个神奇的国度。但是在去之前已经在项目待了九个多月,项目上的挑战越来越少,在印度的时间又算是比较多。便给自己设定了一个长期的 goal,即 100~200 天的 longest streak。
或许之前你看到过一篇文章[让我们连击](https://github.com/phodal/github-roam/blob/master/chapters/12-streak-your-github.md),那时已然 140 天,只是还是浑浑噩噩。到了今天,渐渐有了一个更清晰地思路。
先让我们来一下 ShowCase,然后再然后,下一篇我们再继续。
### 一些项目简述
上面说到的培训一开始是用 Java 写的一个网站,有自动测试、CI、CD 等等。由于是内部组队培训,代码不能公开等等因素,加之做得无聊。顺手,拿 Node.js +RESTify 做了 Server,Backbone + RequireJS + jQuery 做了前台的逻辑。于是在那个日子里,也在维护一些旧的 repo,如 [iot-coap](https://github.com/phodal/iot-coap)、[iot](https://github.com/phodal/iot),前者是我拿到 WebStorm 开源 License 的 Repo,后者则是毕业设计。
对于这样一个项目也需要有测试、自动化测试、CI 等等。CI 用的是 Travics-CI。总体的技术构架如下:
#### 技术栈
前台:
- Backbone
- RequireJS
- Underscore
- Mustache
- Pure CSS
后台:
- RESTify
测试:
- Jasmine
- Chai
- Sinon
- Mocha
- Jasmine-jQuery
一直写到五星期的培训结束,只是没有自动部署。想想就觉得可以用 github-page 的项目多好~~。
过程中还有一些有意思的小项目,如:
### Google Maps solr polygon 搜索
[Google Maps solr polygon 搜索](http://www.phodal.com/blog/google-map-width-solr-use-polygon-search/)

代码:[https://github.com/phodal/gmap-solr](https://github.com/phodal/gmap-solr)
### 技能树
这个可以从两部分说起:
#### 重构 Skill Tree
原来的是
- Knockout
- RequireJS
- jQuery
- Gulp

代码:[https://github.com/phodal/skillock](https://github.com/phodal/skillock)
#### 技能树 Sherlock
- D3.js
- Dagre-D3.js
- jquery.tooltipster.js
- jQuery
- Lettuce
- Knockout.js
- Require.js

代码:[https://github.com/phodal/sherlock](https://github.com/phodal/sherlock)
#### Django Ionic ElasticSearch 地图搜索

- ElasticSearch
- Django
- Ionic
- OpenLayers 3
代码:[https://github.com/phodal/django-elasticsearch](https://github.com/phodal/django-elasticsearch)
#### 简历生成器

- React
- jsPDF
- jQuery
- RequireJS
- Showdown
代码:[https://github.com/phodal/resume](https://github.com/phodal/resume)
#### Nginx 大数据学习

- ElasticSearch
- Hadoop
- Pig
代码:[https://github.com/phodal/learning-data/tree/master/nginx](https://github.com/phodal/learning-data/tree/master/nginx)
#### 其他
虽然技术栈上主要集中在 Python、JavaScript,当然还有一些 Ruby、Pig、Shell、Java 的代码,只是我还是习惯用 Python 和 JavaScript。一些用到觉得不错的框架:
- Ionic:开始 Hybird 移动应用。
- Django:Python Web 开发利器。
- Flask:Python Web 开发小刀。
- RequireJS:管理 JS 依赖。
- Backbone:Model + View + Router。
- Angluar:...。
- Knockout:MVV*。
- React:据说会火。
- Cordova:Hybird 应用基础。
还应该有
- ElasticSearch
- Solr
- Hadoop
- Pig
- MongoDB
- Redis
## 365 天
> 给你一年的时间,你会怎样去提高你的水平???

正值这难得的 sick leave(万恶的空气),码文一篇来记念一个过去的 366 天里。尽管想的是在今年里写一个可持续的开源框架,但是到底这依赖于一个好的 idea。在我的 [GitHub 孵化器](http://github.com/phodal/ideas) 页面上似乎也没有一个特别让我满意的想法,虽然上面有各种不样有意思的 ideas。多数都是在过去的一年是完成的,然而有一些也是还没有做到的。
尽管一直在 GitHub 上连击看上去似乎是没有多大必要的,但是人总得有点追求。如果正是漫无目的,却又想着提高技术的同时,为什么不去试试?毕竟技术非常好、不需要太多练习的人只是少数,似乎这样的人是不存在的。大多数的人都是经过练习之后,才会达到别人口中的“技术好”。
这让我想起了充斥着各种气味的知乎上的一些问题,在一些智商被完虐的话题里,无一不是因为那些人学得比别人早——哪来的天才?所谓的天才,应该是未来的智能生命一般,一出生什么都知道。如果并非如此,那只是说明他练习到位了。
练习不到位便意味着,即使你练习的时候是一万小时的两倍,那也是无济于事的。如果你学得比别人晚,在**很长的一段时间里**(可能直到进棺材)输给别人是必然的——落后就要挨打。就好像我等毕业于一所二本垫底的学校里,如果在过去我一直保持着和别人(各种重点)一样的学习速度,那么我只能一直是 Loser。
需要注意的是,对你来说考上二本很难,并不是因为你比别人笨。教育资源分配不均的问题,在某种程度上导致了新的阶级制度的出现。如[我的首页](https://www.phodal.com/)说的那样:**THE ONLY FAIR IS NOT FAIR**——唯一公平的是它是不公平的。我们可以做的还有很多——**CREATE & SHARE**。真正的不幸是,因为营养不良导致的教育问题。
于是在想明白了很多事的时候起,便有了 Re-Practise 这样的计划,而 365 天只是中间的一个产物。
### 编程的基础能力
虽说算法很重要,但是编码才是基础能力。算法与编程在某种程度上是不同的领域,算法编程是在编程上面的一级。算法写得再好,如果别人很难直接拿来复用,在别人眼里就是 shit。想出能 work 的代码一件简单的事,学会对其重构,使之变得更易读就是一件有意义的事。
于是,在某一时刻在 GitHub 上创建了一个组织,叫 [Artisan Stack](https://github.com/artisanstack)。当时想的是在 GitHub 寻找一些 JavaScript 项目,对其代码进行重构。但是到底是影响力不够哈,参与的人数比较少。
#### 重构
如果你懂得如何写出高可读的代码,那么我想你是不需要这个的,但是这意味着你花了更多的时候在思考上了。当谈论重构的时候,让我想起了 TDD(测试驱动开发)。即使不是 TDD,那么如果你写着测试,那也是可以重构的。(之前写过一些利用 Intellij IDEA 重构的文章:[提炼函数](https://www.phodal.com/blog/intellij-idea-refactor-extract-method/)、[以查询取代临时变量](https://www.phodal.com/blog/intellij-idea-refactor-replace-temp-with-query/)、[重构与 Intellij Idea 初探](https://www.phodal.com/blog/thoughtworks-refactor-and-intellij-idea/)、[内联函数](https://www.phodal.com/blog/intellij-idea-refactor-inline-method/))
在各种各样的文章里,我们看到过一些相关的内容,最好的参考莫过于《重构》一书。最基础不过的原则便是函数名,取名字很难,取别人能读懂的名字更难。其他的便有诸如长函数、过大的类、重复代码等等。在我有限的面试别人的经历里,这些问题都是最常见的。
#### 测试
而如果没有测试,其他都是扯淡。写好测试很难,写个测试算是一件容易的事。只是有些容易我们会为了测试而测试。
在我写 [EchoesWorks](https://github.com/echoesworks/echoesworks) 和 [Lan](https://github.com/phodal/lan) 的过程中,我尽量去保证足够高的测试覆盖率。


从测试开始的 TDD,会保证方法是可测的。从功能到测试则可以提供工作次效率,但是只会让测试成为测试,而不是代码的一部分。
测试是代码的最后一公里。所以,尽可能的为你的 GitHub 上的项目添加测试。
#### 编码的过程
初到 TW 时,Pair 时候总会有人教我如何开始编码,这应该也是一项基础的能力。结合日常,重新演绎一下这个过程:
1. 有一个可衡量、可实现、过程可测的目标
2. Tasking(即对要实现的目标过程进行分解)
3. 一步步实现(如 TDD)
4. 实现目标
放到当前的场景就是:
1. 我想在 GitHub 上连击 365 天。对应于每一个时候段的目标都应该是可以衡量、测试的——即每天都会有 Contributions。
2. 分解就是一个痛苦的过程。理想情况下,我们应该会有每天提交,但是这取决于你的 repo 的数量,如果没有新的 idea 出现,那么这个就变成为了 Contributions 而 Commit。
3. 一步步实现
在我们实际工作中也是如此,接到一个任务,然后分解,一步步完成。不过实现会稍微复杂一些,因为事务总会有抢占和优先级的。
### 技术与框架设计
在上上一篇博客中《[After 500:写了第 500 篇博客,然后呢?](https://www.phodal.com/blog/after-500-blogposts-analytics-after-tech/)》也深刻地讨论了下这个问题,技术向来都是后发者优势。对于技术人员来说,也是如此,后发者占据很大的优势。
如果我们只是单纯地把我们的关注点仅仅放置于技术上,那么我们就不具有任何的优势。而依赖于我们的编程经验,我们可以在特定的时候创造一些框架。而架构的设计本身就是一件有意思的事,大抵是因为程序员都喜欢创造。(PS:之前曾经写过这样一篇文章,《[对不起,我并不热爱编程,我只喜欢创造](https://www.phodal.com/blog/sorry-i-don't-like-programming/)》)
**创造是一种知识的再掌握过程。**
回顾一下写 echoesworks 的过程,一开始我需要的是一个网页版的 PPT,当然这类的东西已经有很多了,如 impress.js、bespoke.js 等等。分析一下所需要的功能:markdown 解析器、键盘事件处理、Ajax、进度条显示、图片处理、Slide。我们可以在 GitHub 上找到各式各样的模块,我们所要做的就是将之结合在一样。在那之前,我试着用类似的原理写(组合)了 [Lettuce](https://github.com/phodal/lettuce)。
组合相比于创造过程是一个更有挑战性的过程,我们需要在这过程去设计胶水来粘合这些代码,并在最终可以让他工作。这好比是我们在平时接触到的任务划分,每个人负责相应的模块,最后整合。
我在写 [lan](https://github.com/phodal/lan) 的时候,也是类似的,但是不同的是我已经设计了一个清晰的架构图。

而在我们实现的编码过程也是如此,使用不同的框架,并且让他们能工作。如早期玩的 [moqi.mobi](https://github.com/echoesworks/moqi.mobi),基于 Backbone、RequireJS、Underscore、Mustache、Pure CSS。在随后的时间里,用 React 替换了 View 层,就有了 [backbone-react](https://github.com/phodal/backbone-react) 的练习。
技术同人一样,需要不断地往高一级前进。我们只需要不断地 Re-Practise。
### 领域与练习
说业务好像不太适合程序员的口味,那就领域吧。不同行业的人,如百度、阿里、腾讯,他们的领域核心是不一样的。
而领域本身也是相似的,这可以解释为什么互联网公司都喜欢互相挖人,而一般都不会去华为、中兴等非互联网领域挖人。出了这个领域,你可能连个毕业生都不如。领域、业务同技术一样是不断强化知识的一个过程。Ritchie 先实现了 BCPL 语言,而后设计了 C 语言,而 BCPL 语言一开始是基于 CPL 语言。
领域本身也在不断进化。
这也是下一个值得提高的地方。
### 其他
是时候写这个小结了。从不会写代码,到写代码是从 0 到 1 的过程,但是要从 1 到 60 都不是一件容易的事。无论是刷 GitHub 也好(不要是自动提交),或者是换工作也好,我们都在不断地练习。
而练习是要分成不同的几个步骤,不仅仅局限于技术:
1. 编码
2. 架构
3. 设计
4. 。。。
---
## 500 天
尽管之前已经有 100 天、200 天、365 天的文章,但是这不是一篇象征性的 500 天的文章。对这样的一个事物,每个人都会有不同听看法。有的会说这是一件好事,有的则不是。但是别人的看法终究不重要,因为了解你自己的只有你自己。别人都只是以他们的角度来提出观点。
在这 500 天里,我发现两点有意思的事,也是总结的时候才意识到的:
1. 编程的情绪周期
2. 有意图的练习
那么,当我们不断地练习的时候,我们就可以写出更好的代码。
我想你也听过一万小时天才理论的说法:要成为某个领域的专家,需要 10000 小时。而在这其中最重要的一点是有意图的练习——而不是一直重复性地用不同的语言去写一个相同的算法。如果我们有一天 8 小时的工作时间 + 2 小时的提高时间,那么我们还是需要 1000 天才能实现一万小时。
### 500 天与10000 小时
当然如果你连做梦也在写代码的话,那么我想 500 天就够了,哈哈~~。
虽然不是连击次数最多的,但是根据 [Most active GitHub users ](http://git.io/top) 的结果来说,好似是大陆提交数最多的人,没有之一。再考虑到提交都是有意义的——不是机器刷出来的,不是有意识的去刷,我觉得还是有很大成就感的。
而要实现 500 天连击很重要的两点是:时间和 idea。但是我觉得 idea 并不是非常重要的,我们可以造轮子,这一点就是在早期我做得最多的一件事,不断地造轮子——如《[造轮子与从Github生成轮子](https://www.phodal.com/blog/create-framework-from-github/)》一文中所说。除此,你还可以用《[GitHub去管理你的idea](https://www.phodal.com/blog/use-github-manage-idea/)》,每当你想到一个 Idea 以及完成一个 idea 的时间你就会多一次提交。
时间则是一件很讽刺的事,因为人们要加班。加班的原因,要么是因为工作的内容很有意思,要么是因为钱。如果不是因为钱的话,为什么不去换个工作呢?比如我司。看似两者间存在很多的对立,但是我总在想技术的提升可以在后期解决收入的问题,而不需要靠加班来解决这个问题。人总是要活着的,钱是必需的,但是程序员的收入都不低。
### 编程的情绪周期
接着,我观察到了一些有意思的现象——编程的情绪周期也很明显。
> 所谓“情绪周期”,是指一个人的情绪高潮和低潮的交替过程所经历的时间。
如下图所示的就是情绪周期:

简单地来说,就是**有一个时间段写代码的感觉超级爽,有一个时间段不想写代码**,但是如果换一个说法就是:**有一个时间段看书、写文档的感觉很爽,有一时间段不想看书、写文档的感觉**。这也就是为什么在我的GitHub首页上的绿色各种花。不过因为《物联网周报》的原因,我会定期地更新一个相关的开源项目。
但是总来说,我习惯在一些时间造一些轮子、创建文档,这就是为什么我的GitHub会有一些开源电子书的缘故。
### 有意图的练习
编程需要很长的学习时间,也需要很长的练习时间。尽管我是从小学编程,自认为天赋不错,但是突破了上个门槛还是花费了三四年的时间。其中的很大一部分原因是,没有找对一个合适的方向。而在这期间也没有好好的练习,随后的日子里我意识到我会遇到下一个门槛,便开始试图有意识的练习。
在我开始工作的时候,我写了一篇名为《[重新思考工作](https://www.phodal.com/blog/rethink-about-the-work/)》的文章。在文章中我提到了几点练习的点:
- 加强码代码的准确性
- 写出更整洁的代码
- 英语口语 (外企)
- 针对性的加强语言技能
在一些日子的练习后,我发现这还是太无聊了。天生就喜欢一些有意思的东西,有趣才更有激情吧~~。不过,像下图的打字练习还是挺有意思的:

还是能打出了一堆错误的字符。但是对比了一下大多数人的人,还算不错,至少是盲打。但是,还是存在着很大的提升空间。
随后,我开始一些错误的练习,如对设计模式和架构的练习。试图去练习一些在生产上用不到的设计模式,以及一些架构模式。而这时就意味着,需要生搬一些设计模式。最后,我开始以项目为目的的练习,这就是为什么我的GitHub上的提交数会有如此多的原因。
### 预见性练习
还有一种练习比较有意思,算是以工作为导向的练习。当我们预见到我们的项目需要某一些技术,我们可能在未来采用某些技术的时候,我们就需要开始预见性的练习这些技术。
好的一点是:这些项目可能在未来很受初学者欢迎。
### 小结
每个人都有自己的方向,都有一个不错的发展路线,分享和创造都是不错的路。
THE ONLY FAIR IS NOT FAIR . ENJOY CREATE & SHARE.
## 365*2-7天里
刚毕业的时候,有一段时间我一直困惑于如何去提高编码能力——因为项目上做的东西多数时候和自己想要的是不一样的,我便想着自己去找一些有意思的东西做着玩,在这个过程中边练习技能。
> 如果你知道自己代码能力不够,为什么不花两年时间去提高这方面的能力呢?
### 编码的练习
编码是一件值得练习的事,你从书中、互联网上看到的那一个个的编程大牛无一不是从一点点的小技能积累起来的。从小接触可以让你有一个好的开始,一段好好的练习也会帮助你更好的前进。
记得我在最开始练习的时候,我分几个不同的阶段去练习:
- 按照《重构:改善即有代码的设计》一书边寻找一些 bad smell 的代码,一边想方设法去让代码变得优雅。
- 按照《设计模式》以及《重构与模式》来将代码重构成某种设计模式。
- 按照《面向模式的软件架构》去设计一些软件架构。
而这些并不是一种容易的事,很多时候有一些模式,我们都很难有一个好的实践。只是这些东西都不是一些可以生搬硬套的,我们更需要的是知道有这些东西的存在,以便于在某一天,我们可以从我们的仓库里将这些知识取出来。

我们的刻意练习加上我们的持之以恒总是会取得长足的进步。不过在我们练习之前,你需要有一个目标。这个目标可以是一个 Idea、一个设计模式、一个模仿等等,这些内容都可以以 Issue 的好好管理着。
在最开始我们下定目标的几天里,我们可以很容易做到这样的事。同样的,我们也可以很容易达到 21 天。只是,我们很容易在 21 天后失去一些目标。所以在练习开始之前,你需要创建一个帮助你提高技术的列表,然后一点点加以提高。比如说:
1. 尝试使用 React + Redux + Koa 2、或者Angular 2 + TypeScript,这样我们就能凭此来学习新的技术。
2. 尝试使用 CQRS 架构来设计 CMS,这样我们就可以练习在架构方面的能力。
在我们想到一点我们可以练习的技术的时候,这就是一个可以变成 Issue 管理的内容,我们就可以针对性的提高。
通常在这种情况下,我们知道自己不知道什么东西,当我们处于不知道自己不知道、不知道自己知道时,那我们就需要网上的各种技能图谱——如StuQ的技能图谱。

然后了解图谱上的一个个的内容,尽可能依照此构建自己的体系——以让自己走向知道自己不知道的地步,然后我们才依此来展开练习。
建议试试我们家的Growth哈,地址:http://growth.ren。
文章的剩下部分就让我分享一下:在这 723 天里,我创造出了哪些有意思的东西(PS:让我装逼一下)——其实我不仅仅只是 Markdown 写得好
#### 2014 年
时间:2014.10.08-2014.12.30

在这一段时间里,我创建的项目大部分都是一些物联网项目:
- [iot-coap](https://github.com/phodal/iot-coap) 一个基于 CoAP 协议的物联网
- [designiot](https://github.com/phodal/designiot) 即电子书《教你设计物联网系统》
- [iot-document](https://github.com/phodal/awesome-iot-document) 收集一些物联网相关的资料,和 Awesome 不是一个性质
- [iot](https://github.com/phodal/iot) 基于 PHP 框架 Laravel 的物联网
- iot-android 一个与 iot 项目相配套的 Android 程序
- 等等
正是这几个 IoT 项目,让 Packt 出版社找到了我,才有了后来和国内外出版社打交道的故事。也开始了技术审阅、翻译、写书的各种故事,想想就觉得这个开头真的很好。
期间还创建了一个很有意思的 Chrome 插件,叫 onebuttonapp——没错,就是模仿 Amazon 的一键下单写的。这个插件的目的就是难证当时在项目上用的 Backbone、Require.js 的这一套可以在插件上好好玩。
OnMap 项目是为了让我用 Nokia Lumia 920 拍照的照片,可以在地图上显示而创建的项目。
当然还有其他的一些小项目啦。
#### 2015年

整个区间就是刷各种前端的技术栈,创建了各种有意思的项目:
- [Lettuce框架](https://github.com/phodal/lettuce),一个基于简单的 SPA 框架
- [echoesworks](https://github.com/phodal/echoesworks),一个支持字幕、Markdown、动画的 Slide 框架
- [diaonan](https://github.com/phodal/diaonan),一个支持 CoAP、MQTT、HTTP 的物联网项目
- [developer](https://github.com/phodal/developer),收集各种 Web Developer 成长路线,以及读书图谱
期间还创建了几个混合应用项目:
- [learning-ionic](https://github.com/phodal/learning-ionic),程序语言答人,各种 hello, world 的小应用
- [ionic-elasticsearch](https://github.com/phodal/ionic-elasticsearch), Django ElasticSearch Ionic 打造 GIS 移动应用
- [designiot-app](https://github.com/phodal/designiot-app),教你设计物联网 App 版
更多内容可以见我的 Idea 列表:[https://github.com/phodal/ideas](https://github.com/phodal/ideas),我实在是不想写了。
#### 2016 年

我们有了 Growth 系列的电子书、App,还有 Mole,几个极具代表性的项目就够了。
- [Growth](https://github.com/phodal/growth),一款专注于 Web 开发者成长的应用,涵盖 Web 开发的流程及技术栈,Web 开发的学习路线、成长衡量等各方面。
- [Growth:全栈增长工程师指南](https://github.com/phodal/growth-ebook),一本关于如何成为全栈增长工程师的指南
- [Growth:全栈增长工程师实战](https://github.com/phodal/growth-in-action),在 Growth 中我们介绍的只是一系列的实践,而 Growth 实战则会带领读者去履行这些实践
### See you Again
停止这次连击,只是为了有一个更好的开始。
如果你也想提高自己,不妨从创建你的 ideas 项目开始,如我的 [Ideas](https://github.com/phodal/ideas) 项目一样,上面已经有了大量的 Idea。然后,我们还可以依据这一个个的项目,创建出一本电子书,即 [ideabook](https://github.com/phodal/ideabook)。
GitHub 里程碑
===
写在 GitHub 的第 19999 个 Star 时
---
> Star 虽好,可不要贪杯哦。
> 两年前在做 Annual Review 订下一年的目标时,想着写一个开源框架。去年订下今年的目标时,仍然继续着这样的想法。今年又要制定下一年的目标,2333~~。
不久前,在 GitHub Ranking 上看到自己的 Star 数(Star 不是设计用于做“点赞”的,而是用来收藏的)时,发现已经快 20000 了。然后把自己的项目过了一遍,发现没有一个比较好的**代表性框架**,要么是应用,要么是电子书。
前 8 个项目里,除了 Growth 应用以外,其他的都是电子书内容——六本电子书加起来的 Star 数有 **10619**,果然是骗 Star 的。我只能尽力地去想想:为什么事情会变成这样了?
### 从创建开源框架说起
创建开源框架和创建开源项目是不一样的,前者你服务于开发者,后者你服务于用户。
两年前在做 Annual Review 的时候,想着未来的一年里可以做一个开源框架试试。那时刚毕业不久,对开源世界的各种游戏规则不是很了解:**开源并不是将代码提交上去,然后就会一下子火起来**。虽然我们可以在短期内赚上一些眼球,但是真正要将它采用到项目上的人不多。
当时,我遇到的最主要的问题是:**想参与到项目的人并没有遇到足够的能力**。你还需要花费大量的时间去教他们,鼓励 GitHub 新手并不是一件容易的事。有时我需要在接受他的 PR 后,再修改他的代码。并且人们提交 PR 可能是出于不同的原因。
然后,知道了开源世界还有一个游戏规则是:**谁的影响力大,谁就能产生更广泛的影响**。如 Virtual Dom 并不是 Facebook 首创的,但是却因为 FB 火的; 松本行弘在写下 mruby 的 README 时(印象中是这个项目),Star 数就已经过 1k 了。这种例子数不胜数,要么是在推广上花了力气,要么个人、公司有着更大的影响力。
一年前,稍微改变了下策略:暂时以**培养人为主**,同时想着做一个合适的开源框架——只是在今年看来,前端领域已经没有合适的地方可以造轮子了。
在 GitHub 上有一个很常见的问题是,**大多数项目的维护者就是发起人**——如果这个发起人发生意外了,那么这个项目怎么办。如果这是一个很火的项目,它就存在着巨大的风险;同时这可能也说明了,缺乏一套合理的机制。
你的开源项目不仅仅需要一个使用文档,还需要一个相关设计思想的文档、路线图、未来计划等等。
去年年底写总结的时候,想到可以 RePractise 文章为基础来培养人,于是就有了 Growth 的三个项目:
- 应用:[Growth](https://github.com/phodal/growth)
- 电子书:《[Growth:全栈增长工程师指南](https://github.com/phodal/growth-ebook)》
- 电子书:《[Growth:全栈增长工程师实战](https://github.com/phodal/growth-in-action)》
如今 Growth 已经有了过万的用户,每天活跃的用户数也接近 300 了。第一步看上去很成功,但是下一步怎么走呢?
### 下一个开源项目
后来我开始在思索一个问题,创建一个开源框架是必须的吗?
在编写 Growth 电子书的时候,我发现一个好的软件工程实践远远比一个易上手的框架重要多了。框架本身是易变的东西,过去你在用 Backbone,现在你在用 React.js;过去你在用 Angular.js,现在你在用 Vue。会不会使用某个框架,并不是区分你是不是一个有经验的开发者的标准。
一直将焦点关注于**学习不同的框架的使用**是有问题的,一个在校生可以轻松地比你了解某个框架的原理——你白天在工作,而他整天在学习。这时你很容易就失去竞争力了,你需要从框架之外了解更深层次的东西。**一个好的框架并不能让你写出一段好的代码**。
> 如果中国人的思想不觉悟,即使治好了他们的病,也只是做毫无意义。
这算是我为自己在 GitHub 下的 Markdown 的自辩吧——谁让我一直有写作的冲动呢。
不过我仍然还有一些想法,只是还没有抽出足够的时间去思考这样的事。
**GNU/Linux 的桌面**。这是几年前的一个想法了,当时 GNU/Linux 的那些操作系统上都没有一个好玩的桌面,不过感觉这个坑太深了,就没有进行了。
**家居智能中心**。我仍然对于大学学的知识有点念念不忘,虽然已经写了一本书,但是硬件还是相当的刺激。唯一的问题是:连房子都没有,怎么做智能家居。
**图形框架**。这是我之前在做一个图形界面的时候,发现没有一个合适的框架可以满足我的要求。然后我就在想,还是自己做一个吧。
不过,最好的开源项目就是自己平时用的。于是,我开始将写各种工具来给自己使用——如现在在用的这篇微信编辑工具:[mdpub](https://github.com/phodal/mdpub)。
最后,我做了一个简单的 HTML 5 动画来记录这一时刻,作为这一个里程碑的记念:
[https://phodal.github.io/20k/](https://phodal.github.io/20k/)
# GitHub 寻宝指南
作为一个资深的咨询师、程序员,GitHub 是我用过的最好工具,因为 Google 并非总是那么好用。GitHub 是一个宝藏库,可没有藏宝图,GitHub 一1亿的仓库也和你没有关系。这么一些年下来,也算是掌握了一定的技巧,写篇文章记录一下,也就顺其自然了。
总结一句话便是:GitHub 来搜索 Google 搜索不到的。它们可以 work 的原因,都是因为**我们想做的事情,已经有人已经走过**。如果你走的是一条新的路,那么这篇文章对你来说,意义可能没有那么大。
## 寻找 Demo 节省时间
在工作上使用新的技术,和自己平时的练习,终究差得有些远。工作的时候,我们偏向于目标编程,对于速度和时间的要求,要比自己业余时间要高得多。一旦有了这种压力,便会在 GitHub 上寻找相应的 Demo,了解原理、稍微尝试,再引入到项目中。
这时,便会按**技术栈的关键字搜索,并按更新时间进行排序**,以查找是否有合适的 Demo。
生命有限 ,如若是每次我们尝试一个新的技术,总得自己编写一个个 Demo。编写多个 Demo,都得花去个半天八小时的时间。如此一算,能花费在其它事情上的时间便更少了。若只是试用官方的 Demo,往往是比较容易的。可我们编写应用的时候,总得结合到当前的场合来。这时整合并不是一个轻松的工作,依赖冲突、引入第三方依赖等。
**温馨提醒**:**对于简单的项目来说,自己直接写 Demo 会更加方便。** 尝试项目需要成本,若是需要尝试使用多个项目,那么有可能就浪费时间。
## 寻找脚手架:加快前期开发
无论是后端的微服务架构,还是前端应用,应用的架构正在变得复杂。后端微服务,需要结合一个个的框架,哪怕是 ``Spring Initializr`` 这样的工具,也只能帮助我们搭建项目。我们还需要配合其它工具,一起搭建出一个基本的系统。对于前端应用也是类似的,若是 Angular 这样大而全的框架,时间花费倒也是不多。如 React 这种需要组合的、小而美的框架,使用官方的 ``create-react-app`` 也很难做出我们想要的东西,寻找一个合适的脚手架是一个更好的选择。
这时,我们大抵可以,直接使用技术栈 + ``boilerplate`` 又或者是 ``starter`` 等关键词进行搜索,如 ``react boilerplate``。如果其中找到的组合技术栈,不符合自己的要求,那么再加上相应技术栈的关键字,如 ``react redux boilerplate`` 即可。有意思的是,在这时使用 Google 会比 GitHub 方便一些。
**温馨提醒**:我们需要衡量:**修改脚手架的成本,是否比自己重头写快**。
## 寻找 awesome-xxx:探索可能性
练习新的框架,我总习惯于,**编写一系列相关的 DEMO 项目,然后使用 awesome-xxx 探索可能性。**
Awesome-xxx 系列,是 GitHub 上最容易赚 Star 的类型。但凡是有一定知识度的领域、语言、框架等,都有自己的 awesome-xxx 系列的项目,如 awesome-python, awesome-iot, awesome-react 等等。在这样的项目里,都以一定的知识体系整理出来的,从索引和查阅上相应的方便。如果你想进入一个新的领域,会尝试新的东西就搜索 ``awesome xxx`` 吧。
**温馨提醒**:awesome-xxx 只意味着它们包含尽可能多的资料,并不代表它们拥有所有相关的库。
## **模仿轮子**的轮子
大学时,我在练习写嵌入式操作系统,uC/OS-II 对于初学者的我来说,太复杂了——有太多无关的代码。便在网上找寻相关的实现,也便是找到了一些,在那的基础上一点点完善操作系统。
学习一个成熟的框架,直接阅读现有源码的成本太高,毕竟也不经济。最好的方式,就是去造轮子。从模仿轮子之上,再去造轮子,是最省力气的方式。再配合 《[造轮子与从Github生成轮子](https://www.phodal.com/blog/create-framework-from-github/)》 一文,怕是能写一系列的框架。而造一个相似轮子的想法,往往很多人都有。尤其是一个成熟的框架,往往有很多仿制品。
于是,当你想了解一个框架,造个轮子,不妨试试搜索 ``xxx-like`` 或者 ``xxx-like framework``,中文便是 ``仿 react 框架`` 或者 ``类 react``。如我们在 Google 上搜索 ``react-like`` 就会搜索到 ``inferno``。不过,按 GitHub 的尿性,要搜索到这样的框架,并不是一件容易的事。这时 Google 往往比 GitHub 搜索好用。
所以建议:**平时上班休息时,搜索相关的轮子,回家就可以造轮子了。**
## 学习资源
GitHub 上拥有大量的学习资源,从各类的文章到笔记,还有各式各样的电子书。如:
1. 只需要搜索:``类型 + 笔记``,如 ``操作系统 笔记`` 就能找到一些操作系统相关的笔记。
2. 只需要搜索:``书名`` 就能找到一些和这本书相关的资源,如 ``重构 改善既有代码的设计``。
与此同时,GitHub 上还会搜索到各种 **未经授权**英文书籍的翻译,又或者是各种电子书的 PDF 版。作为多本书的作译者,当然不鼓励 GitHub 上找到一些盗版书。
而在 GitHub 上又有一些库,可以提供相应的学习资源,如 [free-programming-books-zh_CN](https://github.com/justjavac/free-programming-books-zh_CN),即免费的编程中文书籍索引。
建议:**请尊重版权**,哈哈哈。
## 密钥/密码
GitHub 上有太多这样的东西,尽管我没有能赶上个好时候,找到一个合适的密钥。有相关多的资料泄漏和数据库被扒,和 GitHub 上存在的密钥和密码有关。
不过,好在 GitHub 已经在着手解决这个问题:自动删除相关的提交、代码警告等等。
## 私有、商用的 SDK 或代码
总有人,会将一些商用的代码,或者公司内部的代码,提交到 GitHub 上。如果你偶尔看到这样的代码,除了每一时间告诉作者,还可以偷偷 Clone 一下代码——虽然这样做不对,但是我还是想看。
如在 ThoughtWorks 的面试流程里,有一个步骤是代码编程的作业,个人的实现是不能公开出来的。接到一份作业的时候,总会去 GitHub 搜索相应的代码是否被提交了。提交了,倒是也得提醒一下相应的候选人。
过去,我在使用 Phaser 编写应用的时候,对应的粒子系统是收费的。由于我只是尝试这个粒子系统,便没有购买的想法。我一想 GitHub 上可能有,于是搜索了对应的 ``particle-storm.js``,然后就中奖了。就便愉愉快快地去写我的 Hello, World,最后发现它太耗费资源了,便放弃了。
建议:**一旦你在 GitHub 上拿到别人的商用代码,请仅用于学习,并时刻保持低调**。稍有不慎,有牢狱之灾。
## 数据及数据制作工具
当我们需要数据的时候,就会考虑写爬虫。于是 GitHub 上充满了各各样的式爬虫,除此还有得同学把爬虫数据都放在上面了。某次,当我在玩 ElasticSearch 搜索引擎的时候,突然需要一些真实的数据用来测试。便得找爬虫,就在 GitHub 上,找到了大众点评的一些爬虫。
这个关键词,就是:``scrapy dianping.com``,得来不费功夫。
除此,在 AI 相当流行的今天也是如此,也可以搜索到其它同学训练好的模型。
## 结论
试试你的 GitHub 搜索功能吧。
# GitHub 获 Star 指南
> 每天打开 GitHub Trending,都是各种面试指南,这样的生活真难受。如果你的项目是金子,那么请读读这篇文章。
GitHub 是一个非常有意思的地方,也常常变得非常有争议。有证据表明,GitHub 在某种程度上已经成为了简历的一部分。所谓的证据,便是培训班的人在帮助面试者美化 GitHub 页面——从 Vue 高仿各类项目,到淘宝买 Star 来粉饰门面。作为一个面试官,我向来是非常讨厌这样的行为。那么作为一个正直的开发人员,他/她们也越来越需要通过 GitHub 去证明自己的能力。否则,总有一天**劣币驱逐良币**,导致 GitHub Trending 上的项目越来越不堪入目。
出于这样的目的,我想为那些有真金白银的小伙伴写一篇攻略。至于其他/她人的看法倒是不重要,帮助那些金子从水底浮出来,才是我们应该做的。要是有太多的过于水的项目,每天打开 GitHub Trending,都是各种面试指南,那生活还叫生活吗?那叫被面试强迫的生活。
## 为什么我们 Star 一个项目
在 GitHub 获得 Star 的重点是,**碰触人们的 G 点**——人们只对和自己有关的事情感兴趣。或是证明自己是对这个感兴趣,或是觉得这个项目不错可以收藏,或者是觉得作者不容易鼓励一下作者。
当然了,我痛恨那些,投机取巧的人——在 GitHub 放置大量非自己创作的电子书、学术资料、课程,以获取 Star。
获得 Star 的核心是:**你有人们想要的东西,你分享了人们想要的内容**。这些内容可以是代码、文档、文章、资料、指南,只要它能帮助到其他/她人,那么它便是有价值的。当然了作为 GitHub 本身来说,那些通过 Git 和版本管理可以控制的内容,才更适合于这个平台上。
所以,当你手上拥有了人们想要的东西时,那么你就可以使用这份指南,来帮助你构建出更成功的项目。
## 我的获 Star 方式
作为一个 GitHub 上的“大 V”,我往往不需要花费太多的精力在项目宣传上。在 GitHub 上创建一个项目,然后 Star 就来了……。有时候会比较“无耻”,等到某个项目做得稳定的时候,再给自己一个 Star ,吸引更多的吃瓜群众。而后,写一系列的文章来介绍自己的项目。唉,做个开源项目不容易啊。
但是这些并不管用,因为有时候,我写的代码是大家丝毫不感兴趣的内容。如我最近写的 Serverless 密码管理器 MoPass:我在公众号上、博客上、知乎上写了文章来宣传这个项目,最后只吸引了一小部分人的注意——<= 25。毕竟,你觉得好的东西,那只是对你来说有用。对于其他/她人来说,这个密码管理器可能远远不如 1Password。
再举个成功的例子,最近我在思考:**新项目的检查清单**,即当我们来到或者开始一个项目的时候,我们需要做哪些事情,对应的还需要考虑什么因素。于是我在 GitHub 上创建了一个名为 New Project Checklist ([https://github.com/phodal/new-project-checklist](https://github.com/phodal/new-project-checklist) ) 的项目。我只是按自己的想法,在 README 上写下了要考虑的中英文因素,还没编写 Web 部分,就已经获得了 100+ 的 Star。与此同时,因为 Web 部分还没完成,所以我还没在我的博客、专栏上进行宣传。
我只是写了一个 README,然后 Star 就来了。但是,一般情况下,我们需要怎么做呢?
## GitHub 流量分析
实际上,当我们在说获得 Star 的时候,我们说的是**为自己的项目做推广**。只是呢,获得 Star 是其中的一个结果产物,也就是说,我们在宣传项目的过程中,获得了关注度。至于推广本身来说,不同的人会有不同的看法。
事实上,GitHub 获取 Star 与我们日常了解的营销差不多,先将用户吸引到我们的 GitHub 页面,再让用户有关注的动力(这一点太难了)。
因此开始之前,我们先看张图就能知道怎么获取流量。如下是《GitHub 漫游指南》最近两周内的流量来源统计(GitHub 通过 Google Analysis 来统计):
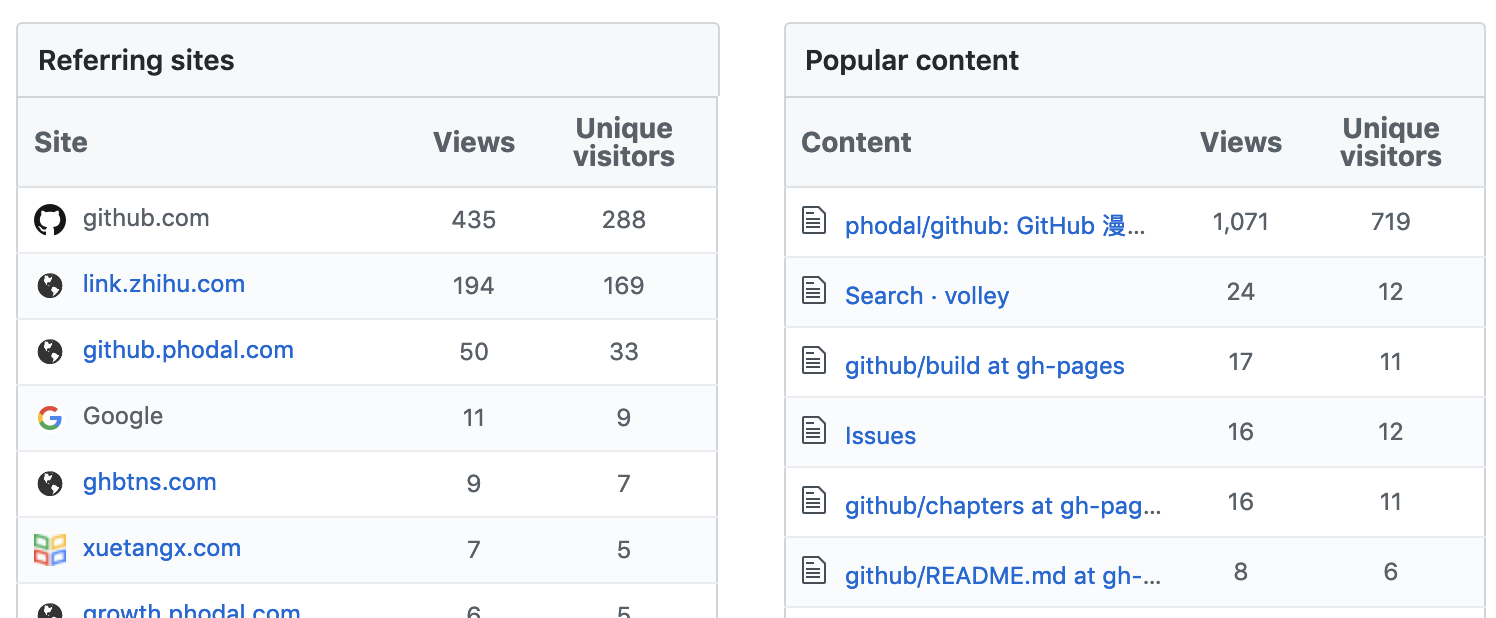
从上图中可以看出,流量主要来源于几部分:
- GitHub 项目的直接访问
- GitHub 的直接访问
- 来源于知乎等社交网站的
- 来自于 GitHub Pages 的访问
- 来自其它社交网站的访问
总的来说,在这一周里,累计有 1,266 次访问,其中有 735 个独立访客。看这数据不错,而实际上 Star 率 就有点低。根据 Star History 网站(https://star-history.t9t.io ) 的统计,在过去的近两个月里,才涨了 38 个 Star。

从我的分析来看,大抵原因有两个:
1. 用户看的都是 GitHub Pages 上的内容
2. 从数量上来看,受众并不多
而我最近在玩的 New Project Checklist([https://github.com/phodal/new-project-checklist](https://github.com/phodal/new-project-checklist) 的转化率看上去,还算可以:
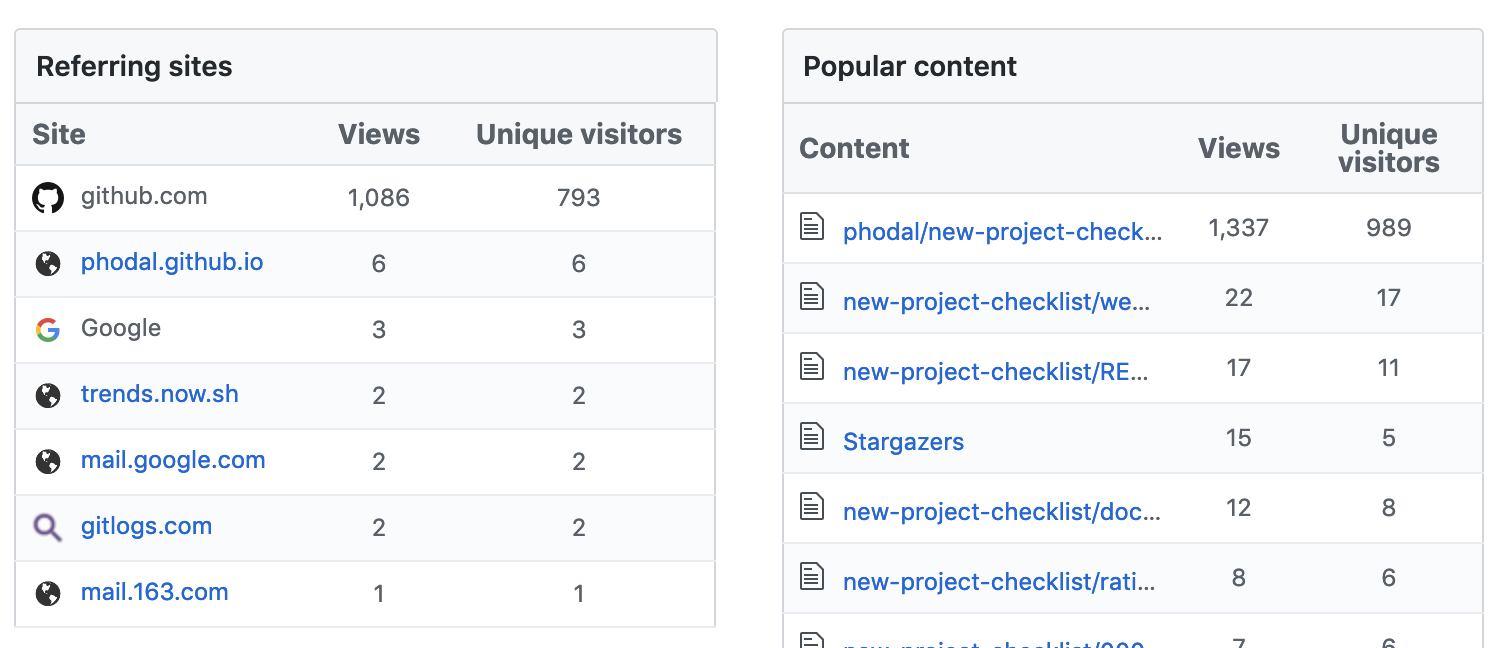
在 999 个独立访客里,获得了 202 个 Star,转化率差不多是 20%——大家真的对这个项目感兴趣。
所以,让我们再强调一下核心的部分:**你分享了人们想要的代码、内容**。否则,你带来了大量的流量,并不一定能转化为你想要的关注度。
## GitHub 获 Star 指南技巧
对于一个创造而言,自然而然的希望自己的项目能有人用。可能一点点的吐槽,都能帮助项目以更好的方式前进。这也就是我为自己项目宣传的意义,在创建项目的时候,我们往往只会按照自己的需要来创建项目。而非其他/她人的需求。因此当有一些新的需求出现时,可能会稍微地影响项目演进的方向。这些方向有好有坏,有时候反而会对自己更有帮助。
好了,回到我们的正题上,怎么去获取 Star?
### 技巧一:结合 SEO 技巧
当我们在为一个项目做宣传的时候,实际上我们做的事情类似于搜索引擎优化(Search Engine Optimization)。稍有不同的是,GitHub 在实践的过程中,帮助我们优化了很多细节。它可以让我们更关注于核心的要素。
实际上,在上一小节里,我们已经介绍了相关的内容。若是想获得来自于 Google 等搜索引擎的访问,那么要掌握的技巧有:

- 简单实用的项目名。项目名在 Google 搜索结果里是放在最前面的部分,它与 URL 同在。
- 写好项目的 ``Description``。不管怎样,你一定要为你的项目写好 Description,让看到的人知道它在做什么。
- 设置好相应的 ``topics``。GitHub 为项目设计了一个 Topics 页面,这些页面会被拉入相应的索引中,可以从 Google 等搜索引擎和 GitHub 中搜索到。
- 作为外链加入文章中。作为 SEO 技巧的一部分,你需要在你的博客和文章里,适当地引用你的 GitHub 项目,它会你的项目带来流量。
- 合适的外链标题。作为链接存在时,需要注意链接的标题(与项目主题一致),它会在某种程度上影响搜索结果。
这些只是一些基本的内容,算不上是技巧,但是做好基础很重要。
### 技巧二:完整、易读的 README
让我们再强调一下,好的 README 真的很重要,重要、重要!重要。
GitHub 是一个人的简历,**而开源项目的 README,就好像是一个项目的简历**。在这份简历里,你需要好好地写你的项目:
- **这个项目做什么?**?
- **它解决了什么问题**?
- **它有什么特性 — hello, world 示例**?
- **怎么使用这个项目**?
- **这个项目使用的是什么协议**,是否允许商用?
以我混迹在 GitHub 近 10 年的经验来看,老外**最喜欢吹这个项目有什么特性了**。与此同时,还会在这个项目上“画大饼”(Roadmap),即**这个项目未来将有什么功能**——为了实现这些功能,我们还需要你的关心、支持与厚爱。所以,如果你是在做一个惊天动地的项目,比如说你要实现一个自动化安装脚本,你可以在未来的功能里写上:
- AI 自动化安装(TODO)
这确实是个 TODO——即不吹,又吸引吃瓜群众。
### 技巧三:社交分享
作为一个混迹在各个社区的资深技术咨询师,分享相关的项目是我的一个常规操作。特别是,当看到一些人“无聊的聊天”,就会推荐上自己的新项目。当然,一般一个项目只会有一两次,频繁的分享便相当于 ** ,你懂的。
**更新状态**。当我在写一个大家感兴趣的开源项目时, 我会在我的社交账号上,如微博、知乎想法,定期的更新相关的状态。诸如:

万一有人感兴趣,就会随之而来——主要是我也不知道微博要怎么玩。
**推荐自己的项目**。作为一个在 GitHub 上有大量项目的开源作者,以及拥有大量文章的我。每次在微信群里,看到一些相关的问题,都会直接丢出我的开源项目。既装逼,又靠谱。
至于微信群的分享频率,要适度~,适量~。
### 技巧四:文章
既然我写了一个这么好的开源项目,那么最好的方式,还是写一篇文章介绍一下这个项目吧。blabla,写完了一篇项目的使用文档:
- **为什么需要这个项目?**
- **这个项目是什么?**
- **这个项目能解决什么问题?**
- **这个项目要怎么用啊?**
是不是写起来很简单?
未来在其它的文章中,有一些相关的话题,便可以稍微提及一些相关的项目。比如,在这篇文章里,我还介绍了好几个近期的项目。这些文章,除了在我的公众号上,还会发在我的博客(累计 100 万访问量)上,我的知乎专栏上,还有我的……上。它们结合起来,会形成一股强大的力量,即能吸引用户,又能在 SEO 上有一定的提升。
### 技巧五:把握 GitHub Trending
万一,我是说万一,你的项目上了 GitHub Trending。截个图,然后你可以再写一篇文章( 我的项目是如何上 GitHub Trending,毕竟上 Trending 很简单),发一条微博,写一个想法,录个小视频,大家快来看这是我的项目。
理论上上 GitHub Trending 会吸引来更多的用户——有大量的网站、自动化微博等,会每天去介绍这些新的上的 Trending 项目,没有意外的话,它会为你带来更多的流量——意味着更多的关注度。
### 不是技巧的技巧:持续性
事实上,如你所知,我在 GitHub 上获得大量 Star 的原因,并不是说我有一个优秀的项目。而在于我在持续的更新,持续不断地在 GitHub 上做自己喜欢的项目,投入时间分享相关的技巧,还有一系列相关的开源项目。
我们一直在持续变好,打造一个自由的互联网世界,打造一个个自己喜欢的工具。
我们是极客,我们热爱编程,我们热爱分享。
# GitHub 上有趣的故事
1. [Remove my password from lists so hackers won't be able to hack me](https://github.com/danielmiessler/SecLists/pull/155)
FAQ
===
## 如何看待 GitHub 项目刷 Star 行为?
我觉得:在作者开源了源码的情况下,求 Star 并没有任何问题。
开源软件的源头是自由软件,而 RMS 创建自由软件的目的是,反对专利软件,即私有化的软件。如果一个开源项目,要你 Star 了,才公开源码,这才叫违反。
开源一个软件,并不意味着:你不能用这个开源软件追求任何利益。在所谓的开源运动里,一个开源软件是可以用来卖钱的。可在国内,这是很难的,大公司 如腾讯,可以轻轻松松地用你的软件,而不遵循 GPL 协议。
在这种时候,也没有法律来保护这些开源软件作者。你只能从道德上谴责他们,然后指望他们的领导来做出一些什么事。如之前的《[知名公司(努比亚/中兴)拿我的开源软件( XXL-JOB)申请国家知识专利,我该怎么办?](https://link.zhihu.com/?target=https%3A//www.v2ex.com/t/367424%3Fp%3D1)》事件。
并且对于大部分的开源软件作者来说,都不大可能像 OpenResty、Vue、emqtt 等软件的作者一样,可以从开源软件获得收益来支撑他们开发。还有一些少数人,还能从开源软件中获得一些利益,提高他们今年的 KPI。然后明年的工资,又会多涨一点点。
可多数人,并没有这样的可能性。我在 GitHub 上有接近 30k 的 Star(笑,有接近 20k 是属于电子书的,毕竟思想改变世界),它一点儿也不影响我涨工资。反而多了一个 GitHub “网红” 的称号,要知道在技术领域,“网红” 并不是一个好词。我观察过的大量开源爱好者,怕是比我还惨一些。明明做了很好的工作,因为宣传工作没有做好,连几个 Star 都没有,后来就弃坑了。
在这个时候,求 Star 就是让心里好受一些,『我做了这么多的事情,我希望得到一些认同』。如果我在一个微信群里,看了作者做了大量的提交,花费了一些心思。在这个时候,我是会去为作者点 Star 的。因为我的 GitHub 上粉丝比较多,所以往往会多带来几个 Star。
如果一个人在开源世界里,做了很多事情,连一个 Star 都没有。那么,他/她可能就会离开开源世界。当这种事情发生多了,那么开源世界的人就变少了。任何做开源工作的人,都是值得鼓励的——不论他们是出于什么目的。