+def get_vector(user, pipe=None):
+
+ r = redis.StrictRedis(host='localhost', port=6379, db=0)
+ no_pipe = False
+ if pipe is None:
+ pipe = pipe = r.pipeline()
+ no_pipe = True
+
+ user = user.lower()
+ pipe.zscore(get_format("user"), user)
+ pipe.hgetall(get_format("user:{0}:day".format(user)))
+ pipe.zrevrange(get_format("user:{0}:event".format(user)), 0, -1,
+ withscores=True)
+ pipe.zcard(get_format("user:{0}:contribution".format(user)))
+ pipe.zcard(get_format("user:{0}:connection".format(user)))
+ pipe.zcard(get_format("user:{0}:repo".format(user)))
+ pipe.zcard(get_format("user:{0}:lang".format(user)))
+ pipe.zrevrange(get_format("user:{0}:lang".format(user)), 0, -1,
+ withscores=True)
+
+ if no_pipe:
+ return pipe.execute()
+-
Github Roam
+Github 漫游指南
By Phodal Huang(Geek's Life)
-前言
+我的Github主页上写着加入的时间——Joined on Nov 8, 2010,那时才大一,在那之后的那长日子里我都没有过到。也许是因为我学的不是计算机,到了今天——2015.3.9,我也发现这其实是程序员的社交网站。
过去,曾经有很长的一些时间我试过在Github上连击,也试着去了解别人是如何用好这个工具的。当然粉丝在Github上也是很重要的。
+在这里,我会试着将我在Github上学到的东西一一分享出来。
+为什么你应该深入Github
+在我大四找工作的时候,试图去寻找一份硬件、物联网相关的工作(ps: 专业是电子信息工程)。尽管简历上写得满满的各种经历、经验,然而并没有卵用。跑了几场校园招聘会后,十份简历(ps: 事先已经有心里准备)一个也没有投出去——因为学校直接被拒。我对霸面什么的一点兴趣都没有,千里马需要伯乐。后来,我加入了Martin Flower所在的公司,当然这是后话了。
+这是一个残酷的世界,在学生时代,如果你长得不帅不高的话,那么多数的附加技能都是白搭(ps: 通常富的是看不到这篇文章的)。在工作时期,如果你上家没有名气,那么将会影响你下一份工作的待遇。而,很多东西却会改变这些,Github就是其中一个。
+我与Github的故事
+注册Github的时候大概是大二的时候,我熟悉的时候已经是大四了,现在已经毕业一年了。在过去的近两年里,我试着以几个维度在Github上创建项目:
+-
+
- 快速上手框架来实战,即demo +
- 重构别人的代码 +
- 创建自己可用的框架 +
- 快速构建大型应用 +
- 构建通用的框架 +
Github与收获
+先说说与技能无关的收获吧,毕业设计做的是一个《最小物联网系统》,考虑到我们专业老师没有这方面知识,答辩时会带来问题,尽量往这方面靠拢。当我毕业后,这个项目已经有过百个star了,这样易上手的东西还是比较受欢迎的(ps: 不过这种硬件相关的项目通常受限于Github上硬件开发工程师比较少的困扰)。
+毕业后一个月收到PACKT出版社的邮件(ps: 他们是在github上找到我的),内容是关于Review一本物联网书籍,即在《从Review到翻译IT书籍》中提到的《Learning Internet of Things》。作为一个四级没过的“物联网专家”,去审阅一本英文的物联网书籍。。。当然,后来是审阅完了,书上有我的英文简介。
+一个月前,收到MANNING出版社的邮件(ps: 也是在github上),关于Review一本物联网书籍的目录,并提出建议。
+也因此带来了其他更多的东西,当然不是这里的主题。在这里,我们就不讨论各种骚扰邮件,或者中文合作。从没有想象过,我也可以在英语世界有一片小天地。
+这些告诉我们,Github上找一个你擅长的主题,那么会有很多人找上你的。
+Github与成长
+过去写过一篇《如何通过github提升自己》的文章,现在只想说三点:
+-
+
- 测试 +
- 更多的测试 +
- 更多的、更多的、更多的测试 +
没有测试的项目是很扯淡的,除非你的项目只有一个函数,然后那个函数返回Hello,World。
如果你的项目代码有上千行,如果你能保证测试覆盖率可以达到95%以的话,那么我想你的项目不会有太复杂的函数。假使有这样的函数,那么他也是被测试覆盖住的。
+如果你在用心做这个项目,那么你看到代码写得不好也会试着改进,即重构。当有了一些,你的技能会不断提升。你开始会试着接触更多的东西,如stub,如mock,如fakeserver。
+有一天,你会发现你离不开测试。
+然后就会相信: 那些没有写测试的项目都是在耍流氓
+为什么你应该深入Github
+上面我们说的都是我们可以收获到的东西,我们开始尝试就意味着我们知道它可能给我们带来好处。上面已经提到很多可以提升自己的例子了,这里再说说其他的。
+方便工作
+我们可以从中获取到不同的知识、内容、信息。每个人都可以从别人的代码中学习,当我们需要构建一个库的时候我们可以在上面寻找不同的库和代码来实现我们的功能。如当我在实现一个库的时候,我会在Github上到相应的组件:
+-
+
- Promise 支持 +
- Class类(ps:没有一个好的类使用的方式) +
- Template 一个简单的模板引擎 +
- Router 用来控制页面的路由 +
- Ajax 基本的Ajax Get/Post请求 +
获得一份工作
+越来越多的人因为Github获得工作,因为他们的做的东西正好符合一些公司的要求。那么,这些公司在寻找代码的时候,就会试着邀请他们。
+因而,在Github寻找合适的候选人,已经是一种趋势。
+扩大人脉
+如果我们想创造出更好、强大地框架时,那么认识更多的人可能会带来更多的帮助。有时候会同上面那一点一样的效果。
+介绍
+什么是Github
+Wiki百科上是这么说的
+++GitHub 是一个共享虚拟主机服务,用于存放使用Git版本控制的软件代码和内容项目。它由GitHub公司(曾称Logical Awesome)的开发者Chris Wanstrath、PJ Hyett和Tom Preston-Werner 使用Ruby on Rails编写而成。
+
当然让我们看看官方的介绍:
+++GitHub is the best place to share code with friends, co-workers, classmates, and complete strangers. Over eight million people use GitHub to build amazing things together.
+
它还是什么?
+-
+
- 网站 +
- 免费博客 +
- 管理配置文件 +
- 收集资料 +
- 简历 +
- 管理代码片段 +
- 托管编程环境 +
- 写作 +
等等。看上去像是大餐,但是你还需要了解点什么?
+版本管理与软件部署
+jQuery1在发布版本2.1.3,一共有152个commit。我们可以看到如下的提交信息:
-
+
- Ajax: Always use script injection in globalEval … bbdfbb4 +
- Effects: Reintroduce use of requestAnimationFrame … 72119e0 +
- Effects: Improve raf logic … 708764f +
- Build: Move test to appropriate module fbdbb6f +
- Build: Update commitplease dev dependency +
- … +
Github与Git
+++Git是一个分布式的版本控制系统,最初由Linus Torvalds编写,用作Linux内核代码的管理。在推出后,Git在其它项目中也取得了很大成功,尤其是在Ruby社区中。目前,包括Rubinius、Merb和Bitcoin在内的很多知名项目都使用了Git。Git同样可以被诸如Capistrano和Vlad the Deployer这样的部署工具所使用。
+
++GitHub可以托管各种git库,并提供一个web界面,但与其它像 SourceForge或Google Code这样的服务不同,GitHub的独特卖点在于从另外一个项目进行分支的简易性。为一个项目贡献代码非常简单:首先点击项目站点的“fork”的按钮,然后将代码检出并将修改加入到刚才分出的代码库中,最后通过内建的“pull request”机制向项目负责人申请代码合并。已经有人将GitHub称为代码玩家的MySpace。
+
提高
+敏捷软件开发
+显然我是在扯淡,这和敏捷软件开发没有什么关系。不过我也不知道瀑布流是怎样的。说说我所知道的一个项目的组成吧:
+-
+
- 看板式管理应用程序(如trello,简单地说就是管理软件功能) +
- CI(持续集成) +
- 测试覆盖率 +
- 代码质量(code smell) +
对于一个不是远程的团队(如只有一个人的项目) 来说,Trello、Jenkin、Jira不是必需的:
+++你存在,我深深的脑海里
+
当只有一个人的时候,你只需要明确知道自己想要什么就够了。我们还需要的是CI、测试,以来提升代码的质量。
+测试
+通常我们都会找Document,如果没有的话,你会找什么?看源代码,还是看测试?
+it("specifying response when you need it", function (done) {
+ var doneFn = jasmine.createSpy("success");
+ lettuce.get('/some/cool/url', function (result) {
+ expect(result).toEqual("awesome response");
+ done();
+ });
+
+ expect(jasmine.Ajax.requests.mostRecent().url).toBe('/some/cool/url');
+ expect(doneFn).not.toHaveBeenCalled();
+
+ jasmine.Ajax.requests.mostRecent().respondWith({
+ "status": 200,
+ "contentType": 'text/plain',
+ "responseText": 'awesome response'
+ });
+});代码来源: https://github.com/phodal/lettuce
+上面的测试用例,清清楚楚地写明了用法,虽然写得有点扯。
+等等,测试是用来干什么的。那么,先说说我为什么会想去写测试吧:
+-
+
- 我不希望每次做完一个个新功能的时候,再手动地去测试一个个功能。(自动化测试) +
- 我不希望在重构的时候发现破坏了原来的功能,而我还一无所知。 +
- 我不敢push代码,因为我没有把握。 +
虽然,我不是TDD的死忠,测试的目的是保证功能正常,TDD没法让我们写出质量更高的代码。但是有时TDD是不错的,可以让我们写出逻辑更简单地代码。
+也许你已经知道了Selenium、Jasmine、Cucumber等等的框架,看到过类似于下面的测试
Ajax
+ ✓ specifying response when you need it
+ ✓ specifying html when you need it
+ ✓ should be post to some where
+ Class
+ ✓ respects instanceof
+ ✓ inherits methods (also super)
+ ✓ extend methods
+ Effect
+ ✓ should be able fadein elements
+ ✓ should be able fadeout elements代码来源: https://github.com/phodal/lettuce
+看上去似乎每个测试都很小,不过补完每一个测试之后我们就得到了测试覆盖率
+| File | +Statements | +Branches | +Functions | +Lines | +
|---|---|---|---|---|
| lettuce.js | +98.58% (209 / 212) | +82.98%(78 / 94) | +100.00% (54 / 54) | +98.58% (209 / 212) | +
本地测试都通过了,于是我们添加了Travis-CI来跑我们的测试
CI
+虽然node.js不算是一门语言,但是因为我们用的node,下面的是一个简单的.travis.yml示例:
language: node_js
+node_js:
+ - "0.10"
+
+notifications:
+ email: false
+
+before_install: npm install -g grunt-cli
+install: npm install
+after_success: CODECLIMATE_REPO_TOKEN=321480822fc37deb0de70a11931b4cb6a2a3cc411680e8f4569936ac8ffbb0ab codeclimate < coverage/lcov.info代码来源: https://github.com/phodal/lettuce
+我们把这些集成到README.md之后,就有了之前那张图。
CI对于一个开发者在不同城市开发同一项目上来说是很重要的,这意味着当你添加的部分功能有测试覆盖的时候,项目代码会更加强壮。
+代码质量
+像jslint这类的工具,只能保证代码在语法上是正确的,但是不能保证你写了一堆bad smell的代码。
-
+
- 重复代码 +
- 过长的函数 +
- 等等 +
Code Climate是一个与github集成的工具,我们不仅仅可以看到测试覆盖率,还有代码质量。
先看看上面的ajax类:
+Lettuce.get = function (url, callback) {
+ Lettuce.send(url, 'GET', callback);
+};
+
+Lettuce.send = function (url, method, callback, data) {
+ data = data || null;
+ var request = new XMLHttpRequest();
+ if (callback instanceof Function) {
+ request.onreadystatechange = function () {
+ if (request.readyState === 4 && (request.status === 200 || request.status === 0)) {
+ callback(request.responseText);
+ }
+ };
+ }
+ request.open(method, url, true);
+ if (data instanceof Object) {
+ data = JSON.stringify(data);
+ request.setRequestHeader('Content-Type', 'application/json');
+ }
+ request.setRequestHeader('X-Requested-With', 'XMLHttpRequest');
+ request.send(data);
+};代码来源: https://github.com/phodal/lettuce
+在Code Climate在出现了一堆问题
+-
+
- Missing “use strict” statement. (Line 2) +
- Missing “use strict” statement. (Line 14) +
- ‘Lettuce’ is not defined. (Line 5) +
而这些都是小问题啦,有时可能会有
+-
+
- Similar code found in two :expression_statement nodes (mass = 86) +
这就意味着我们可以对上面的代码进行重构,他们是重复的代码。
+重构
+不想在这里说太多关于重构的东西,可以参考Martin Flower的《重构》一书去多了解一些重构的细节。
这时想说的是,只有代码被测试覆盖住了,那么才能保证重构的过程没有出错。
+基本知识
+Git
+从一般开发者的角度来看,git有以下功能:
+-
+
- 从服务器上克隆数据库(包括代码和版本信息)到单机上。 +
- 在自己的机器上创建分支,修改代码。 +
- 在单机上自己创建的分支上提交代码。 +
- 在单机上合并分支。 +
- 新建一个分支,把服务器上最新版的代码fetch下来,然后跟自己的主分支合并。 +
- 生成补丁(patch),把补丁发送给主开发者。 +
- 看主开发者的反馈,如果主开发者发现两个一般开发者之间有冲突(他们之间可以合作解决的冲突),就会要求他们先解决冲突,然后再由其中一个人提交。如果主开发者可以自己解决,或者没有冲突,就通过。 +
- 一般开发者之间解决冲突的方法,开发者之间可以使用pull 命令解决冲突,解决完冲突之后再向主开发者提交补丁。 +
从主开发者的角度(假设主开发者不用开发代码)看,git有以下功能:
+-
+
- 查看邮件或者通过其它方式查看一般开发者的提交状态。 +
- 打上补丁,解决冲突(可以自己解决,也可以要求开发者之间解决以后再重新提交,如果是开源项目,还要决定哪些补丁有用,哪些不用)。 +
- 向公共服务器提交结果,然后通知所有开发人员。 +
Git初入
+如果是第一次使用Git,你需要设置署名和邮箱:
+$ git config --global user.name "用户名"
+$ git config --global user.email "电子邮箱"将代码仓库clone到本地,其实就是将代码复制到你的机器里,并交由Git来管理:
+$ git clone git@github.com:someone/symfony-docs-chs.git你可以修改复制到本地的代码了(symfony-docs-chs项目里都是rst格式的文档)。当你觉得完成了一定的工作量,想做个阶段性的提交:
+向这个本地的代码仓库添加当前目录的所有改动:
+$ git add .或者只是添加某个文件:
+Github
+

多种方式
+++…or create a new repository on the command line
+
echo "# github-roam" >> README.md
+git init
+git add README.md
+git commit -m "first commit"
+git remote add origin git@github.com:phodal/github-roam.git
+git push -u origin master++…or push an existing repository from the command line
+
git remote add origin git@github.com:phodal/github-roam.git
+git push -u origin master
+ Github项目分析一
+用matplotlib生成图表
+如何分析用户的数据是一个有趣的问题,特别是当我们有大量的数据的时候。 除了matlab,我们还可以用numpy+matplotlib
python github用户数据分析
+数据可以在这边寻找到
+ +最后效果图 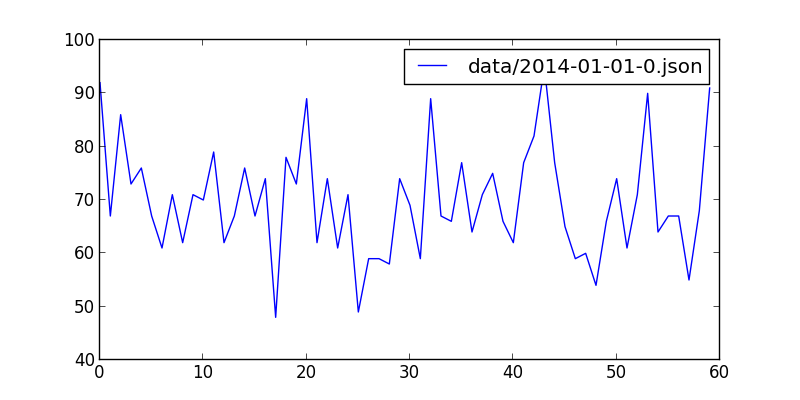
要解析的json文件位于data/2014-01-01-0.json,大小6.6M,显然我们可能需要用每次只读一行的策略,这足以解释为什么诸如sublime打开的时候很慢,而现在我们只需要里面的json数据中的创建时间。。
== 这个文件代表什么?
+2014年1月1日零时到一时,用户在github上的操作,这里的用户指的是很多。。一共有4814条数据,从commit、create到issues都有。
+python json文件解析
+ import json
+ for line in open(jsonfile):
+ line = f.readline()
+import dateutil.parser
+
+lin = json.loads(line)
+date = dateutil.parser.parse(lin["created_at"])
+这里用到了dateutil,因为新鲜出炉的数据是string需要转换为dateutil,再到数据放到数组里头。最后有就有了parse_data
def parse_data(jsonfile): f = open(jsonfile, “r”) dataarray = [] datacount = 0
+for line in open(jsonfile):
+ line = f.readline()
+ lin = json.loads(line)
+ date = dateutil.parser.parse(lin["created_at"])
+ datacount += 1
+ dataarray.append(date.minute)
+
+minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]
+f.close()
+return minuteswithcount下面这句代码就是将上面的解析为
+ minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]这样的数组以便于解析
+ [(0, 92), (1, 67), (2, 86), (3, 73), (4, 76), (5, 67), (6, 61), (7, 71), (8, 62), (9, 71), (10, 70), (11, 79), (12, 62), (13, 67), (14, 76), (15, 67), (16, 74), (17, 48), (18, 78), (19, 73), (20, 89), (21, 62), (22, 74), (23, 61), (24, 71), (25, 49), (26, 59), (27, 59), (28, 58), (29, 74), (30, 69), (31, 59), (32, 89), (33, 67), (34, 66), (35, 77), (36, 64), (37, 71), (38, 75), (39, 66), (40, 62), (41, 77), (42, 82), (43, 95), (44, 77), (45, 65), (46, 59), (47, 60), (48, 54), (49, 66), (50, 74), (51, 61), (52, 71), (53, 90), (54, 64), (55, 67), (56, 67), (57, 55), (58, 68), (59, 91)]matplotlib
+开始之前需要安装``matplotlib
+ sudo pip install matplotlib然后引入这个库
+ import matplotlib.pyplot as plt如上面的那个结果,只需要
+
+ plt.figure(figsize=(8,4))
+ plt.plot(x, y,label = files)
+ plt.legend()
+ plt.show()
+最后代码可见
+#!/usr/bin/env python
+# -*- coding: utf-8 -*-
+
+import json
+import dateutil.parser
+import numpy as np
+import matplotlib.mlab as mlab
+import matplotlib.pyplot as plt
+
+
+def parse_data(jsonfile):
+ f = open(jsonfile, "r")
+ dataarray = []
+ datacount = 0
+
+ for line in open(jsonfile):
+ line = f.readline()
+ lin = json.loads(line)
+ date = dateutil.parser.parse(lin["created_at"])
+ datacount += 1
+ dataarray.append(date.minute)
+
+ minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]
+ f.close()
+ return minuteswithcount
+
+
+def draw_date(files):
+ x = []
+ y = []
+ mwcs = parse_data(files)
+ for mwc in mwcs:
+ x.append(mwc[0])
+ y.append(mwc[1])
+
+ plt.figure(figsize=(8,4))
+ plt.plot(x, y,label = files)
+ plt.legend()
+ plt.show()
+
+draw_date("data/2014-01-01-0.json")每周分析
+继上篇之后,我们就可以分析用户的每周提交情况,以得出用户的真正的工具效率,每个程序员的工作时间可能是不一样的,如 
这是我的每周情况,显然如果把星期六移到前面的话,随着工作时间的增长,在github上的使用在下降,作为一个
+ a fulltime hacker who works best in the evening (around 8 pm).不过这个是osrc的分析结果。
+python github 每周情况分析
+看一张分析后的结果
+
结果正好与我的情况相反?似乎图上是这么说的,但是数据上是这样的情况。
+data
+├── 2014-01-01-0.json
+├── 2014-02-01-0.json
+├── 2014-02-02-0.json
+├── 2014-02-03-0.json
+├── 2014-02-04-0.json
+├── 2014-02-05-0.json
+├── 2014-02-06-0.json
+├── 2014-02-07-0.json
+├── 2014-02-08-0.json
+├── 2014-02-09-0.json
+├── 2014-02-10-0.json
+├── 2014-02-11-0.json
+├── 2014-02-12-0.json
+├── 2014-02-13-0.json
+├── 2014-02-14-0.json
+├── 2014-02-15-0.json
+├── 2014-02-16-0.json
+├── 2014-02-17-0.json
+├── 2014-02-18-0.json
+├── 2014-02-19-0.json
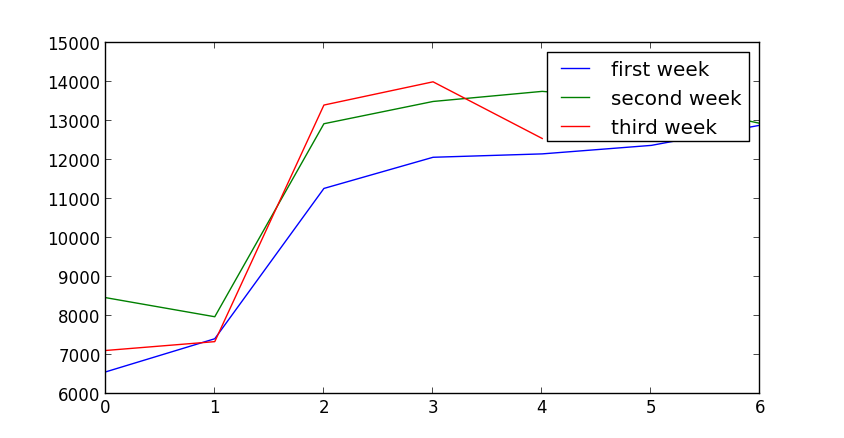
+└── 2014-02-20-0.json我们获取是每天晚上0点时的情况,至于为什么是0点,我想这里的数据量可能会比较少。除去1月1号的情况,就是上面的结果,在只有一周的情况时,总会以为因为在国内那时是假期,但是总觉得不是很靠谱,国内的程序员虽然很多,会在github上活跃的可能没有那么多,直至列出每一周的数据时。
+ 6570, 7420, 11274, 12073, 12160, 12378, 12897,
+ 8474, 7984, 12933, 13504, 13763, 13544, 12940,
+ 7119, 7346, 13412, 14008, 12555python 数据分析
+重写了一个新的方法用于计算提交数,直至后面才意识到其实我们可以算行数就够了,但是方法上有点hack
+
+ def get_minutes_counts_with_id(jsonfile):
+ datacount, dataarray = handle_json(jsonfile)
+ minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]
+ return minuteswithcount
+
+
+ def handle_json(jsonfile):
+ f = open(jsonfile, "r")
+ dataarray = []
+ datacount = 0
+
+ for line in open(jsonfile):
+ line = f.readline()
+ lin = json.loads(line)
+ date = dateutil.parser.parse(lin["created_at"])
+ datacount += 1
+ dataarray.append(date.minute)
+
+ f.close()
+ return datacount, dataarray
+
+
+ def get_minutes_count_num(jsonfile):
+ datacount, dataarray = handle_json(jsonfile)
+ return datacount
+
+
+ def get_month_total():
+ """
+
+ :rtype : object
+ """
+ monthdaycount = []
+ for i in range(1, 20):
+ if i < 10:
+ filename = 'data/2014-02-0' + i.__str__() + '-0.json'
+ else:
+ filename = 'data/2014-02-' + i.__str__() + '-0.json'
+ monthdaycount.append(get_minutes_count_num(filename))
+ return monthdaycount
+接着我们需要去遍历每个结果,后面的后面会发现这个效率真的是太低了,为什么木有多线程?
+python matplotlib图表
+让我们的matplotlib来做这些图表的工作
+if __name__ == '__main__':
+ results = pd.get_month_total()
+ print results
+
+ plt.figure(figsize=(8, 4))
+ plt.plot(results.__getslice__(0, 7), label="first week")
+ plt.plot(results.__getslice__(7, 14), label="second week")
+ plt.plot(results.__getslice__(14, 21), label="third week")
+ plt.legend()
+ plt.show()蓝色的是第一周,绿色的是第二周,蓝色的是第三周就有了上面的结果。
+我们还需要优化方法,以及多线程的支持。
+Github项目分析二
+让我们分析之前的程序,然后再想办法做出优化。网上看到一篇文章http://www.huyng.com/posts/python-performance-analysis/讲的就是分析这部分内容的。
+time python分析
+分析程序的运行时间
+$time python handle.py结果便是,但是对于我们的分析没有一点意义
+ real 0m43.411s
+ user 0m39.226s
+ sys 0m0.618sline_profiler python
+这是 ##Mac OS X 10.9 line_profiler Install##
+ sudo ARCHFLAGS="-Wno-error=unused-command-line-argument-hard-error-in-future" easy_install line_profilerparse_data.py的handle_json前面加上@profile
+
+@profile
+def handle_json(jsonfile):
+ f = open(jsonfile, "r")
+ dataarray = []
+ datacount = 0
+
+ for line in open(jsonfile):
+ line = f.readline()
+ lin = json.loads(line)
+ date = dateutil.parser.parse(lin["created_at"])
+ datacount += 1
+ dataarray.append(date.minute)
+
+ f.close()
+ return datacount, dataarray
+ Line_profiler带了一个分析脚本kernprof.py,so
kernprof.py -l -v handle.py我们便会得到下面的结果
+Wrote profile results to handle.py.lprof
+Timer unit: 1e-06 s
+
+File: parse_data.py
+Function: handle_json at line 15
+Total time: 127.332 s
+
+Line # Hits Time Per Hit % Time Line Contents
+==============================================================
+ 15 @profile
+ 16 def handle_json(jsonfile):
+ 17 19 636 33.5 0.0 f = open(jsonfile, "r")
+ 18 19 21 1.1 0.0 dataarray = []
+ 19 19 16 0.8 0.0 datacount = 0
+ 20
+ 21 212373 730344 3.4 0.6 for line in open(jsonfile):
+ 22 212354 2826826 13.3 2.2 line = f.readline()
+ 23 212354 13848171 65.2 10.9 lin = json.loads(line)
+ 24 212354 109427317 515.3 85.9 date = dateutil.parser.parse(lin["created_at"])
+ 25 212354 238112 1.1 0.2 datacount += 1
+ 26 212354 260227 1.2 0.2 dataarray.append(date.minute)
+ 27
+ 28 19 349 18.4 0.0 f.close()
+ 29 19 20 1.1 0.0 return datacount, dataarray于是我们就发现我们的瓶颈就是从读取created_at,即创建时间。。。以及解析json,反而不是我们关心的IO,果然readline很强大。
memory_profiler python
+memory_profiler install
+$ pip install -U memory_profiler
+$ pip install psutilmemory_profiler python
+如上,我们只需要在handle_json前面加上@profile
python -m memory_profiler handle.py于是
+Filename: parse_data.py
+
+Line # Mem usage Increment Line Contents
+================================================
+ 13 39.930 MiB 0.000 MiB @profile
+ 14 def handle_json(jsonfile):
+ 15 39.930 MiB 0.000 MiB f = open(jsonfile, "r")
+ 16 39.930 MiB 0.000 MiB dataarray = []
+ 17 39.930 MiB 0.000 MiB datacount = 0
+ 18
+ 19 40.055 MiB 0.125 MiB for line in open(jsonfile):
+ 20 40.055 MiB 0.000 MiB line = f.readline()
+ 21 40.066 MiB 0.012 MiB lin = json.loads(line)
+ 22 40.055 MiB -0.012 MiB date = dateutil.parser.parse(lin["created_at"])
+ 23 40.055 MiB 0.000 MiB datacount += 1
+ 24 40.055 MiB 0.000 MiB dataarray.append(date.minute)
+ 25
+ 26 f.close()
+ 27 return datacount, dataarrayobjgraph python
+objgraph install
+ pip install objgraph我们需要调用他
+ import pdb;以及在需要调度的地方加上
+ pdb.set_trace()接着会进入command模式
(pdb) import objgraph
+(pdb) objgraph.show_most_common_types()然后我们可以找到。。
+function 8259
+dict 2137
+tuple 1949
+wrapper_descriptor 1625
+list 1586
+weakref 1145
+builtin_function_or_method 1117
+method_descriptor 948
+getset_descriptor 708
+type 705也可以用他生成图形,貌似这里是用dot生成的,加上python-xdot
很明显的我们需要一个数据库。
+如果我们每次都要花同样的时间去做一件事,去扫那些数据的话,那么这是最好的打发时间的方法。
+python SQLite3 查询数据
+我们创建了一个名为userdata.db的数据库文件,然后创建了一个表,里面有owner,language,eventtype,name url
def init_db():
+ conn = sqlite3.connect('userdata.db')
+ c = conn.cursor()
+ c.execute('''CREATE TABLE userinfo (owner text, language text, eventtype text, name text, url text)''')接着我们就可以查询数据,这里从结果讲起。
+
+def get_count(username):
+ count = 0
+ userinfo = []
+ condition = 'select * from userinfo where owener = \'' + str(username) + '\''
+ for zero in c.execute(condition):
+ count += 1
+ userinfo.append(zero)
+
+ return count, userinfo
+
+gmszone的时候,也就是我自己就会有如下的结果
+
+(u'gmszone', u'ForkEvent', u'RESUME', u'TeX', u'https://github.com/gmszone/RESUME')
+(u'gmszone', u'WatchEvent', u'iot-dashboard', u'JavaScript', u'https://github.com/gmszone/iot-dashboard')
+(u'gmszone', u'PushEvent', u'wechat-wordpress', u'Ruby', u'https://github.com/gmszone/wechat-wordpress')
+(u'gmszone', u'WatchEvent', u'iot', u'JavaScript', u'https://github.com/gmszone/iot')
+(u'gmszone', u'CreateEvent', u'iot-doc', u'None', u'https://github.com/gmszone/iot-doc')
+(u'gmszone', u'CreateEvent', u'iot-doc', u'None', u'https://github.com/gmszone/iot-doc')
+(u'gmszone', u'PushEvent', u'iot-doc', u'TeX', u'https://github.com/gmszone/iot-doc')
+(u'gmszone', u'PushEvent', u'iot-doc', u'TeX', u'https://github.com/gmszone/iot-doc')
+(u'gmszone', u'PushEvent', u'iot-doc', u'TeX', u'https://github.com/gmszone/iot-doc')
+109
+一共有109个事件,有Watch,Create,Push,Fork还有其他的, 项目主要有iot,RESUME,iot-dashboard,wechat-wordpress, 接着就是语言了,Tex,Javascript,Ruby,接着就是项目的url了。
+-rw-r--r-- 1 fdhuang staff 905M Apr 12 14:59 userdata.db
+这个数据库文件有905M,不过查询结果相当让人满意,至少相对于原来的结果来说。
+Python SQLite3
+Python自带了对SQLite3的支持,然而我们还需要安装SQLite3
+ brew install sqlite3或者是
+ sudo port install sqlite3或者是Ubuntu的
+ sudo apt-get install sqlite3openSUSE自然就是
+ sudo zypper install sqlite3不过,用yast2也很不错,不是么。。
+Pythont Github Sqlite3数据导入
+需要注意的是这里是需要python2.7,起源于对gzip的上下文管理器的支持问题
+
+def handle_gzip_file(filename):
+ userinfo = []
+ with gzip.GzipFile(filename) as f:
+ events = [line.decode("utf-8", errors="ignore") for line in f]
+
+ for n, line in enumerate(events):
+ try:
+ event = json.loads(line)
+ except:
+
+ continue
+
+ actor = event["actor"]
+ attrs = event.get("actor_attributes", {})
+ if actor is None or attrs.get("type") != "User":
+ continue
+
+ key = actor.lower()
+
+ repo = event.get("repository", {})
+ info = str(repo.get("owner")), str(repo.get("language")), str(event["type"]), str(repo.get("name")), str(
+ repo.get("url"))
+ userinfo.append(info)
+
+ return userinfo
+
+def build_db_with_gzip():
+ init_db()
+ conn = sqlite3.connect('userdata.db')
+ c = conn.cursor()
+
+ year = 2014
+ month = 3
+
+ for day in range(1,31):
+ date_re = re.compile(r"([0-9]{4})-([0-9]{2})-([0-9]{2})-([0-9]+)\.json.gz")
+
+ fn_template = os.path.join("march",
+ "{year}-{month:02d}-{day:02d}-{n}.json.gz")
+ kwargs = {"year": year, "month": month, "day": day, "n": "*"}
+ filenames = glob.glob(fn_template.format(**kwargs))
+
+ for filename in filenames:
+ c.executemany('INSERT INTO userinfo VALUES (?,?,?,?,?)', handle_gzip_file(filename))
+
+ conn.commit()
+ c.close()
+executemany可以插入多条数据,对于我们的数据来说,一小时的文件大概有五六千个会符合我们上面的安装,也就是有actor又有type才是我们需要记录的数据,我们只需要统计用户的那些事件,而非全部的事件。
python 遍历文件
+我们需要去遍历文件,然后找到合适的部分,这里只是要找2014-03-01到2014-03-31的全部事件,而光这些数据的gz文件就有1.26G,同上面那些解压为json文件显得不合适,只能用遍历来处理。
这里参考了osrc项目中的写法,或者说直接复制过来。
+首先是正规匹配
+ date_re = re.compile(r"([0-9]{4})-([0-9]{2})-([0-9]{2})-([0-9]+)\.json.gz")不过主要的还是在于glob.glob
++glob是python自己带的一个文件操作相关模块,用它可以查找符合自己目的的文件,就类似于Windows下的文件搜索,支持通配符操作。
+
这里也就用上了gzip.GzipFile又一个不错的东西。
最后代码可以见
+ +更好的方案?
+redis
+结合了前面两篇我们终于可以成功地读取出用户数据、处理,再接着可以找相近的用户。
+Python Redis
+查询用户事件总数
+ import redis
+ r = redis.StrictRedis(host='localhost', port=6379, db=0)
+ pipe = pipe = r.pipeline()
+ pipe.zscore('osrc:user',"gmszone")
+ pipe.execute()系统返回了227.0,试试别人。
>>> pipe.zscore('osrc:user',"dfm")
+<redis.client.StrictPipeline object at 0x104fa7f50>
+>>> pipe.execute()
+[425.0]
+>>>看看主要是在哪一天提交的
+>>> pipe.hgetall('osrc:user:gmszone:day')
+<redis.client.StrictPipeline object at 0x104fa7f50>
+>>> pipe.execute()
+[{'1': '51', '0': '41', '3': '17', '2': '34', '5': '28', '4': '22', '6': '34'}]结果大致如下图所示:
+看看主要的事件是?
+>>> pipe.zrevrange("osrc:user:gmszone:event".format("gmszone"), 0, -1,withscores=True)
+<redis.client.StrictPipeline object at 0x104fa7f50>
+>>> pipe.execute()
+[[('PushEvent', 154.0), ('CreateEvent', 41.0), ('WatchEvent', 18.0), ('GollumEvent', 8.0), ('MemberEvent', 3.0), ('ForkEvent', 2.0), ('ReleaseEvent', 1.0)]]
+>>>
蓝色的就是push事件,黄色的是create等等。
+到这里我们算是知道了OSRC的数据库部分是如何工作的。
+Python redis 查询
+主要代码如下所示
+
+def get_vector(user, pipe=None):
+
+ r = redis.StrictRedis(host='localhost', port=6379, db=0)
+ no_pipe = False
+ if pipe is None:
+ pipe = pipe = r.pipeline()
+ no_pipe = True
+
+ user = user.lower()
+ pipe.zscore(get_format("user"), user)
+ pipe.hgetall(get_format("user:{0}:day".format(user)))
+ pipe.zrevrange(get_format("user:{0}:event".format(user)), 0, -1,
+ withscores=True)
+ pipe.zcard(get_format("user:{0}:contribution".format(user)))
+ pipe.zcard(get_format("user:{0}:connection".format(user)))
+ pipe.zcard(get_format("user:{0}:repo".format(user)))
+ pipe.zcard(get_format("user:{0}:lang".format(user)))
+ pipe.zrevrange(get_format("user:{0}:lang".format(user)), 0, -1,
+ withscores=True)
+
+ if no_pipe:
+ return pipe.execute()
+结果在上一篇中显示出来了,也就是
+ [227.0, {'1': '51', '0': '41', '3': '17', '2': '34', '5': '28', '4': '22', '6': '34'}, [('PushEvent', 154.0), ('CreateEvent', 41.0), ('WatchEvent', 18.0), ('GollumEvent', 8.0), ('MemberEvent', 3.0), ('ForkEvent', 2.0), ('ReleaseEvent', 1.0)], 0, 0, 0, 11, [('CSS', 74.0), ('JavaScript', 60.0), ('Ruby', 12.0), ('TeX', 6.0), ('Python', 6.0), ('Java', 5.0), ('C++', 5.0), ('Assembly', 5.0), ('C', 3.0), ('Emacs Lisp', 2.0), ('Arduino', 2.0)]]有意思的是在这里生成了和自己相近的人
+ ['alesdokshanin', 'hjiawei', 'andrewreedy', 'christj6', '1995eaton']osrc最有意思的一部分莫过于flann,当然说的也是系统后台的设计的一个很关键及有意思的部分。
+Python Github
+邻近算法是在这个分析过程中一个很有意思的东西。
+++邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法可以说是整个数据挖掘分类技术中最简单的方法了。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用她最接近的k个邻居来代表。
+
换句话说,我们需要一些样本来当作我们的分析资料,这里东西用到的就是我们之前的。
+ [227.0, {'1': '51', '0': '41', '3': '17', '2': '34', '5': '28', '4': '22', '6': '34'}, [('PushEvent', 154.0), ('CreateEvent', 41.0), ('WatchEvent', 18.0), ('GollumEvent', 8.0), ('MemberEvent', 3.0), ('ForkEvent', 2.0), ('ReleaseEvent', 1.0)], 0, 0, 0, 11, [('CSS', 74.0), ('JavaScript', 60.0), ('Ruby', 12.0), ('TeX', 6.0), ('Python', 6.0), ('Java', 5.0), ('C++', 5.0), ('Assembly', 5.0), ('C', 3.0), ('Emacs Lisp', 2.0), ('Arduino', 2.0)]]在代码中是构建了一个points.h5的文件来分析每个用户的points,之后再记录到hdf5文件中。
+[ 0.00438596 0.18061674 0.2246696 0.14977974 0.07488987 0.0969163
+ 0.12334802 0.14977974 0. 0.18061674 0. 0. 0.
+ 0.00881057 0. 0. 0.03524229 0. 0.
+ 0.01321586 0. 0. 0. 0.6784141 0.
+ 0.07929515 0.00440529 1. 1. 1. 0.08333333
+ 0.26431718 0.02202643 0.05286344 0.02643172 0. 0.01321586
+ 0.02202643 0. 0. 0. 0. 0. 0.
+ 0. 0. 0.00881057 0. 0. 0. 0.
+ 0. 0. 0. 0. 0. 0. 0.
+ 0. 0. 0. 0. 0.00881057]这里分析到用户的大部分行为,再找到与其行为相近的用户,主要的行为有下面这些:
+-
+
- 每星期的情况 +
- 事件的类型 +
- 贡献的数量,连接以及语言 +
- 最多的语言 +
osrc中用于解析的代码
+def parse_vector(results):
+ points = np.zeros(nvector)
+ total = int(results[0])
+
+ points[0] = 1.0 / (total + 1)
+
+ # Week means.
+ for k, v in results[1].iteritems():
+ points[1 + int(k)] = float(v) / total
+
+ # Event types.
+ n = 8
+ for k, v in results[2]:
+ points[n + evttypes.index(k)] = float(v) / total
+
+ # Number of contributions, connections and languages.
+ n += nevts
+ points[n] = 1.0 / (float(results[3]) + 1)
+ points[n + 1] = 1.0 / (float(results[4]) + 1)
+ points[n + 2] = 1.0 / (float(results[5]) + 1)
+ points[n + 3] = 1.0 / (float(results[6]) + 1)
+
+ # Top languages.
+ n += 4
+ for k, v in results[7]:
+ if k in langs:
+ points[n + langs.index(k)] = float(v) / total
+ else:
+ # Unknown language.
+ points[-1] = float(v) / total
+
+ return points这样也就返回我们需要的点数,然后我们可以用get_points来获取这些
def get_points(usernames):
+ r = redis.StrictRedis(host='localhost', port=6379, db=0)
+ pipe = r.pipeline()
+
+ results = get_vector(usernames)
+ points = np.zeros([len(usernames), nvector])
+ points = parse_vector(results)
+ return points就会得到我们的相应的数据,接着找找和自己邻近的,看看结果。
+[ 0.01298701 0.19736842 0. 0.30263158 0.21052632 0.19736842
+ 0. 0.09210526 0. 0.22368421 0.01315789 0. 0.
+ 0. 0. 0. 0.01315789 0. 0.
+ 0.01315789 0. 0. 0. 0.73684211 0. 0.
+ 0. 1. 1. 1. 0.2 0.42105263
+ 0.09210526 0. 0. 0. 0. 0.23684211
+ 0. 0. 0.03947368 0. 0. 0. 0.
+ 0. 0. 0. 0. 0. 0. 0.
+ 0. 0. 0. 0. 0. 0. 0.
+ 0. 0. 0. 0. ]真看不出来两者有什么相似的地方 。。。。
+Github项目分析
+之前曾经分析过一些Github的用户行为,现在我们先来说说Github上的Star吧。(截止: 2015年3月9日23时。)
+| 用户 | +项目名 | +Language | +Star | +Url | +
|---|---|---|---|---|
| twbs | +Bootstrap | +CSS | +78490 | +https://github.com/twbs/bootstrap | +
| vhf | +free-programming books | +- | +37240 | +https://github.com/vhf/free-programming-books | +
| angular | +angular.js | +JavaScript | +36,061 | +https://github.com/angular/angular.js | +
| mbostock | +d3 | +JavaScript | +35,257 | +https://github.com/mbostock/d3 | +
| joyent | +node | +JavaScript | +35,077 | +https://github.com/joyent/node | +
上面列出来的是前5的,看看大于1万个stars的项目的分布,一共有82个:
+| 语言 | +项目数 | +
|---|---|
| JavaScript | +37 | +
| Ruby | +6 | +
| CSS | +6 | +
| Python | +4 | +
| HTML | +3 | +
| C++ | +3 | +
| VimL | +2 | +
| Shell | +2 | +
| Go | +2 | +
| C | +2 | +
类型分布:
+-
+
- 库和框架: 和
jQuery
+ - 系统: 如
Linux、hhvm、docker
+ - 配置集: 如
dotfiles
+ - 辅助工具: 如
oh-my-zsh
+ - 工具: 如
Homewbrew和Bower
+ - 资料收集: 如
free programming books,You-Dont-Know-JS,Font-Awesome
+ - 其他:简历如
Resume
+
创建Pull Request
+第一个
+ const dgram = require('dgram')
+ - , coapPacket = require('coap-packet')
+ + , package = require('coap-packet')Google Ngx Pagespeed
+ else
+ cat << END
+ $0: error: module ngx_pagespeed requires the pagespeed optimization library.
+-Look in obj/autoconf.err for more details.
++Look in objs/autoconf.err for more details.
+ END
+ exit 1
+ fi创建你的项目
+构建Github项目
+创建项目文档
+测试
+重构
+Github 100天
+我也是蛮拼的,虽然我想的只是在Github上连击100~200天,然而到了今天也算不错。
+
在停地造轮子的过程中,也不停地造车子。
在那篇连续冲击365天的文章出现之前,我们公司的大大(https://github.com/dreamhead)也曾经在公司内部说过,天天commit什么的。当然这不是我的动力,在连击140天之前
+-
+
- 给过google的
ngx_speed、node-coap等项目创建过pull request
+ - 也有
free-programming-books、free-programming-books-zh_CN这样的项目。
+ - 当然还有一个连击20天。 +
对比了一下365天连击的commit,我发现我在total上整整多了近0.5倍。
+
同时这似乎也意味着,我每天的commit数与之相比多了很多。
+在连击20的时候,有这样的问题: 为了commit而commit代码,最后就放弃了。
+而现在是为了填坑而commit,为自己挖了太多的想法。
40天的提升
+当时我需要去印度接受毕业生培训,大概有5周左右,想着总不能空手而归。于是在国庆结束后有了第一次commit,当时旅游归来,想着自己在不同的地方有不同的照片,于是这个repo的名字是 onmap——将自己的照片显示在地图上的拍摄地点(手机是Lumia 920)。然而,中间因为修改账号的原因,丢失了commit。
+再从印度说起,当时主要维护三个repo:
+-
+
- 物联网的CoAP协议 +
- 一步步设计物联网系统的电子书 +
- 一个Node.js + JS的网站 +
说说最后一个,最后一个是练习的项目。因为当时培训比较无聊,业余时间比较多,英语不好,加上听不懂印度人的话。晚上基本上是在住的地方默默地写代码,所以当时的目标有这么几个:
+-
+
- TDD +
- 测试覆盖率 +
- 代码整洁 +
这也就是为什么那个repo有这样的一行:
+



做到98%的覆盖率也算蛮拼的,当然还有Code Climate也达到了4.0,也有了112个commits。因此也带来了一些提高:
+-
+
- 提高了代码的质量(code climate比jslint更注重重复代码等等一些bad smell)。 +
- 对于Mock、Stub、FakesServer等用法有更好的掌握 +
- 可以持续地交付软件(版本管理、自动测试、CI、部署等等) +
100天的挑战
+(ps:从印度回来之后,由于女朋友在泰国实习,有了更多的时间可以看书、写代码)
+有意思的是越到中间的一些时间,commits的次数上去了,除了一些简单的pull request,还有一些新的轮子出现了。
+
这是上一星期的commits,这也就意味着,在一星期里面,我需要在8个repo里切换。而现在我又有了一个新的idea,这时就发现了一堆的问题:
+-
+
- 今天工作在这个repo上,突然发现那个repo上有issue,需要去修复,于是就放下了当前的代码。 +
- 在不同的repo间切换容易分散精力 +
- 很容易就发现有太多的功能可以实现,但是时间是有限的。 +
- 没有足够的空闲时间,除了周末。 +
- 希望去寻找那些有兴趣的人,然而却发现原来没有那么多时间去找人。 +
140天的希冀
+在经历了100天之后,似乎整个人都轻松了,毕竟目标是100~200天。似乎到现在,也不会有什么特殊的情怀,除了一些希冀。
+当然,对于一个开源项目的作者来说,最好有下面的情况:
+-
+
- 很多人知道了这个项目 +
- 很多人用它的项目。 +
- 在某些可以用这个项目快速解决问题的地方提到了这个项目 +
- 提了bug、issue、问题。 +
- 提了bug,并解决了。(ps:这是最理想的情况) +
Github 200天Showcase
+今天是我连续泡在Github上的第200天,也是蛮高兴的,终于到达了:
+故事的背影是: 去年国庆完后要去印度接受毕业生培训——就是那个神奇的国度。但是在去之前已经在项目待了九个多月,项目上的挑战越来越少,在印度的时间又算是比较多。便给自己设定了一个长期的goal,即100~200天的longest streak。
+或许之前你看到过一篇文章让我们连击,那时已然140天,只是还是浑浑噩噩。到了今天,渐渐有了一个更清晰地思路。
+先让我们来一下ShowCase,然后再然后,下一篇我们再继续。
+一些项目简述
+上面说到的培训一开始是用Java写的一个网站,有自动测试、CI、CD等等。由于是内部组队培训,代码不能公开等等因素,加之做得无聊。顺手,拿Node.js +RESTify 做了Server,Backbone + RequireJS + jQuery 做了前台的逻辑。于是在那个日子里,也在维护一些旧的repo,如iot-coap、iot,前者是我拿到WebStorm开源License的Repo,后者则是毕业设计。
+对于这样一个项目也需要有测试、自动化测试、CI等等。CI用的是Travics-CI。总体的技术构架如下:
+技术栈
+前台:
+-
+
- Backbone +
- RequireJS +
- Underscore +
- Mustache +
- Pure CSS +
后台:
+-
+
- RESTify +
测试:
+-
+
- Jasmine +
- Chai +
- Sinon +
- Mocha +
- Jasmine-jQuery +
一直写到五星期的培训结束, 只是没有自动部署。想想就觉得可以用github-page的项目多好~~。
+过程中还有一些有意思的小项目,如:
+google map solr polygon 搜索
+ +代码: https://github.com/phodal/gmap-solr
+技能树
+这个可以从两部分说起:
+重构Skill Tree
+原来的是
+-
+
- Knockout +
- RequireJS +
- jQuery +
- Gulp +
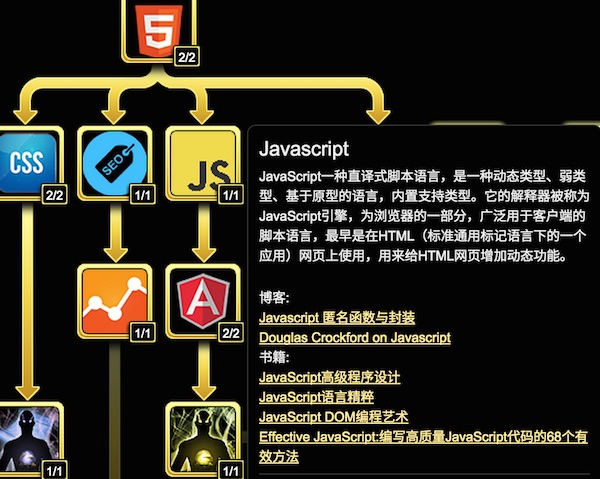
代码: https://github.com/phodal/skillock
+技能树Sherlock
+-
+
- D3.js +
- Dagre-D3.js +
- jquery.tooltipster.js +
- jQuery +
- Lettuce +
- Knockout.js +
- Require.js +
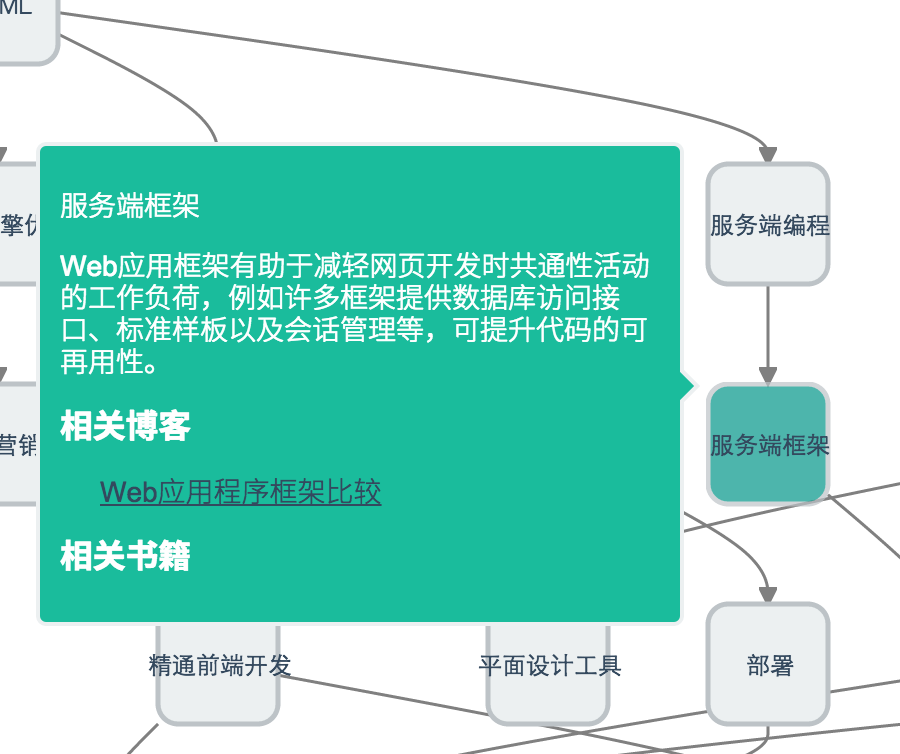
代码: https://github.com/phodal/sherlock
+Django Ionic ElasticSearch 地图搜索
+
-
+
- ElasticSearch +
- Django +
- Ionic +
- OpenLayers 3 +
代码: https://github.com/phodal/django-elasticsearch
+简历生成器
+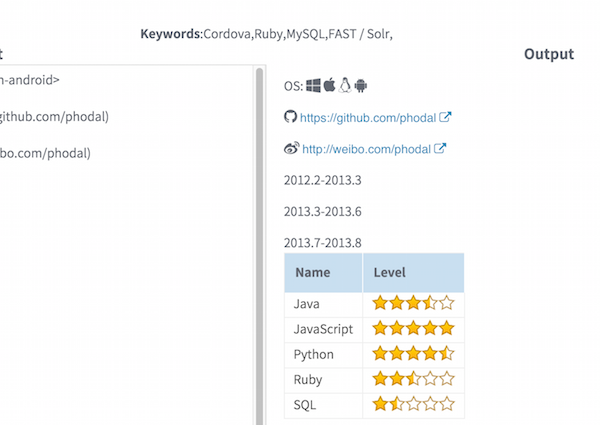
-
+
- React +
- jsPDF +
- jQuery +
- RequireJS +
- Showdown +
代码: https://github.com/phodal/resume
+Nginx 大数据学习
+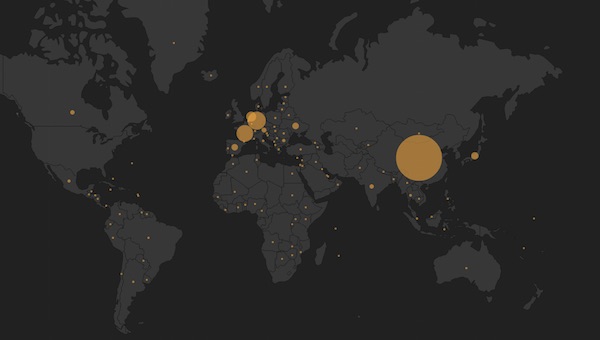
-
+
- ElasticSearch +
- Hadoop +
- Pig +
代码: https://github.com/phodal/learning-data/tree/master/nginx
+其他
+虽然技术栈上主要集中在Python、JavaScript,当然还有一些Ruby、Pig、Shell、Java的代码,只是我还是习惯用Python和JavaScript。一些用到觉得不错的框架:
+-
+
- Ionic: 开始Hybird移动应用。 +
- Django: Python Web开发利器。 +
- Flask: Python Web开发小刀。 +
- RequireJS: 管理js依赖。 +
- Backbone: Model + View + Router。 +
- Angluar: …。 +
- Knockout: MVV*。 +
- React: 据说会火。 +
- Cordova: Hybird应用基础。 +
还应该有:
+-
+
- ElasticSearch +
- Solr +
- Hadoop +
- Pig +
- MongoDB +
- Redis +
#Github 365天
+给你一年的时间,你会怎样去提高你的水平???
+
正值这难得的sick leave(万恶的空气),码文一篇来记念一个过去的366天里。尽管想的是在今年里写一个可持续的开源框架,但是到底这依赖于一个好的idea。在我的Github 孵化器 页面上似乎也没有一个特别让我满意的想法,虽然上面有各种不样有意思的ideas。多数都是在过去的一年是完成的,然而有一些也是还没有做到的。
+说说标题
+尽管一直在Github上连击看上去似乎是没有多大必要的,但是人总得有点追求。如果正是漫无目的,却又想着提高技术的同时,为什么不去试试?毕竟技术非常好、不需要太多练习的人只是少数,似乎这样的人是不存在的。大多数的人都是经过练习之后,才会达到别人口中的“技术好”。
+这让我想起了充斥着各种气味的知乎上的一些问题,在一些智商被完虐的话题里,无一不是因为那些人学得比别人早——哪来的天才?所谓的天才,应该是未来的智能生命一般,一出生什么都知道。如果并非如此,那只是说明他练习到位了。
+练习不到位便意味着,即使你练习的时候是一万小时的两倍,那也是无济于事的。如果你学得比别人晚,在很长的一段时间里(可能直到进棺材)输给别人是必然的——落后就要挨打。就好像我等毕业于一所二本垫底的学校里,如果在过去我一直保持着和别人(各种重点)一样的学习速度,那么我只能一直是Loser。
+需要注意的是,对你来说考上二本很难,并不是因为你比别人笨。教育资源分配不均的问题,在某种程度上导致了新的阶级制度的出现。如我的首页说的那样: THE ONLY FAIR IS NOT FAIR——唯一公平的是它是不公平的。我们可以做的还有很多——CREATE & SHARE。真正的不幸是,因为营养不良导致的教育问题。
+于是在想明白了很多事的时候起,便有了Re-Practise这样的计划,而365天只是中间的一个产物。
+编程的基础能力
+虽说算法很重要,但是编码才是基础能力。算法与编程在某种程度上是不同的领域,算法编程是在编程上面的一级。算法写得再好,如果别人很难直接拿来复用,在别人眼里就是shit。想出能work的代码一件简单的事,学会对其重构,使之变得更易读就是一件有意义的事。
+于是,在某一时刻在Github上创建了一个组织,叫Artisan Stack。当时想的是在Github寻找一些JavaScript项目,对其代码进行重构。但是到底是影响力不够哈,参与的人数比较少。
+重构
+如果你懂得如何写出高可读的代码,那么我想你是不需要这个的,但是这意味着你花了更多的时候在思考上了。当谈论重构的时候,让我想起了TDD(测试驱动开发)。即使不是TDD,那么如果你写着测试,那也是可以重构的。(之前写过一些利用Intellij IDEA重构的文章:提炼函数、以查询取代临时变量、重构与Intellij Idea初探、内联函数)
+在各种各样的文章里,我们看到过一些相关的内容,最好的参考莫过于《重构》一书。最基础不过的原则便是函数名,取名字很难,取别人能读懂的名字更难。其他的便有诸如长函数、过大的类、重复代码等等。在我有限的面试别人的经历里,这些问题都是最常见的。
+测试
+而如果没有测试,其他都是扯淡。写好测试很难,写个测试算是一件容易的事。只是有些容易我们会为了测试而测试。
+在我写EchoesWorks和Lan的过程中,我尽量去保证足够高的测试覆盖率。
+

从测试开始的TDD,会保证方法是可测的。从功能到测试则可以提供工作次效率,但是只会让测试成为测试,而不是代码的一部分。
+测试是代码的最后一公里。所以,尽可能的为你的Github上的项目添加测试。
+编码的过程
+初到TW时,Pair时候总会有人教我如何开始编码,这应该也是一项基础的能力。结合日常,重新演绎一下这个过程:
+-
+
- 有一个可衡量、可实现、过程可测的目标 +
- Tasking (即对要实现的目标过程进行分解) +
- 一步步实现 (如TDD) +
- 实现目标 +
放到当前的场景就是:
+-
+
- 我想在Github上连击365天。对应于每一个时候段的目标都应该是可以衡量、测试的——即每天都会有Contributions。 +
- 分解就是一个痛苦的过程。理想情况下,我们应该会有每天提交,但是这取决于你的repo的数量,如果没有新的idea出现,那么这个就变成为了Contributions而Commit。 +
- 一步步实现 +
在我们实际工作中也是如此,接到一个任务,然后分解,一步步完成。不过实现会稍微复杂一些,因为事务总会有抢占和优先级的。
+技术与框架设计
+在上上一篇博客中《After 500: 写了第500篇博客,然后呢?》也深刻地讨论了下这个问题,技术向来都是后发者优势。对于技术人员来说,也是如此,后发者占据很大的优势。
+如果我们只是单纯地把我们的关注点仅仅放置于技术上,那么我们就不具有任何的优势。而依赖于我们的编程经验,我们可以在特定的时候创造一些框架。而架构的设计本身就是一件有意思的事,大抵是因为程序员都喜欢创造。(ps:之前曾经写过这样一篇文章,《对不起,我并不热爱编程,我只喜欢创造》)
+创造是一种知识的再掌握过程。
+回顾一下写echoesworks的过程,一开始我需要的是一个网页版的PPT,当然这类的东西已经有很多了,如impress.js、bespoke.js等等。分析一下所需要的功能:markdown解析器、键盘事件处理、Ajax、进度条显示、图片处理、Slide。我们可以在Github上找到各式各样的模块,我们所要做的就是将之结合在一样。在那之前,我试着用类似的原理写(组合)了Lettuce。
+组合相比于创造过程是一个更有挑战性的过程,我们需要在这过程去设计胶水来粘合这些代码,并在最终可以让他工作。这好比是我们在平时接触到的任务划分,每个人负责相应的模块,最后整合。
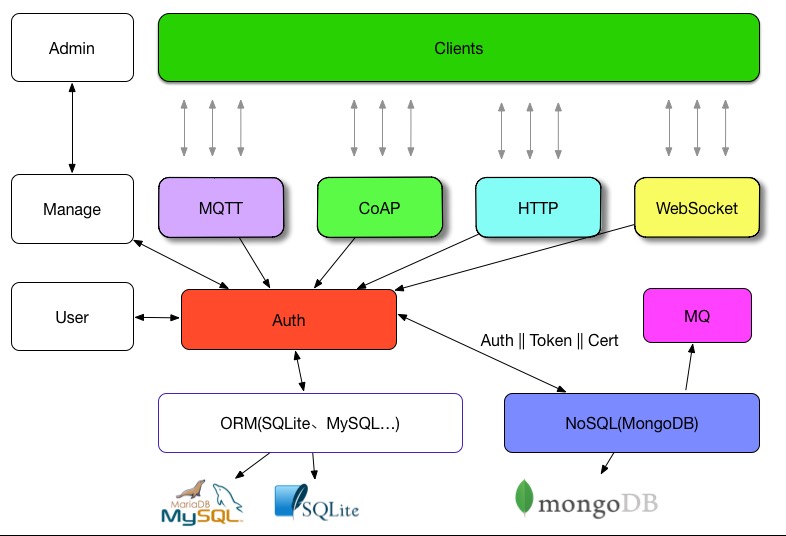
+想似的我在写lan的时候,也是类似的,但是不同的是我已经设计了一个清晰的架构图。
+
而在我们实现的编码过程也是如此,使用不同的框架,并且让他们能工作。如早期玩的moqi.mobi,基于Backbone、RequireJS、Underscore、Mustache、Pure CSS。在随后的时间里,用React替换了View层,就有了backbone-react的练习。
+技术同人一样,需要不断地往高一级前进。我们只需要不断地Re-Practise。
+领域与练习
+说业务好像不太适合程序员的口味,那就领域吧。不同行业的人,如百度、阿里、腾讯,他们的领域核心是不一样的。
+而领域本身也是相似的,这可以解释为什么互联网公司都喜欢互相挖人,而一般都不会去华为、中兴等非互联网领域挖人。出了这个领域,你可能连个毕业生都不如。领域、业务同技术一样是不断强化知识的一个过程。Ritchie先实现了BCPL语言,而后设计了C语言,而BCPL语言一开始是基于CPL语言。
+领域本身也在不断进化。
+这也是下一个值得提高的地方。
+其他
+是时候写这个小结了。从不会写代码,到写代码是从0到1的过程,但是要从1到60都不是一件容易的事。无论是刷Github也好(不要是自动提交),或者是换工作也好,我们都在不断地练习。
+而练习是要分成不同的几个步骤,不仅仅局限于技术:
+-
+
- 编码 +
- 架构 +
- 设计 +
- 。。。 +
如何在Github“寻找灵感(fork)”
+++重造轮子是重新创造一个已有的或是已被其他人优化的基本方法。
+
最近萌发了一个想法写游戏引擎,之前想着做一个JavaScript前端框架。看看,这个思路是怎么来的。
+一、Lettuce构建过程
+++Lettuce是一个简约的移动开发框架。
+
故事的出发点是这样的:写了很多代码,用的都是框架,最后不知道收获什么了?事实也是如此,当自己做了一些项目之后,发现最后什么也没有收获到。于是,就想着做一个框架。
需求
+有这样的几个前提
+-
+
- 为什么我只需要jQuery里的选择器、Ajax要引入那么重的库呢? +
- 为什么我只需要一个Template,却想着用Mustache +
- 为什么我需要一个Router,却要用Backbone呢? +
- 为什么我需要的是一个isObject函数,却要用到整个Underscore? +
我想要的只是一个简单的功能,而我不想引入一个庞大的库。换句话说,我只需要不同库里面的一小部分功能,而不是一个库。
+实际上想要的是:
+++构建一个库,里面从不同的库里面抽取出不同的函数。
+
计划
+这时候我参考了一本电子书《Build JavaScript FrameWork》,加上一些平时的需求,于是很快的就知道自己需要什么样的功能:
+-
+
- Promise 支持 +
- Class类(ps:没有一个好的类使用的方式) +
- Template 一个简单的模板引擎 +
- Router 用来控制页面的路由 +
- Ajax 基本的Ajax Get/Post请求 +
在做一些实际的项目中,还遇到了这样的一些功能支持:
+-
+
- Effect 简单的一些页面效果 +
- AMD支持 +
而我们有一个前提是要保持这个库尽可能的小、同时我们还需要有测试。
+实现第一个需求
+简单说说是如何实现一个简单的需求。
+生成框架
+因为Yeoman可以生成一个简单的轮廓,所以我们可以用它来生成这个项目的骨架。
+-
+
- Gulp +
- Jasmine +
寻找
+在Github上搜索了一个看到了下面的几个结果:
+-
+
- https://github.com/then/promise +
- https://github.com/reactphp/promise +
- https://github.com/kriskowal/q +
- https://github.com/petkaantonov/bluebird +
- https://github.com/cujojs/when +
但是显然,他们都太重了。事实上,对于一个库来说,80%的人只需要其中20%的代码。于是,找到了https://github.com/stackp/promisejs,看了看用法,这就是我们需要的功能:
+function late(n) {
+ var p = new promise.Promise();
+ setTimeout(function() {
+ p.done(null, n);
+ }, n);
+ return p;
+}
+
+late(100).then(
+ function(err, n) {
+ return late(n + 200);
+ }
+).then(
+ function(err, n) {
+ return late(n + 300);
+ }
+).then(
+ function(err, n) {
+ return late(n + 400);
+ }
+).then(
+ function(err, n) {
+ alert(n);
+ }
+);接着打开看看Promise对象,有我们需要的功能,但是又有一些功能超出我的需求。接着把自己不需要的需求去掉,这里函数最后就变成了
+function Promise() {
+ this._callbacks = [];
+}
+
+Promise.prototype.then = function(func, context) {
+ var p;
+ if (this._isdone) {
+ p = func.apply(context, this.result);
+ } else {
+ p = new Promise();
+ this._callbacks.push(function () {
+ var res = func.apply(context, arguments);
+ if (res && typeof res.then === 'function') {
+ res.then(p.done, p);
+ }
+ });
+ }
+ return p;
+};
+
+Promise.prototype.done = function() {
+ this.result = arguments;
+ this._isdone = true;
+ for (var i = 0; i < this._callbacks.length; i++) {
+ this._callbacks[i].apply(null, arguments);
+ }
+ this._callbacks = [];
+};
+
+var promise = {
+ Promise: Promise
+};需要注意的是: License,不同的软件有不同的License,如MIT、GPL等等。最好能在遵循协议的情况下,使用别人的代码。
实现第二个需求
+由于,现有的一些Ajax库都比较,最后只好参照着别人的代码自己实现。
+Lettuce.get = function (url, callback) {
+ Lettuce.send(url, 'GET', callback);
+};
+
+Lettuce.load = function (url, callback) {
+ Lettuce.send(url, 'GET', callback);
+};
+
+Lettuce.post = function (url, data, callback) {
+ Lettuce.send(url, 'POST', callback, data);
+};
+
+Lettuce.send = function (url, method, callback, data) {
+ data = data || null;
+ var request = new XMLHttpRequest();
+ if (callback instanceof Function) {
+ request.onreadystatechange = function () {
+ if (request.readyState === 4 && (request.status === 200 || request.status === 0)) {
+ callback(request.responseText);
+ }
+ };
+ }
+ request.open(method, url, true);
+ if (data instanceof Object) {
+ data = JSON.stringify(data);
+ request.setRequestHeader('Content-Type', 'application/json');
+ }
+ request.setRequestHeader('X-Requested-With', 'XMLHttpRequest');
+ request.send(data);
+};+
-
+
jQuery是一套跨浏览器的JavaScript库,简化HTML与JavaScript之间的操作。↩
+