diff --git a/chapters/03-analytics-01.md b/chapters/03-analytics-01.md
index 6957178..2509b6f 100644
--- a/chapters/03-analytics-01.md
+++ b/chapters/03-analytics-01.md
@@ -1 +1,243 @@
-#Github项目分析一
\ No newline at end of file
+#Github项目分析一
+
+#用matplotlib生成图表
+
+如何分析用户的数据是一个有趣的问题,特别是当我们有大量的数据的时候。
+除了``matlab``,我们还可以用``numpy``+``matplotlib``
+
+##python github用户数据分析##
+
+数据可以在这边寻找到
+
+[https://github.com/gmszone/ml](https://github.com/gmszone/ml)
+
+最后效果图
+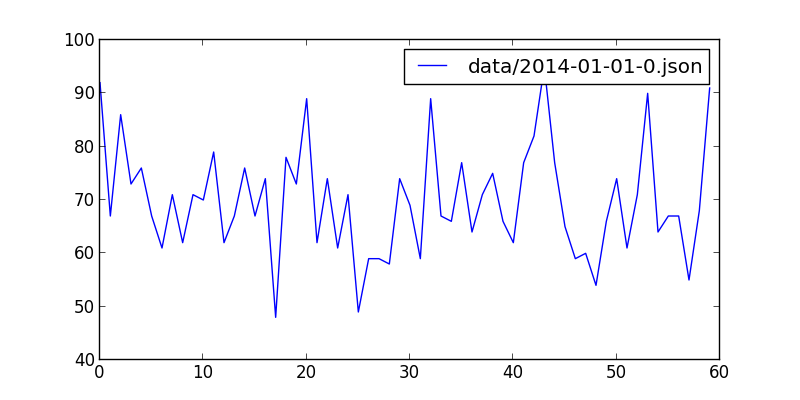 +
+要解析的json文件位于``data/2014-01-01-0.json``,大小6.6M,显然我们可能需要用每次只读一行的策略,这足以解释为什么诸如sublime打开的时候很慢,而现在我们只需要里面的json数据中的创建时间。。
+
+==
+ 这个文件代表什么?
+
+**2014年1月1日零时到一时,用户在github上的操作,这里的用户指的是很多。。一共有4814条数据,从commit、create到issues都有。**
+
+##python json文件解析##
+
+ import json
+ for line in open(jsonfile):
+ line = f.readline()
+
+然后再解析json
+
+
+要解析的json文件位于``data/2014-01-01-0.json``,大小6.6M,显然我们可能需要用每次只读一行的策略,这足以解释为什么诸如sublime打开的时候很慢,而现在我们只需要里面的json数据中的创建时间。。
+
+==
+ 这个文件代表什么?
+
+**2014年1月1日零时到一时,用户在github上的操作,这里的用户指的是很多。。一共有4814条数据,从commit、create到issues都有。**
+
+##python json文件解析##
+
+ import json
+ for line in open(jsonfile):
+ line = f.readline()
+
+然后再解析json
+
+import dateutil.parser
+
+lin = json.loads(line)
+date = dateutil.parser.parse(lin["created_at"])
+
+这里用到了``dateutil``,因为新鲜出炉的数据是string需要转换为``dateutil``,再到数据放到数组里头。最后有就有了``parse_data``
+
+def parse_data(jsonfile):
+ f = open(jsonfile, "r")
+ dataarray = []
+ datacount = 0
+
+ for line in open(jsonfile):
+ line = f.readline()
+ lin = json.loads(line)
+ date = dateutil.parser.parse(lin["created_at"])
+ datacount += 1
+ dataarray.append(date.minute)
+
+ minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]
+ f.close()
+ return minuteswithcount
+
+
+下面这句代码就是将上面的解析为
+
+ minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]
+
+这样的数组以便于解析
+
+ [(0, 92), (1, 67), (2, 86), (3, 73), (4, 76), (5, 67), (6, 61), (7, 71), (8, 62), (9, 71), (10, 70), (11, 79), (12, 62), (13, 67), (14, 76), (15, 67), (16, 74), (17, 48), (18, 78), (19, 73), (20, 89), (21, 62), (22, 74), (23, 61), (24, 71), (25, 49), (26, 59), (27, 59), (28, 58), (29, 74), (30, 69), (31, 59), (32, 89), (33, 67), (34, 66), (35, 77), (36, 64), (37, 71), (38, 75), (39, 66), (40, 62), (41, 77), (42, 82), (43, 95), (44, 77), (45, 65), (46, 59), (47, 60), (48, 54), (49, 66), (50, 74), (51, 61), (52, 71), (53, 90), (54, 64), (55, 67), (56, 67), (57, 55), (58, 68), (59, 91)]
+
+##matplotlib##
+开始之前需要安装``matplotlib
+
+ sudo pip install matplotlib
+
+然后引入这个库
+
+ import matplotlib.pyplot as plt
+
+如上面的那个结果,只需要
+
+
+ plt.figure(figsize=(8,4))
+ plt.plot(x, y,label = files)
+ plt.legend()
+ plt.show()
+
+
+最后代码可见
+
+ #!/usr/bin/env python
+ # -*- coding: utf-8 -*-
+
+ import json
+ import dateutil.parser
+ import numpy as np
+ import matplotlib.mlab as mlab
+ import matplotlib.pyplot as plt
+
+
+ def parse_data(jsonfile):
+ f = open(jsonfile, "r")
+ dataarray = []
+ datacount = 0
+
+ for line in open(jsonfile):
+ line = f.readline()
+ lin = json.loads(line)
+ date = dateutil.parser.parse(lin["created_at"])
+ datacount += 1
+ dataarray.append(date.minute)
+
+ minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]
+ f.close()
+ return minuteswithcount
+
+
+ def draw_date(files):
+ x = []
+ y = []
+ mwcs = parse_data(files)
+ for mwc in mwcs:
+ x.append(mwc[0])
+ y.append(mwc[1])
+
+ plt.figure(figsize=(8,4))
+ plt.plot(x, y,label = files)
+ plt.legend()
+ plt.show()
+
+ draw_date("data/2014-01-01-0.json")
+
+
+#每周分析
+
+继上篇之后,我们就可以分析用户的每周提交情况,以得出用户的真正的工具效率,每个程序员的工作时间可能是不一样的,如
+![Phodal Huang's Report][1]
+
+ [1]: https://www.phodal.com/static/media/uploads/screen_shot_2014-04-12_at_9.58.52_am.png
+
+这是我的每周情况,显然如果把星期六移到前面的话,随着工作时间的增长,在github上的使用在下降,作为一个
+
+ a fulltime hacker who works best in the evening (around 8 pm).
+
+不过这个是osrc的分析结果。
+
+##python github 每周情况分析##
+
+看一张分析后的结果
+
+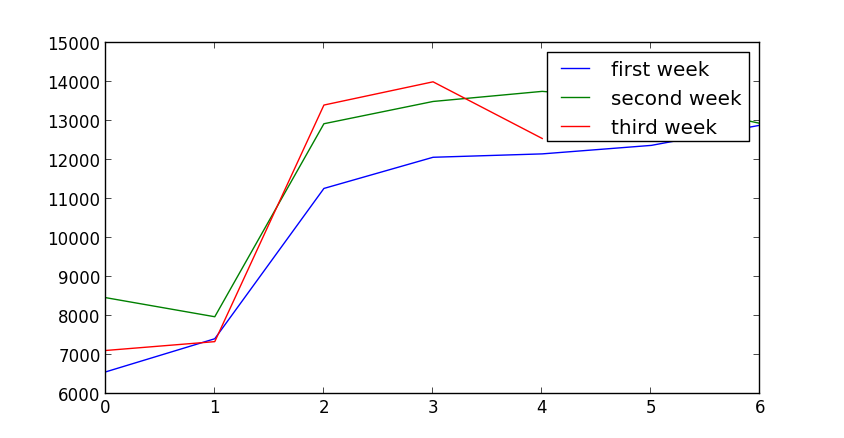 +
+结果正好与我的情况相反?似乎图上是这么说的,但是数据上是这样的情况。
+
+ data
+ ├── 2014-01-01-0.json
+ ├── 2014-02-01-0.json
+ ├── 2014-02-02-0.json
+ ├── 2014-02-03-0.json
+ ├── 2014-02-04-0.json
+ ├── 2014-02-05-0.json
+ ├── 2014-02-06-0.json
+ ├── 2014-02-07-0.json
+ ├── 2014-02-08-0.json
+ ├── 2014-02-09-0.json
+ ├── 2014-02-10-0.json
+ ├── 2014-02-11-0.json
+ ├── 2014-02-12-0.json
+ ├── 2014-02-13-0.json
+ ├── 2014-02-14-0.json
+ ├── 2014-02-15-0.json
+ ├── 2014-02-16-0.json
+ ├── 2014-02-17-0.json
+ ├── 2014-02-18-0.json
+ ├── 2014-02-19-0.json
+ └── 2014-02-20-0.json
+
+我们获取是每天晚上0点时的情况,至于为什么是0点,我想这里的数据量可能会比较少。除去1月1号的情况,就是上面的结果,在只有一周的情况时,总会以为因为在国内那时是假期,但是总觉得不是很靠谱,国内的程序员虽然很多,会在github上活跃的可能没有那么多,直至列出每一周的数据时。
+
+ 6570, 7420, 11274, 12073, 12160, 12378, 12897,
+ 8474, 7984, 12933, 13504, 13763, 13544, 12940,
+ 7119, 7346, 13412, 14008, 12555
+
+##python 数据分析##
+
+重写了一个新的方法用于计算提交数,直至后面才意识到其实我们可以算行数就够了,但是方法上有点hack
+
+
+
+结果正好与我的情况相反?似乎图上是这么说的,但是数据上是这样的情况。
+
+ data
+ ├── 2014-01-01-0.json
+ ├── 2014-02-01-0.json
+ ├── 2014-02-02-0.json
+ ├── 2014-02-03-0.json
+ ├── 2014-02-04-0.json
+ ├── 2014-02-05-0.json
+ ├── 2014-02-06-0.json
+ ├── 2014-02-07-0.json
+ ├── 2014-02-08-0.json
+ ├── 2014-02-09-0.json
+ ├── 2014-02-10-0.json
+ ├── 2014-02-11-0.json
+ ├── 2014-02-12-0.json
+ ├── 2014-02-13-0.json
+ ├── 2014-02-14-0.json
+ ├── 2014-02-15-0.json
+ ├── 2014-02-16-0.json
+ ├── 2014-02-17-0.json
+ ├── 2014-02-18-0.json
+ ├── 2014-02-19-0.json
+ └── 2014-02-20-0.json
+
+我们获取是每天晚上0点时的情况,至于为什么是0点,我想这里的数据量可能会比较少。除去1月1号的情况,就是上面的结果,在只有一周的情况时,总会以为因为在国内那时是假期,但是总觉得不是很靠谱,国内的程序员虽然很多,会在github上活跃的可能没有那么多,直至列出每一周的数据时。
+
+ 6570, 7420, 11274, 12073, 12160, 12378, 12897,
+ 8474, 7984, 12933, 13504, 13763, 13544, 12940,
+ 7119, 7346, 13412, 14008, 12555
+
+##python 数据分析##
+
+重写了一个新的方法用于计算提交数,直至后面才意识到其实我们可以算行数就够了,但是方法上有点hack
+
+
+ def get_minutes_counts_with_id(jsonfile):
+ datacount, dataarray = handle_json(jsonfile)
+ minuteswithcount = [(x, dataarray.count(x)) for x in set(dataarray)]
+ return minuteswithcount
+
+
+ def handle_json(jsonfile):
+ f = open(jsonfile, "r")
+ dataarray = []
+ datacount = 0
+
+ for line in open(jsonfile):
+ line = f.readline()
+ lin = json.loads(line)
+ date = dateutil.parser.parse(lin["created_at"])
+ datacount += 1
+ dataarray.append(date.minute)
+
+ f.close()
+ return datacount, dataarray
+
+
+ def get_minutes_count_num(jsonfile):
+ datacount, dataarray = handle_json(jsonfile)
+ return datacount
+
+
+ def get_month_total():
+ """
+
+ :rtype : object
+ """
+ monthdaycount = []
+ for i in range(1, 20):
+ if i < 10:
+ filename = 'data/2014-02-0' + i.__str__() + '-0.json'
+ else:
+ filename = 'data/2014-02-' + i.__str__() + '-0.json'
+ monthdaycount.append(get_minutes_count_num(filename))
+ return monthdaycount
+
+接着我们需要去遍历每个结果,后面的后面会发现这个效率真的是太低了,为什么木有多线程?
+
+##python matplotlib图表##
+让我们的matplotlib来做这些图表的工作
+
+ if __name__ == '__main__':
+ results = pd.get_month_total()
+ print results
+
+ plt.figure(figsize=(8, 4))
+ plt.plot(results.__getslice__(0, 7), label="first week")
+ plt.plot(results.__getslice__(7, 14), label="second week")
+ plt.plot(results.__getslice__(14, 21), label="third week")
+ plt.legend()
+ plt.show()
+
+蓝色的是第一周,绿色的是第二周,蓝色的是第三周就有了上面的结果。
+
+我们还需要优化方法,以及多线程的支持。
+
+